Command Palette
Search for a command to run...
LTX-Video : Diffusion latente vidéo en temps réel
LTX-Video : Diffusion latente vidéo en temps réel
Résumé
Nous introduisons LTX-Video, un modèle de diffusion latente basé sur les transformateurs, qui adopte une approche holistique de la génération vidéo en intégrant de manière fluide les fonctions du Video-VAE et du transformateur débruitant. Contrairement aux méthodes existantes, qui traitent ces composants de manière indépendante, LTX-Video vise à optimiser leur interaction afin d’améliorer l’efficacité et la qualité. Au cœur de ce modèle se trouve un Video-VAE soigneusement conçu, capable d’atteindre un ratio de compression élevé de 1:192, avec une réduction spatio-temporelle de 32 × 32 × 8 pixels par jeton, réalisée grâce au déplacement de l’opération de découpage en patches de l’entrée du transformateur vers l’entrée du VAE. L’opération dans cet espace latent fortement compressé permet au transformateur d’effectuer efficacement une attention auto-spatio-temporelle complète, essentielle pour générer des vidéos haute résolution tout en préservant une cohérence temporelle. Toutefois, cette forte compression limite intrinsèquement la représentation des détails fins. Pour pallier ce défaut, notre décodeur VAE est chargé à la fois de la conversion latente vers pixels et de l’étape finale de débruitage, produisant directement le résultat net dans l’espace pixel. Cette approche préserve la capacité à générer des détails fins sans engager le coût de calcul associé à un module de décompression séparé. Notre modèle prend en charge diverses applications, notamment la génération vidéo à partir de texte et la génération vidéo à partir d’image, ces deux fonctionnalités étant entraînées simultanément. Il permet une génération plus rapide que temps réel, produisant 5 secondes de vidéo à 24 fps et à résolution 768×512 en seulement 2 secondes sur une GPU Nvidia H100, surpassant ainsi tous les modèles existants de taille comparable. Le code source et les modèles pré-entraînés sont disponibles publiquement, établissant ainsi une nouvelle référence pour la génération vidéo accessible et évolutif.
One-sentence Summary
The authors from Lightricks propose LTX-Video, a unified transformer-based latent diffusion model that integrates Video-VAE and denoising transformer into a single optimized pipeline, enabling efficient full spatiotemporal self-attention via a 1:192 compression ratio and a novel VAE design that performs both latent-to-pixel conversion and final denoising, achieving fast, high-quality text-to-video and image-to-video generation at 768x512 resolution with real-time performance on an H100 GPU, setting a new benchmark for scalable and accessible video synthesis.
Key Contributions
- LTX-Video introduces a unified architecture that integrates the Video-VAE and denoising transformer into a single optimized pipeline, enabling efficient full spatiotemporal self-attention in a highly compressed latent space with a 1:192 compression ratio (32×32×8 pixel per token), achieved by relocating patchifying to the VAE input.
- The model addresses the loss of fine details at high compression by assigning the VAE decoder the dual role of latent-to-pixel conversion and final denoising, generating high-fidelity outputs directly in pixel space without requiring a separate upsampling module.
- LTX-Video achieves faster-than-real-time generation—producing 5 seconds of 768×512 video at 24 fps in just 2 seconds on an H100 GPU—outperforming existing models of similar scale (2B parameters) and supporting both text-to-video and image-to-video generation with a single, open-source model.
Introduction
The rise of text-to-video models has been driven by spatiotemporal transformers and 3D VAEs, but prior approaches often use conventional VAE designs that fail to optimally balance spatial and temporal compression. While recent work like DC-VAE shows benefits of high spatial compression and deep latent spaces in image generation, extending this to video remains challenging due to increased complexity in maintaining motion fidelity and high-frequency detail. The authors introduce LTX-Video, a transformer-based latent diffusion model that achieves superior performance by using a 3D VAE with 128-channel latent depth and high spatial compression, enabling efficient, high-quality video generation. A key innovation is shifting the final denoising step to the VAE decoder, which reconstructs missing high-frequency details at high compression rates. The model leverages Rotary Positional Embeddings with normalized fractional coordinates and attention normalization to improve spatial-temporal coherence and training stability. It generates 5-second videos at 2 seconds per run on consumer-grade hardware, outperforming comparable models in speed and quality, and supports both text-to-video and image-to-video generation via a lightweight conditioning mechanism. The open-source release prioritizes accessibility, sustainability, and responsible use.
Dataset
- The training dataset combines publicly available data with licensed material, including both videos and images, to ensure broad coverage of visual concepts and support diverse generation capabilities.
- Image data is treated as a distinct resolution-duration combination within the training mix, enriching the model’s exposure to static visual concepts not commonly found in video data.
- All data undergoes rigorous quality control: a Siamese network trained on tens of thousands of manually labeled image pairs is used to predict aesthetic scores, with samples below a threshold filtered out.
- To reduce distribution shifts, image pairs for training the aesthetic model were selected based on shared top-three labels from a multi-labeling network, ensuring consistent semantic relevance.
- Videos are filtered to exclude those with minimal motion, focusing the dataset on dynamic content aligned with the model’s intended use.
- Black bars are cropped from videos to standardize aspect ratios and maximize usable visual area.
- For fine-tuning, only the highest aesthetic content—identified through the filtering pipeline—is used to promote visually compelling outputs.
- All videos and images are re-captioned using an internal automatic captioning system to improve metadata accuracy and strengthen text-image alignment.
- Caption statistics show a wide range of word counts (Fig 14a) and clip durations (Fig 14b), with most clips lasting under 10 seconds.
- The final dataset is processed through a unified pipeline that integrates aesthetic filtering, motion and aspect ratio standardization, and metadata enhancement, enabling high-quality, contextually rich training.
Method
The authors leverage a holistic approach to latent diffusion, integrating the Video-VAE and the denoising transformer to optimize their interaction within a highly compressed latent space. The core of this framework is a Video-VAE that achieves a 1:192 compression ratio through spatiotemporal downscaling of 32×32×8 pixels per token. This high compression is enabled by relocating the patchifying operation from the transformer's input to the VAE's input, allowing the transformer to efficiently perform full spatiotemporal self-attention in the compressed space. The overall denoising process is illustrated in the framework diagram, which shows the model first performing latent-to-latent denoising steps, followed by a final latent-to-pixels denoising step to generate the output video.
The Video-VAE architecture, detailed in Figure 4, consists of a causal encoder and a denoising decoder. The causal encoder, which uses 3D causal convolutions, processes the input video to produce a compressed latent representation. The denoising decoder, which is conditioned on the diffusion timestep and incorporates multi-layer noise injection, is responsible for both converting the latent representation back to pixel space and performing the final denoising step. This dual role of the decoder is a key innovation, as it allows the model to generate fine details directly in pixel space without the need for a separate upsampling module, thereby preserving detail and reducing computational cost.
To address the challenges of high compression, the authors introduce several key enhancements to the VAE. A novel Reconstruction GAN (rGAN) loss is employed, where the discriminator is provided with both the original and reconstructed samples for each iteration, simplifying the task of distinguishing real from fake and improving reconstruction quality. Additionally, a multi-layer noise injection mechanism is used to generate more diverse high-frequency details, and a uniform log-variance is applied to prevent channel underutilization. A spatio-temporal Discrete Wavelet Transform (DWT) loss is also introduced to ensure the reconstruction of high-frequency details, which are often lost with standard L1 or L2 losses.
The denoising transformer, built upon the Pixart-α architecture, is designed to efficiently model diverse and complex video data. It incorporates several advanced features, including Rotary Positional Embeddings (RoPE) for dynamic positional information, RMSNorm for normalization, and QK-normalization to stabilize attention logits. The transformer block architecture, shown in Figure 6, integrates these components to process the latent tokens. The model is conditioned on text prompts using a T5-XXL text encoder and cross-attention mechanisms, allowing for robust text-to-video synthesis. For image-to-video generation, the model uses a per-token timestep conditioning strategy, where the first frame is encoded and conditioned with a small diffusion timestep, enabling seamless animation of a given image.
The training process is based on rectified-flow, where the model learns to predict the velocity of the denoising process. The authors employ a log-normal timestep scheduling to focus training on more difficult timesteps and use multi-resolution training to enable the model to generate videos at various resolutions and durations. This approach ensures that the model generalizes well to unseen configurations by exposing it to a diverse range of input sizes and token counts during training.
Experiment
- Trained using ADAM-W optimizer, with pre-training followed by fine-tuning on high-aesthetic video subsets.
- Human evaluation on 1,000 text-to-video and 1,000 image-to-video prompts showed LTX-Video outperforms Open-Sora Plan, CogVideoX (2B), and PyramidFlow in overall quality, motion fidelity, and prompt adherence, achieving higher win rates across both tasks.
- Reconstruction GAN loss significantly improves high-frequency detail recovery at high VAE compression (1:192), reducing visible artifacts compared to standard GAN loss.
- Exponential RoPE frequency spacing yields lower training loss than inverse-exponential spacing, confirming its superiority in diffusion training.
- VAE decoder performing the final denoising step (at t = 0.05) produces superior video quality, especially in high-motion sequences, outperforming the standard approach where denoising is done solely in latent space.
- LTX-Video shows strong prompt adherence but is sensitive to prompt quality; limited to short videos (up to 10 seconds); domain-specific generalization remains untested.
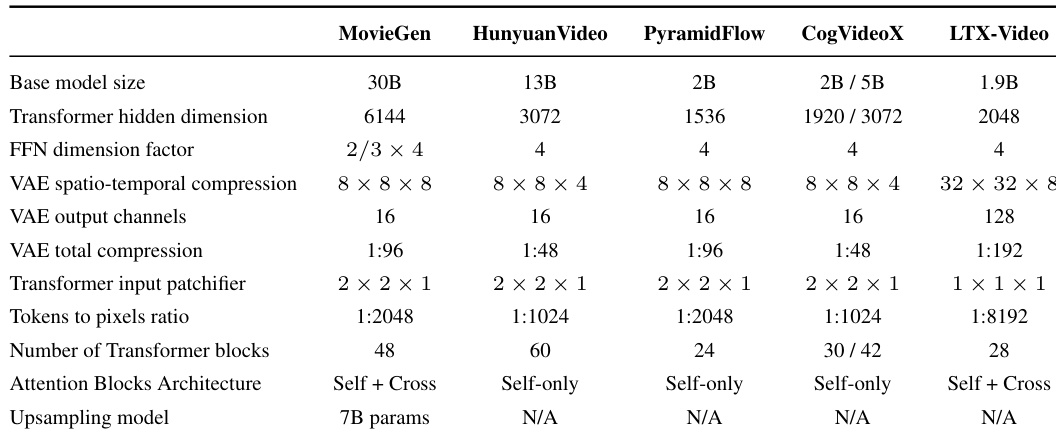
The authors compare LTX-Video to several state-of-the-art models of similar size, including MovieGen, HunyuanVideo, PyramidFlow, and CogVideoX, in a human evaluation study. Results show that LTX-Video significantly outperforms these models in both text-to-video and image-to-video tasks, achieving higher win rates in pairwise comparisons while also demonstrating a notable speed advantage.
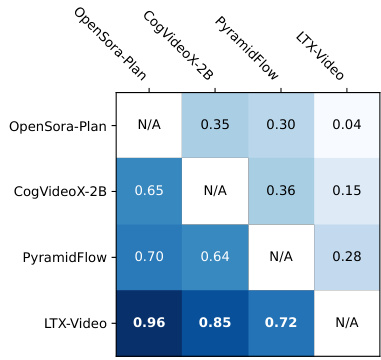
Results show that LTX-Video significantly outperforms other models in both text-to-video and image-to-video tasks, achieving win rates of 0.96 and 0.85 respectively in pairwise comparisons. The model's superior performance is consistent across both evaluation categories, with the highest win rates against all other tested models.
Results show that LTX-Video significantly outperforms other models of similar size in both text-to-video and image-to-video tasks, achieving win rates of 85% and 91% respectively. The authors use a human evaluation survey with 20 participants to compare LTX-Video against Open-Sora Plan, CogVideoX, and PyramidFlow, finding that LTX-Video is strongly preferred, particularly in high-motion scenarios.
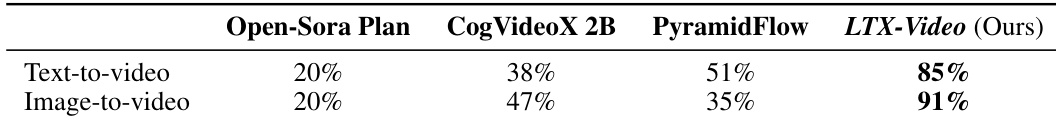
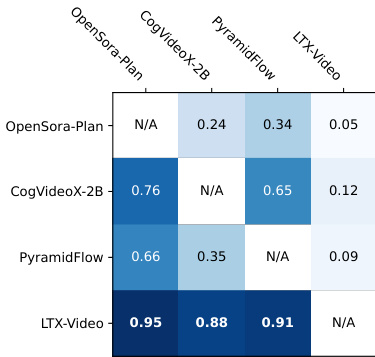
Results show that LTX-Video significantly outperforms other similar-sized models in both text-to-video and image-to-video tasks, achieving win rates of 0.95 and 0.91 respectively. The model's superior performance is consistent across all evaluated pairs, demonstrating strong preference in human evaluations for visual quality, motion fidelity, and prompt adherence.