Command Palette
Search for a command to run...
Dommages cérébraux maximaux sans données ni optimisation : perturber les Neural Networks via des flips de sign-bit.
Dommages cérébraux maximaux sans données ni optimisation : perturber les Neural Networks via des flips de sign-bit.
Ido Galil Moshe Kimhi Ran El-Yaniv
Résumé
Voici la traduction de votre texte en français, en respectant scrupuleusement les standards de rédaction scientifique et technologique :Les réseaux de neurones profonds (Deep Neural Networks - DNNs) peuvent subir des perturbations catastrophiques par le simple basculement (flipping) de quelques bits de paramètres seulement. Nous introduisons le Deep Neural Lesion (DNL), une méthode sans données (data-free) et sans optimisation (optimization-free) qui permet de localiser les paramètres critiques, ainsi qu'une variante améliorée à passage unique, le 1P-DNL, qui affine cette sélection grâce à un seul passage avant (forward pass) et arrière (backward pass) sur des entrées aléatoires.Nous démontrons que cette vulnérabilité s'étend à de multiples domaines, notamment la classification d'images, la détection d'objets, la segmentation d'instances et le raisonnement des grands modèles de langage (Large Language Models - LLMs). Dans le cadre de la classification d'images, le basculement de seulement deux bits de signe dans un ResNet-50 sur ImageNet réduit la précision de 99,8 %. Pour la détection d'objets et la segmentation d'instances, un ou deux basculements de signe dans le backbone provoquent l'effondrement de la détection COCO et de la mask AP pour les modèles Mask R-CNN et YOLOv8-seg. En modélisation du langage, deux basculements de signe vers différents experts font chuter la précision de Qwen3-30B-A3B-Thinking de 78 % à 0 %. Nous démontrons également que la protection sélective d'une petite fraction de bits de signe vulnérables constitue une défense pratique contre de telles attaques.
One-sentence Summary
By introducing Deep Neural Lesion (DNL) and its single-pass variant 1P-DNL, the authors present a data-free and optimization-free method to disrupt neural networks via sign-bit flips that achieves catastrophic failure in image classification, object detection, and large language models while offering a practical defense through selective bit protection.
Key Contributions
- The paper introduces Deep Neural Lesion (DNL), a data-free and optimization-free method for locating critical parameters, along with an enhanced single-pass variant called 1P-DNL that refines parameter selection using one forward and backward pass on random inputs.
- This work demonstrates that flipping a minimal number of sign bits can catastrophically disrupt diverse architectures, including ResNet-50 on ImageNet, Mask R-CNN and YOLOv8-seg on COCO, and reasoning large language models like Qwen3-30B-A3B-Thinking.
- The authors propose a targeted defense mechanism that selectively protects a small fraction of vulnerable sign bits to substantially improve model robustness against these bit-flip attacks.
Introduction
As deep neural networks (DNNs) are increasingly deployed in safety-critical systems like autonomous driving and large language models, understanding their vulnerability to hardware and software exploits is essential. While existing weight-space attacks can disrupt models, they typically require significant computational overhead, iterative optimization, or access to large datasets to compute gradients.
The authors introduce Deep Neural Lesion (DNL), a lightweight, data-agnostic, and optimization-free method that identifies and flips critical sign bits to induce catastrophic model failure. By leveraging a magnitude-based heuristic and an enhanced single-pass variant (1P-DNL), the authors demonstrate that flipping as few as one or two sign bits can reduce the accuracy of ResNet-50, YOLOv8, and Mixture-of-Experts language models to near zero. This approach bypasses the need for training data or continuous inference, making it a highly stealthy and potent threat in real-world deployment scenarios.
Method
The authors leverage a targeted sign-bit flipping attack, termed DNL (Deep Neural Lesion), to expose critical vulnerabilities in deep neural networks (DNNs) by demonstrating that flipping a small number of specific sign bits can catastrophically degrade model performance. The attack is entirely data-agnostic, requiring no knowledge of training data, domain-specific inputs, or synthetic data. The framework is designed to identify and manipulate the most critical parameters within a model's weight space, focusing on the sign bit (MSB) of the floating-point representation, which induces an immediate and often severe change in a parameter's value. This approach is motivated by the observation that while random sign-bit flips have negligible impact on performance, strategically selected flips can lead to drastic accuracy reductions.
The core of the DNL attack involves two primary strategies: a "Pass-free" variant and a "1-Pass" variant. The Pass-free attack operates without any additional computational passes beyond the model's forward computation. It relies on a simple, heuristic-based selection of parameters to flip. The authors first identify that parameters with large magnitudes are disproportionately sensitive to sign flips, drawing an analogy to magnitude-based pruning in the literature. This leads to a magnitude-based strategy where the top-k largest parameters in absolute value are selected for flipping. Furthermore, for convolutional neural networks (CNNs), the attack is constrained to flip at most one sign bit per convolutional kernel. This constraint is crucial because flipping multiple bits within the same kernel often results in partial cancellation of the perturbation, reducing the overall impact. This is illustrated in the figure below, where a single sign flip in a Sobel filter severely disrupts its edge-detection capability, whereas two sign flips can partially offset the damage, allowing the filter to retain some functionality.
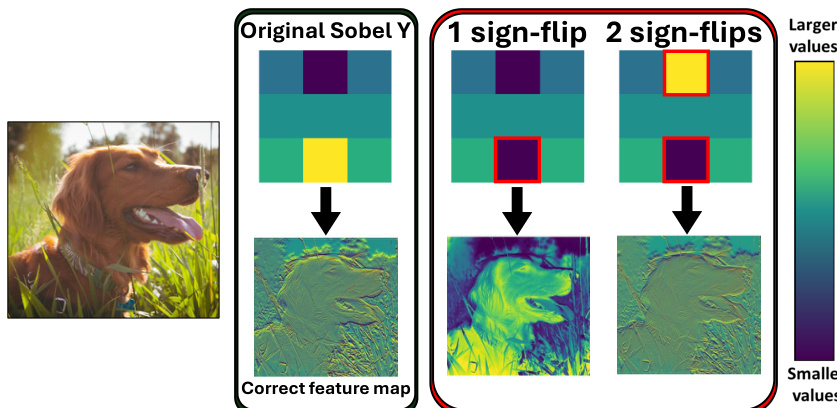
The attack's effectiveness is further enhanced by targeting parameters in the early layers of the network. The authors argue that early-layer parameters, particularly in CNNs, are critical for extracting fundamental features such as edges and textures. A perturbation in these layers propagates through the entire network, causing compounding errors that lead to severe performance degradation. This is analogous to early lesions in the visual system causing total blindness. The figure below provides a visual demonstration of this concept, showing how flipping the sign bit of a weight in the first convolutional kernel of a DNN leads to a large disruption in the learned feature maps, rendering the network unable to correctly detect edges.

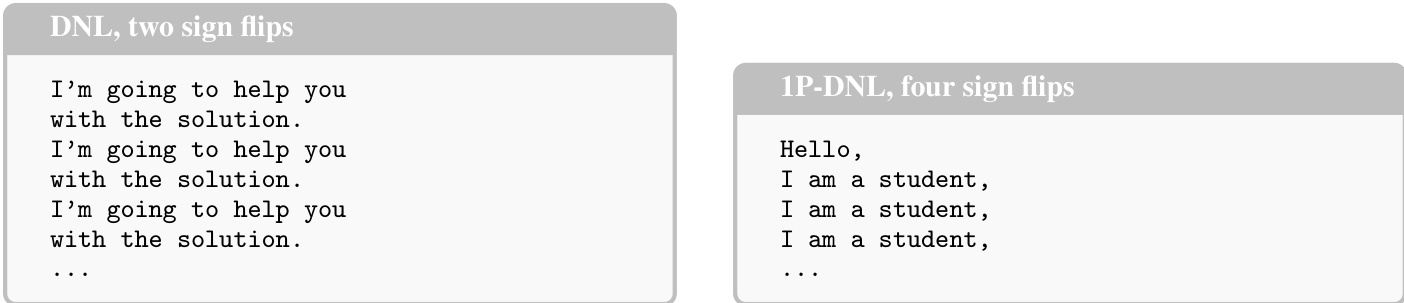
To refine the attack under a limited computational budget, the authors propose the 1P-DNL (1-Pass DNL) variant, which uses a single forward and backward pass with random inputs to compute a more sophisticated importance score for each parameter. This score, termed a hybrid importance score, combines magnitude-based saliency with second-order information derived from the model's gradients and Hessian. The formula for this score is defined as S(θi)=α∣θi∣+β∂θi∂Rθi+21Hiiθi2+∑j=iHijθiθj, where R is the model's loss or output on a random input. In practice, the Hessian is approximated diagonally, and Hii is replaced by (∂θi∂R)2 for computational efficiency. This approach allows the attack to identify parameters that are most sensitive to perturbations, not just those with the largest magnitude. The results, visualized in the figure below, show that this enhanced method is significantly more potent than the pass-free version, with both DNL and 1P-DNL causing most models to collapse under a small number of flips.
Experiment
The researchers evaluate the effectiveness of DNL and 1P-DNL bit-flip attacks across diverse domains, including reasoning language models, text encoders, image classification, and object detection. The experiments demonstrate that targeted sign-bit flips can cause rapid model collapse, often reducing performance to near zero with only a few perturbations. These findings reveal a fundamental vulnerability in neural network representations that persists regardless of model scale or architecture, while also suggesting that selectively protecting high-impact parameters can serve as an effective defense.
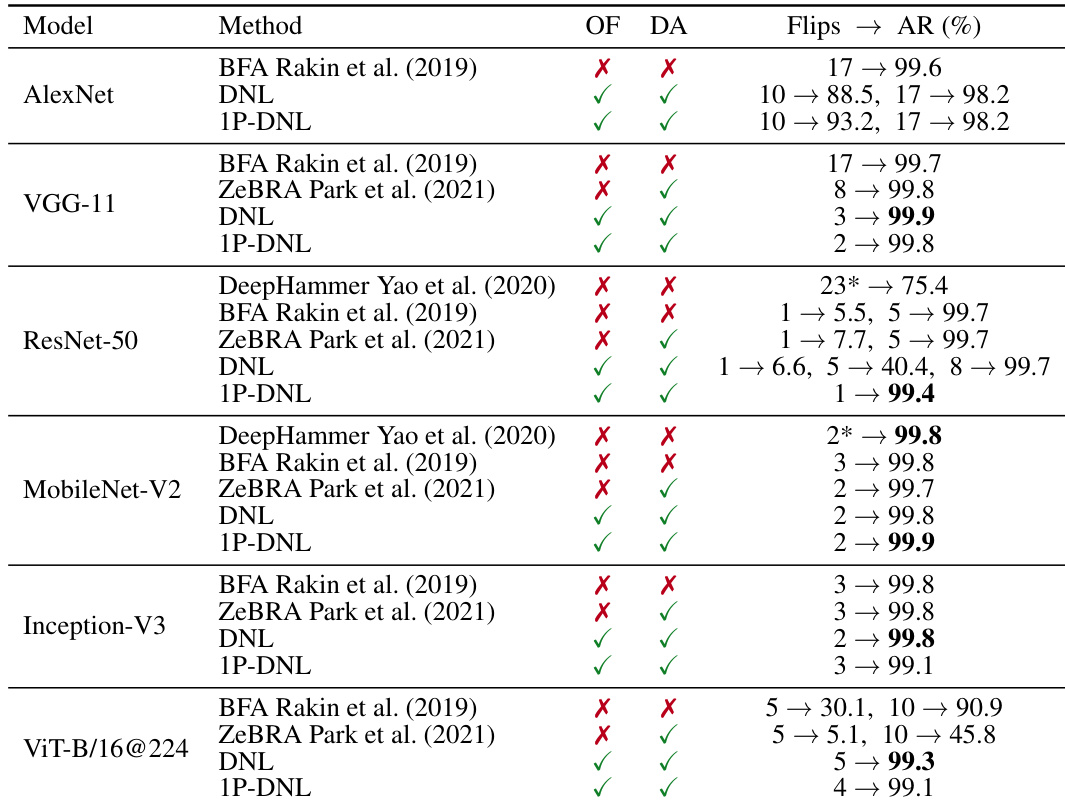
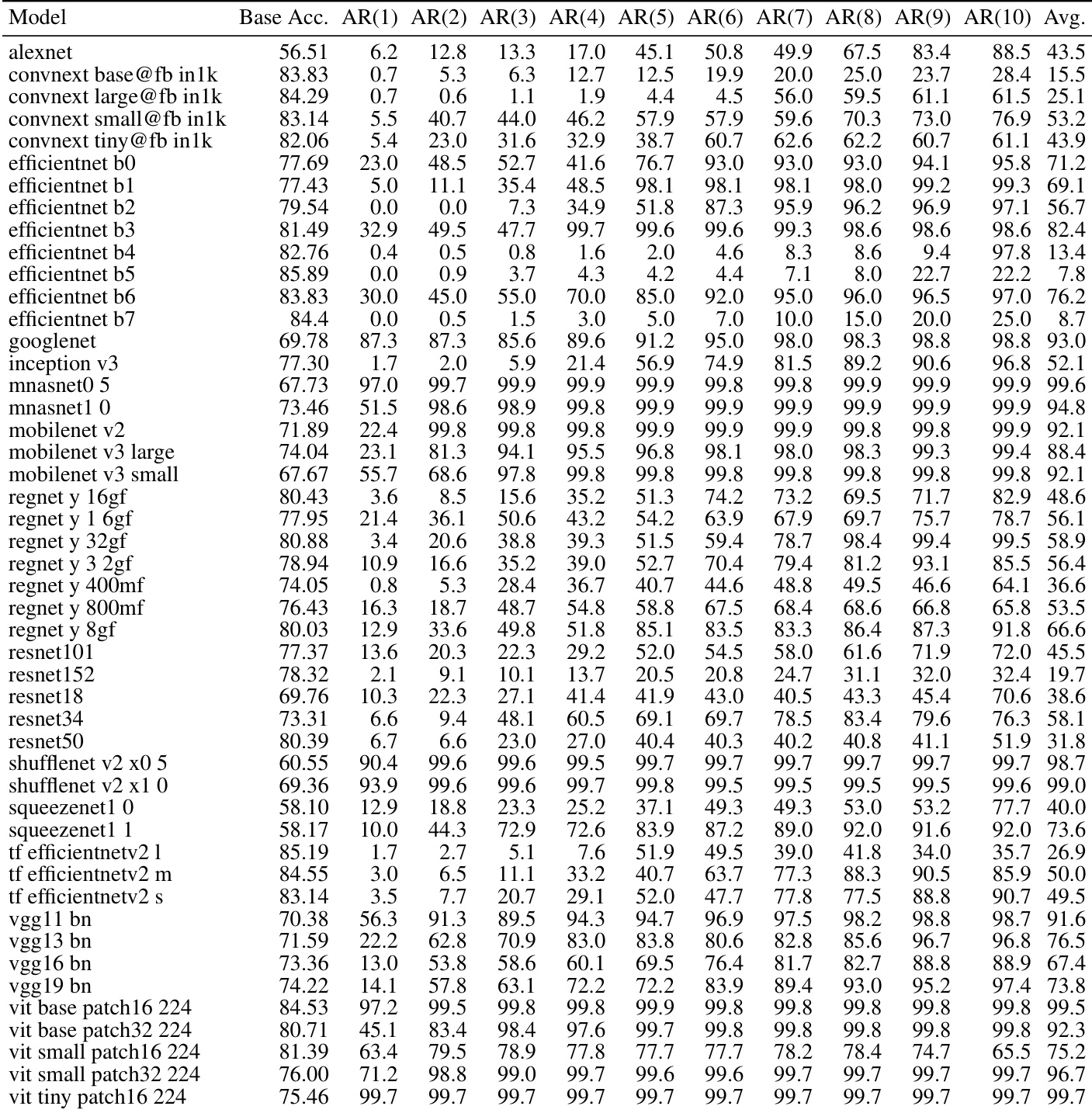
The the the table compares different bit-flip attack methods across multiple models, showing that DNL and 1P-DNL achieve high accuracy reduction with few flips. These methods are optimization-free and data-agnostic, outperforming others in effectiveness and efficiency. DNL and 1P-DNL achieve high accuracy reduction with minimal flips across various models. The attacks are optimization-free and data-agnostic, making them more efficient than other methods. 1P-DNL consistently outperforms DNL, achieving near-complete collapse with fewer flips.
The authors evaluate targeted sign-bit attacks on image classification models across multiple datasets and architectures. Results show that a small number of carefully selected bit flips lead to rapid and severe accuracy degradation, with most models collapsing to near-zero performance after a few flips. The attack is effective across different model types and datasets, indicating a fundamental vulnerability in deep neural network representations. A single targeted sign-bit flip causes significant accuracy reduction in image models. Most models collapse to near-zero accuracy after only a few sign-bit flips. The attack is effective across diverse architectures and datasets, indicating a general vulnerability.

The authors evaluate targeted sign-bit attacks on various image classification models, showing that a small number of carefully selected parameter flips lead to rapid accuracy collapse across multiple architectures. The results demonstrate consistent vulnerability regardless of model size or type, with most models experiencing severe degradation after just a few flips. A small number of targeted sign-bit flips cause rapid accuracy collapse across diverse image classification models Attack effectiveness is consistent across different model architectures and sizes Most models show severe degradation after only a few flips, indicating fundamental vulnerability
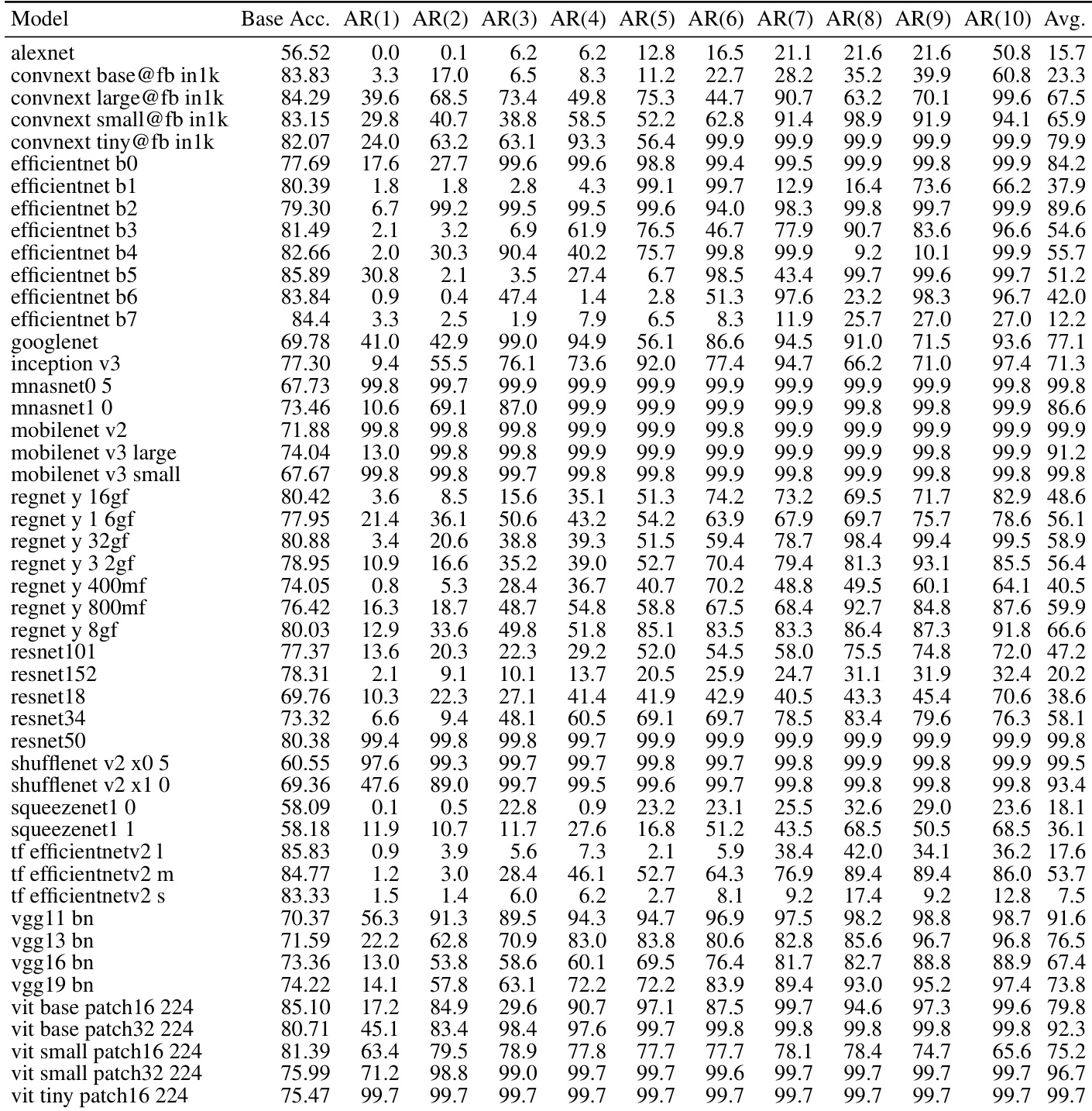
The authors evaluate targeted sign-bit attacks on a range of image classification models, showing that a small number of carefully selected parameter flips can cause severe accuracy degradation. The results demonstrate consistent vulnerability across diverse architectures, with most models collapsing to near-zero accuracy after only a few flips. Targeted sign-bit attacks cause rapid and severe accuracy reduction across diverse image models Most models exhibit near-complete collapse with fewer than 10 parameter flips The attack is effective regardless of model architecture, size, or design choices
The authors evaluate targeted sign-bit attacks on image classification models across multiple datasets, showing that a small number of carefully selected bit flips cause rapid and severe accuracy reduction. The attack is effective across different models and datasets, with performance collapsing sharply after just a few flips. A few targeted sign-bit flips cause rapid collapse in image classification accuracy across multiple datasets. The attack is effective on various models, with performance dropping sharply after only a few flips. Different datasets show similar vulnerability patterns, indicating a general weakness in model representations.
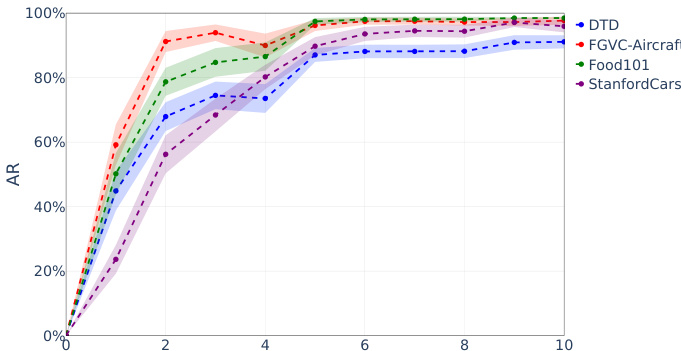
The experiments evaluate various bit-flip attack methods, specifically focusing on targeted sign-bit attacks, across diverse image classification architectures and datasets. The results demonstrate that optimization-free and data-agnostic methods like 1P-DNL can cause rapid and severe accuracy collapse with only a minimal number of flips. This consistent vulnerability across different model sizes and designs indicates a fundamental weakness in deep neural network representations.