Command Palette
Search for a command to run...
VITA-1.5 : Vers une interaction en temps réel vision-parole au niveau de GPT-4o
VITA-1.5 : Vers une interaction en temps réel vision-parole au niveau de GPT-4o
Résumé
Les récents modèles linguistiques à grande échelle multimodaux (MLLM) se sont principalement concentrés sur l'intégration des modalités visuelles et textuelles, accordant moins d'importance au rôle de la parole dans l'amélioration de l'interaction. Pourtant, la parole joue un rôle crucial dans les systèmes de dialogue multimodaux, et la mise en œuvre de performances élevées dans les tâches visuelles et vocales demeure un défi majeur en raison des différences fondamentales entre ces modalités. Dans cet article, nous proposons une méthodologie de formation en plusieurs étapes soigneusement conçue, qui entraîne progressivement les modèles linguistiques à comprendre à la fois les informations visuelles et vocales, permettant ainsi une interaction fluide entre vision et parole. Notre approche préserve non seulement une forte capacité vision-langage, mais permet également des capacités de dialogue parole-parole efficaces, sans nécessiter de modules séparés de reconnaissance automatique de la parole (ASR) ni de synthèse vocale (TTS), accélérant ainsi considérablement la vitesse de réponse multimodale en boucle complète. En comparant notre méthode aux états de l'art sur des benchmarks couvrant les tâches d’image, de vidéo et de parole, nous démontrons que notre modèle possède à la fois des capacités visuelles et vocales puissantes, rendant possible une interaction vision-parole quasi en temps réel. Le code source a été rendu disponible à l’adresse suivante : https://github.com/VITA-MLLM/VITA.
One-sentence Summary
The authors from Nanjing University, Tencent Youtu Lab, XMU, and CASIA propose VITA, a multimodal large language model that integrates vision and speech understanding through a multi-stage training framework, enabling end-to-end speech-to-speech dialogue without separate ASR/TTS modules while preserving strong vision-language performance, significantly accelerating multimodal interaction for real-time applications.
Key Contributions
- Most Multimodal Large Language Models (MLLMs) have focused on vision and text, neglecting speech despite its importance in natural human-computer interaction; this paper addresses the challenge of integrating speech with vision in a unified framework, overcoming modality conflicts that degrade performance in existing models.
- The authors propose a three-stage training methodology that progressively introduces visual, speech, and speech generation capabilities, enabling end-to-end vision and speech interaction without relying on separate ASR or TTS modules, thus reducing latency and improving coherence.
- VITA-1.5 achieves strong performance on image, video, and speech benchmarks, matching state-of-the-art vision-language models while significantly advancing open-source speech capabilities, demonstrating effective omni-modal understanding and real-time dialogue interaction.
Introduction
The authors leverage recent advances in multimodal large language models (MLLMs) to address the growing need for natural, real-time human-computer interaction that integrates vision and speech. While prior MLLMs have excelled in vision-language tasks, they often neglect speech or rely on separate ASR and TTS modules, leading to high latency, loss of paralinguistic cues, and modality conflicts that degrade performance. The key challenge lies in jointly training models for vision and speech—modalities with distinct temporal and spatial characteristics—without compromising either capability. To overcome this, the authors introduce VITA-1.5, a three-stage training framework that progressively integrates visual, audio, and language modalities. This approach first establishes strong vision-language understanding, then incorporates speech input via an audio encoder, and finally enables end-to-end speech output through a trained audio decoder. The result is a unified, low-latency model that supports fluent, real-time vision and speech interaction without external modules, achieving performance on par with leading proprietary models across image, video, and speech benchmarks.
Dataset
- The training dataset for multimodal instruction tuning is composed of diverse data types, including image captioning, image question answering (QA), OCR and diagram understanding, video processing, and pure text data, with both Chinese and English content.
- Image Captioning Data includes ShareGPT4V, ALLaVA-Caption, SharedGPT4o-Image², and synthetic data, used to train the model in generating descriptive language for images.
- Image QA Data comprises LLaVA-150K, LLaVA-Mixture-sample, LVIS-Instruct, ScienceQA, ChatQA, and curated subsets from LLaVA-OV, focusing on general image QA and mathematical reasoning tasks.
- OCR & Diagram Data draws from Anyword-3M, ICDAR2019-LSVT, UReader, SynDOG, ICDAR2019-LSVT-QA, and additional samples from LLaVA-OV, enabling the model to interpret text and diagrams within images.
- Video Data includes ShareGemini and synthetic data, supporting video captioning and video-based QA capabilities.
- Pure Text Data enhances the model’s language understanding and generation, particularly for text-based QA.
- The dataset is used across different training phases with selective sampling of subsets to meet specific objectives, such as visual description, reasoning, or multimodal alignment.
- Synthetic data used in image and video tasks is generated from open-source sources like Wukong, LAION, and CC12M.
- An additional 110,000 hours of internal speech-transcription paired ASR data (Chinese and English) are included to train the audio encoder and align it with the LLM.
- 3,000 hours of text-speech paired data from a TTS system are used to train the speech decoder.
- No explicit cropping strategy is mentioned, but metadata construction likely involves task-specific labeling and alignment of modalities during data processing.
Method
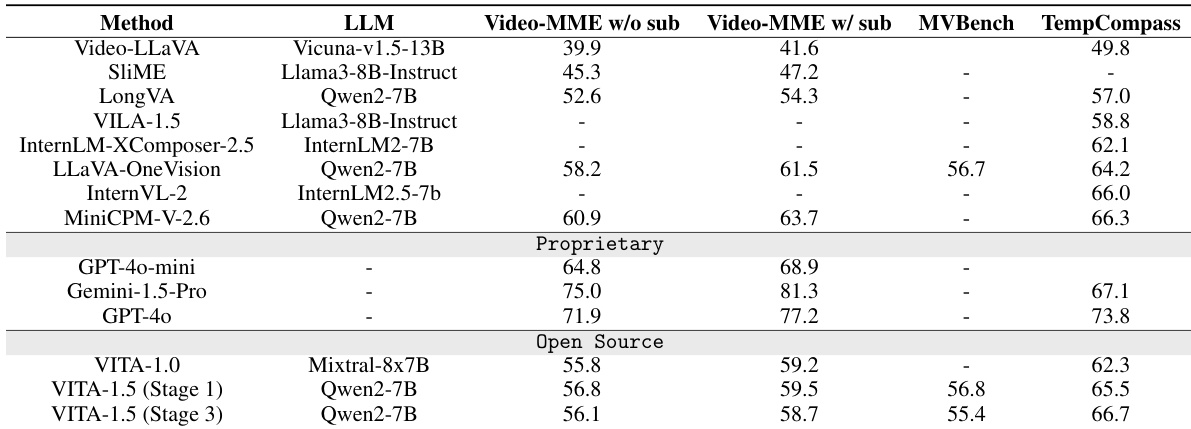
The authors leverage a multimodal architecture for VITA-1.5, structured around a large language model (LLM) that integrates vision and audio modalities through dedicated encoders and adapters. The overall framework, depicted in the diagram below, follows a "Multimodal Encoder-Adaptor-LLM" configuration. On the input side, visual and audio data are processed by their respective encoders—InternViT-300M for vision and a custom speech encoder with 24 Transformer blocks—before being projected into the LLM's token space via modality-specific adapters. The vision adapter employs a two-layer MLP to map visual features to tokens, while the speech adapter uses convolutional layers with 2x downsampling. The output side features an end-to-end speech generation module, replacing the external TTS system used in prior versions. This module consists of a non-autoregressive (NAR) speech decoder that generates an initial distribution of speech tokens from text embeddings, followed by an autoregressive (AR) speech decoder that refines these tokens step-by-step. The final speech tokens are decoded into a continuous waveform using a TiCodec model, which operates with a single codebook of size 1024 and a 40Hz token frequency.
The model's training process is designed to mitigate modality conflicts through a three-stage strategy, as illustrated in the figure below. Stage 1 focuses on vision-language training. It begins with vision alignment, where only the vision adapter is trained using 20% of caption data to bridge the gap between visual and language features. This is followed by vision understanding, where the visual encoder, adapter, and LLM are trained on 100% of caption data to enable the model to generate natural language descriptions of images. The final stage of this phase, vision SFT, trains the model on a combination of caption and QA data to enhance its instruction-following and question-answering capabilities for visual inputs. Stage 2 introduces audio input tuning. Stage 2.1, audio alignment, first trains the speech encoder using a Connectionist Temporal Classification (CTC) loss on speech-transcription pairs to map audio features to text representations, followed by training the speech adapter to integrate these features into the LLM. Stage 2.2, audio SFT, further trains the model on speech-text QA pairs, where a portion of text questions are replaced with speech versions, and a classification head is added to the LLM to distinguish between speech and text inputs. Stage 3 focuses on audio output tuning. Stage 3.1 trains the codec model to map speech to discrete tokens and back, while Stage 3.2 trains the NAR and AR speech decoders using text-speech paired data. During this stage, the LLM is frozen to preserve its multimodal understanding capabilities while enabling speech generation.

Experiment
- Evaluated on image understanding benchmarks (MME, MMBasech, MMStar, MathVista, HallusionBench, AI2D, OCRBench, MMVet), VITA-1.5 achieves performance comparable to state-of-the-art open-source models and surpasses closed-source models like GPT-4V and GPT-4o-mini, demonstrating strong vision-language capabilities.
- On video understanding benchmarks (Video-MME, MVBasech, TempCompass), VITA-1.5 performs on par with top open-source models but still lags behind proprietary models such as GPT-4o and Gemini 1.5 Pro, indicating room for improvement in video comprehension.
- After training on audio input and output stages, VITA-1.5 retains nearly all original visual-language capabilities, confirming effective multimodal integration without degradation.
- On ASR benchmarks, VITA-1.5 achieves leading performance in both Mandarin (CER) and English (WER), outperforming specialized speech models and demonstrating robust speech recognition across languages.
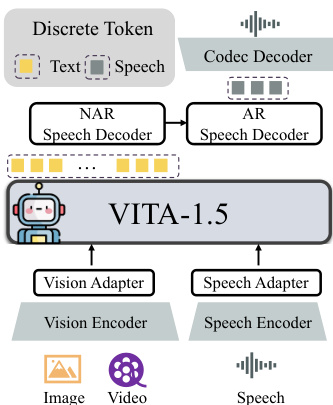
The authors use Table 4 to evaluate VITA-1.5's speech recognition performance on Mandarin and English benchmarks, comparing it against baseline models. Results show that VITA-1.5 achieves the lowest Character Error Rate in Mandarin and the lowest Word Error Rate in English, outperforming specialized speech models.
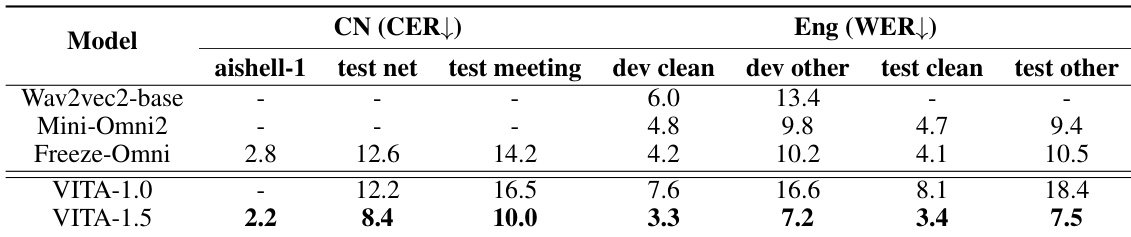
The authors use Table 2 to evaluate VITA-1.5's image understanding performance across multiple benchmarks, showing that it performs comparably to leading open-source models and surpasses some closed-source models like GPT-4V and GPT-4o-mini. Results show that VITA-1.5 maintains strong visual-language capabilities after multi-stage training, with competitive scores across tasks such as general multimodal understanding, mathematical reasoning, and OCR.
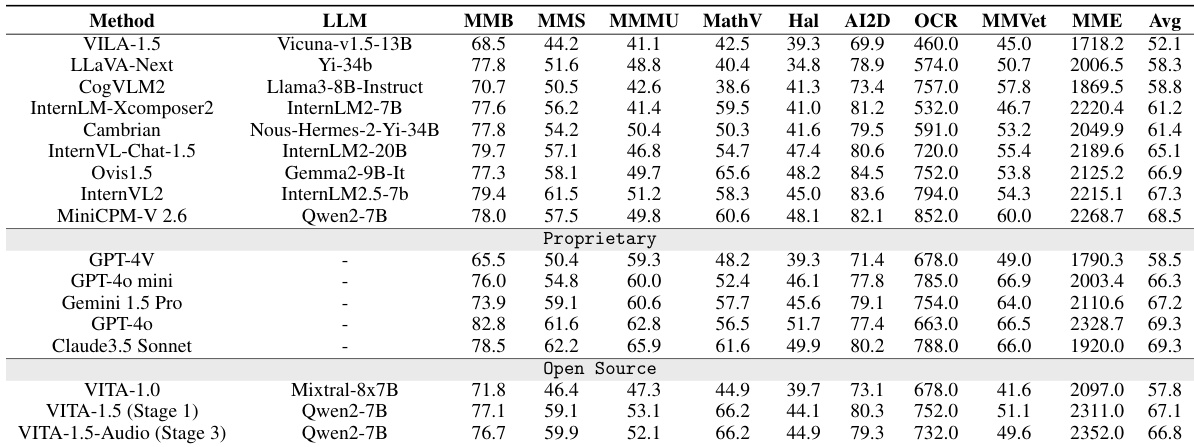
Results show that VITA-1.5 achieves competitive performance on video understanding benchmarks, outperforming several open-source models and approaching the capabilities of proprietary models like GPT-4o and Gemini-1.5-Pro, though it still lags behind them. The model maintains strong visual-language abilities after audio-specific training stages, as evidenced by its consistent performance across benchmarks.