Command Palette
Search for a command to run...
Meta Audiobox Aesthetics : Évaluation automatisée unifiée de la qualité pour la parole, la musique et les sons
Meta Audiobox Aesthetics : Évaluation automatisée unifiée de la qualité pour la parole, la musique et les sons
Résumé
La quantification de l’esthétique audio demeure un défi complexe en traitement du signal audio, principalement en raison de sa nature subjective, influencée par la perception humaine et le contexte culturel. Les méthodes traditionnelles s’appuient souvent sur des juges humains pour l’évaluation, ce qui entraîne des incohérences et des coûts élevés en ressources. Ce papier répond à un besoin croissant en systèmes automatisés capables de prédire l’esthétique audio sans intervention humaine. De tels systèmes sont essentiels pour des applications telles que le filtrage de données, l’étiquetage pseudo-labeling de grands jeux de données, ou l’évaluation des modèles audio génératifs, particulièrement à mesure que ces derniers gagnent en sophistication. Dans ce travail, nous proposons une nouvelle approche d’évaluation esthétique audio en introduisant de nouvelles lignes directrices d’annotation qui décomposent les perspectives d’écoute humaine en quatre axes distincts. Nous développons et entraînons des modèles de prédiction sans référence (no-reference), spécifiques à chaque élément, offrant une évaluation plus fine de la qualité audio. Nos modèles sont évalués par rapport aux scores moyens d’opinion humaine (MOS) et aux méthodes existantes, démontrant des performances comparables ou supérieures. Cette recherche contribue non seulement au progrès du domaine de l’esthétique audio, mais fournit également des modèles et jeux de données open-source pour faciliter les travaux futurs et les comparaisons standardisées. Nous mettons à disposition notre code et notre modèle pré-entraîné à l’adresse suivante : https://github.com/facebookresearch/audiobox-aesthetics
One-sentence Summary
The authors from FAIR and Reality Labs at Meta propose Audiobox-Aesthetics, a novel no-reference, per-item prediction framework that decomposes audio aesthetic quality into four distinct axes—Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness—using a Transformer-based architecture trained on a diverse, open-sourced dataset. By decoupling subjective and technical dimensions, the model enables more nuanced, domain-agnostic evaluation than traditional MOS-based methods, outperforming existing predictors in both speech and cross-modal scenarios while supporting applications in data filtering, pseudo-labeling, and generative audio evaluation.
Key Contributions
-
The paper addresses the challenge of subjective and inconsistent audio quality evaluation by introducing a new annotation framework that decomposes human listening perspectives into four distinct, interpretable axes: Production Quality, Production Complexity, Content Enjoyment, and Aesthetic Appeal, enabling more nuanced and reliable assessment across diverse audio types.
-
It proposes a unified, no-reference, per-item prediction model (Audiobox-Aesthetics) trained on a diverse dataset of speech, music, and sound, leveraging self-supervised representations to achieve robust, domain-agnostic audio aesthetic evaluation without requiring reference audio or human annotations during inference.
-
Evaluated against human mean opinion scores (MOS) and existing methods on the released AES-Natural dataset, the model demonstrates comparable or superior performance, with extensive ablation studies confirming the effectiveness of the multi-axis annotation scheme in reducing bias and improving interpretability over traditional single-score metrics.
Introduction
The authors address the challenge of automated audio aesthetic assessment, which is critical for applications like data filtering, pseudo-labeling, and evaluating generative audio models—especially as these models grow more complex and lack ground-truth references. Prior methods rely heavily on human judgments or domain-specific metrics like PESQ, POLQA, or FAD, which suffer from high annotation costs, limited generalization, or inability to capture fine-grained perceptual dimensions. Moreover, traditional Mean Opinion Scores (MOS) conflate multiple subjective aspects, leading to ambiguous and biased evaluations. To overcome these limitations, the authors introduce a unified framework based on four distinct aesthetic axes: Production Quality (technical fidelity), Production Complexity (audio scene richness), Content Enjoyment (emotional and artistic impact), and Content Usefulness (practical utility for creators). They develop no-reference, per-item prediction models trained on a diverse dataset (AES-Natural) annotated using these axes, demonstrating superior or comparable performance to human ratings. The approach enables more interpretable, scalable, and cross-domain audio quality assessment, with open-source models and data released to advance future research.
Dataset
- The dataset comprises approximately 97,000 audio samples across three modalities—speech, sound effects, and music—collected from a curated super-set of open-source and licensed datasets to ensure real-world representativeness.
- Audio samples are evenly split between speech and music, with most lasting between 10 and 30 seconds. The dataset includes diverse sources:
- Speech: Main and out-of-domain test sets from VMC22 (Huang et al., 2022), including English utterances from BVCC (natural, TTS, and voice conversion samples) and Chinese TTS and natural speech from Blizzard Challenge 2019.
- Sound and music: 500 sound and 500 music samples from the PAM dataset (Deshmukh et al., 2023), consisting of 100 natural and 400 text-to-sound/music samples generated by various models.
- To ensure balanced representation, stratified sampling is applied using metadata such as speaker ID, genre, and demographics. Audio modalities are shuffled during annotation to enable unified scoring across domains.
- All audio undergoes loudness normalization to mitigate volume-related biases.
- Each audio sample receives three independent ratings from human annotators to reduce variance.
- Raters are selected via a qualification process using a golden set labeled by experts. Only raters with Pearson correlation > 0.7 against ground truth on objective axes (production quality and complexity) are onboarded, resulting in a pool of 158 diverse raters.
- Annotation focuses on four aesthetic axes: Perceptual Quality (PQ), Complexity (CE), Usefulness (CU), and Production Complexity (PC), rated on a 1–10 scale. Detailed guidelines and audio examples with score benchmarks are provided to standardize evaluation.
- The authors use the dataset to train a multi-axis aesthetic score predictor, with training data split across modalities and balanced across the four axes. Mixture ratios are adjusted to ensure robustness across speech, sound, and music.
- During training, audio is processed with consistent preprocessing (e.g., loudness normalization), and for text-to-audio generation tasks, audio is chunked into 10-second segments.
- Metadata is constructed during annotation, including modality classification (speech, music, sound, ambient) and production complexity ratings.
- The dataset supports both in-domain and out-of-domain evaluation, with strong performance observed on VMC22’s OOD Chinese speech test set despite training primarily on English data.
- Correlation analysis (Figure 2) shows low inter-axis correlation, confirming the value of decoupling aesthetic dimensions.
- The dataset enables evaluation of model-generated audio via human-annotated ground truth and predicted scores, with high consistency between human and model predictions on relevant axes.
Method
The authors leverage a Transformer-based architecture for their aesthetic score predictor model, Audiobox-Aesthetics, which processes audio inputs to predict scores across four distinct axes: production quality, production complexity, content enjoyment, and content usefulness. The model begins with an input waveform sampled at 16kHz, which is first processed by a CNN encoder to extract initial features. These features are then fed into a Transformers encoder, consisting of 12 layers with 768 hidden dimensions, based on the WavLM architecture. The encoder generates a sequence of hidden states hl,t∈Rd, where d is the hidden size, across L layers and T timesteps. To obtain a consolidated audio embedding e∈Rd, the model computes a weighted average of the hidden states across layers and timesteps, using learnable weights wl. The embedding is derived as:
zl=∑l=1Lwlwl e^=t=1∑Tl=1∑LThl,tzl e=∥e^∥2e^This normalized embedding e is then passed through multiple multi-layer perceptron (MLP) blocks, each composed of linear layers, layer normalization, and GeLU activation functions. The final output consists of predicted aesthetic scores Y^={y^PQ,y^PC,y^CE,y^CU} for the four axes. The model is trained by minimizing a combined loss function that includes both mean-absolute error (MAE) and mean squared error (MSE) terms:
L=a∈{PQ,PC,CE,CU}∑(ya−y^a)2+∣ya−y^a∣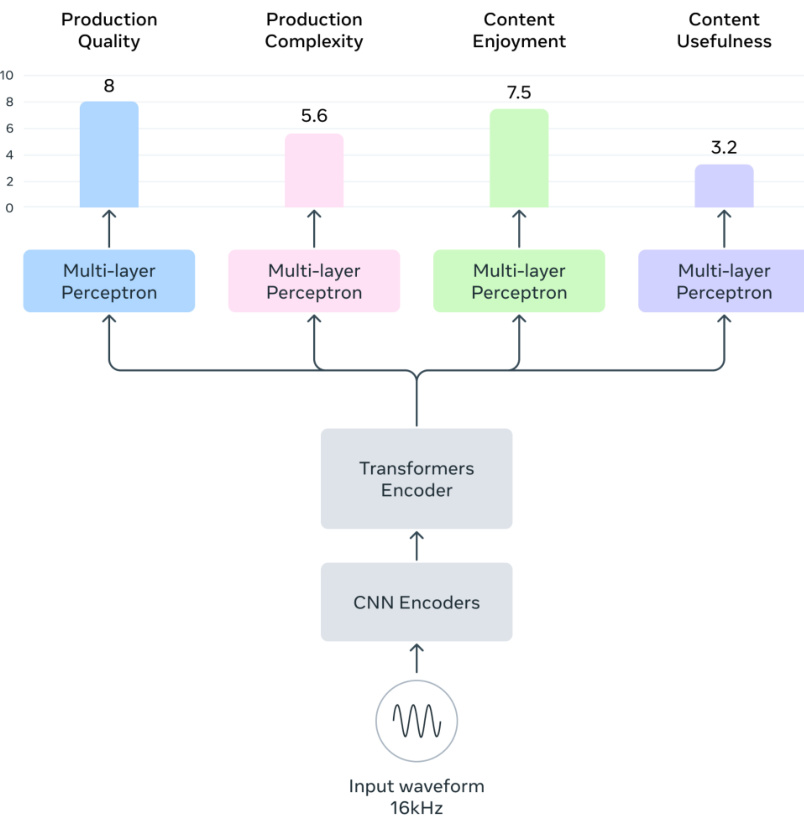
Experiment
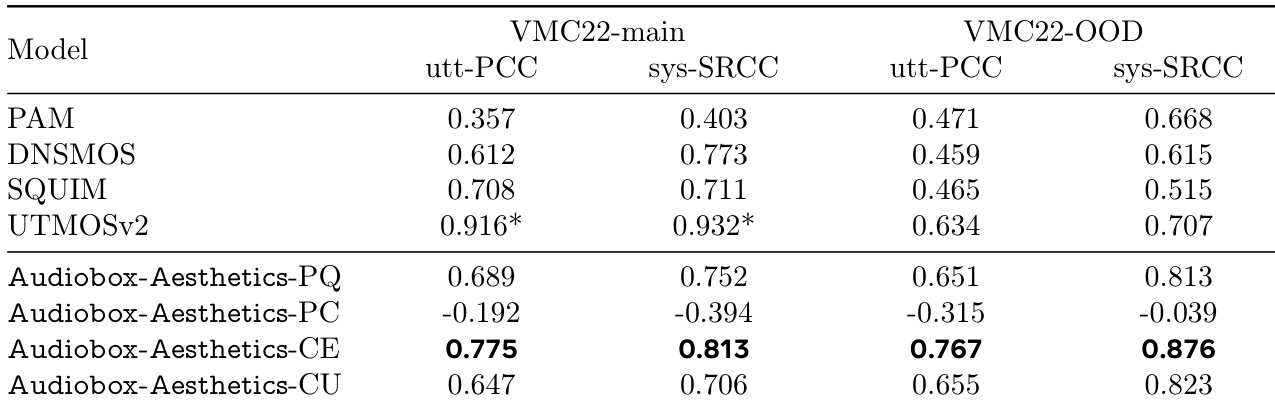
- Evaluated four AES predictors (Audiobox-Aesthetics-PQ, PC, CE, CU) on speech and general audio quality, with P.808 MOS (DNSMOS), SQUIM-PESQ, UTMOSv2, and PAM as baselines; Audiobox-Aesthetics-PQ achieved 0.91 utterance-level Pearson correlation on speech test set, surpassing UTMOSv2 and SQUIM-PESQ.
- Applied aesthetic predictors in downstream tasks (TTS, TTM, TTA) using two strategies: filtering (removing audio below p-th percentile, p=25,50) and prompting (adding "Audio quality: y" prefix, y=round(score)/r, r=2,5).
- Prompting strategy outperformed filtering in both objective and subjective evaluations: maintained audio alignment (WER, CLAP similarity) while improving quality, with 95% confidence intervals showing consistent wins in pairwise comparisons across all tasks.
- On natural sound and music datasets, Audiobox-Aesthetics-PQ achieved 0.87 and 0.85 utterance-level Pearson correlation, respectively, demonstrating strong generalization beyond speech.
The authors use a table to compare the performance of various audio quality predictors, including their proposed Audiobox-Aesthetics models, against human-annotated scores across four quality dimensions. Results show that Audiobox-Aesthetics-PQ, -PC, -CE, and -CU achieve higher correlations than the baseline models in most categories, with Audiobox-Aesthetics-CU achieving the highest correlation for GT-CU.
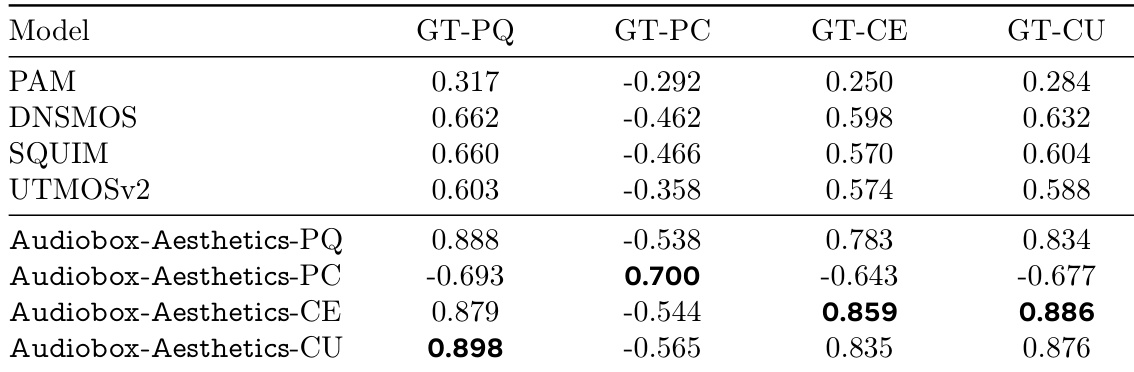
The authors use the table to compare the performance of different models in predicting audio quality across various metrics. Results show that PAM achieves the highest correlation with human-annotated scores in most categories, while Audiobox-Aesthetics-PC performs best in the GT-PC metric, indicating its strength in predicting production complexity.
The authors use a set of established audio quality predictors and their proposed Audiobox-Aesthetics models to evaluate performance on speech quality tasks. Results show that Audiobox-Aesthetics-CE achieves the highest correlations across both utterance- and system-level metrics, particularly on the VMC22-OOD dataset, outperforming all baseline models.
The authors use the table to compare the performance of their proposed Audiobox-Aesthetics models against the PAM baseline across five different quality dimensions. Results show that Audiobox-Aesthetics-PQ achieves the highest correlation with human-annotated scores for overall quality (OVL) and GT-PQ, while Audiobox-Aesthetics-CE performs best for GT-CE, and Audiobox-Aesthetics-PC achieves the highest score for GT-PC.
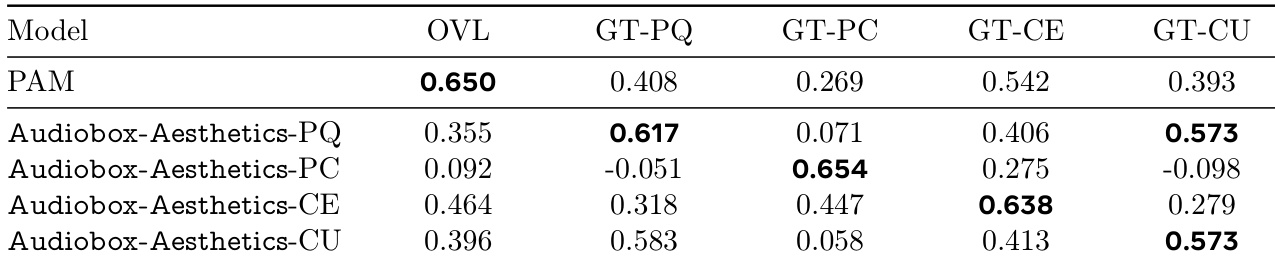
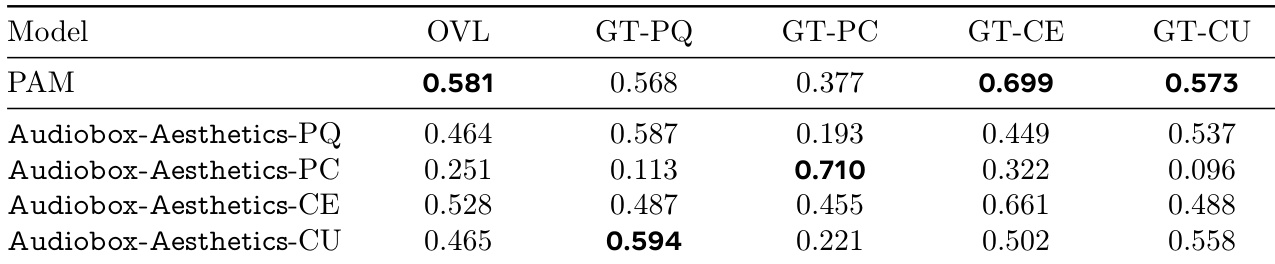
The authors use the table to compare the performance of their proposed Audiobox-Aesthetics models against the PAM baseline across four quality dimensions: production quality (PQ), production complexity (PC), content enjoyment (CE), and content usefulness (CU). Results show that Audiobox-Aesthetics-PQ achieves the highest correlation for GT-PQ, Audiobox-Aesthetics-PC for GT-PC, Audiobox-Aesthetics-CE for GT-CE, and Audiobox-Aesthetics-CU for GT-CU, indicating that the proposed models outperform PAM in predicting the respective audio quality aspects.