Command Palette
Search for a command to run...
Plus intelligent, meilleur, plus rapide, plus long : un encodeur bidirectionnel moderne pour une fine-tuning et une inférence rapides, efficaces en mémoire et à longue portée
Plus intelligent, meilleur, plus rapide, plus long : un encodeur bidirectionnel moderne pour une fine-tuning et une inférence rapides, efficaces en mémoire et à longue portée
Résumé
Les modèles transformer uniquement encodeurs comme BERT offrent un excellent compromis performance-taille pour les tâches de recherche et de classification par rapport aux modèles décodeurs plus volumineux. Malgré leur rôle central dans de nombreuses chaînes de production, les améliorations de type Pareto apportées à BERT depuis sa sortie ont été limitées. Dans cet article, nous présentons ModernBERT, qui intègre des optimisations modernes aux modèles uniquement encodeurs et représente une avancée majeure selon le critère de Pareto par rapport aux encodeurs antérieurs. Entraînés sur 2 billions de tokens avec une longueur native de séquence de 8192, les modèles ModernBERT obtiennent des résultats de pointe sur un large ensemble d’évaluations couvrant diverses tâches de classification ainsi que des recherches à vecteur unique et multi-vecteurs sur différentes domaines (y compris le code). En plus d’une performance en aval remarquable, ModernBERT est également l’encodeur le plus efficace en termes de vitesse et de mémoire, conçu pour être déployé en inférence sur des GPU courants.
One-sentence Summary
The authors from Answer.AI, LightOn, Johns Hopkins University, NVIDIA, and HuggingFace propose ModernBERT, a Pareto-improving encoder-only transformer trained on 2 trillion tokens with native 8192-length sequences, achieving state-of-the-art performance in classification and retrieval across domains—including code—while being the most efficient encoder for inference on standard GPUs, outperforming prior models through modern architectural optimizations.
Key Contributions
- ModernBERT introduces a modernized architecture for encoder-only transformers, addressing long-standing limitations in sequence length (native 8192 tokens), model efficiency, and training data scope, while significantly improving performance over older BERT-based models across diverse tasks.
- Trained on 2 trillion tokens including code data, ModernBERT achieves state-of-the-art results on the BEIR benchmark suite for both single-vector (DPR) and multi-vector (ColBERT) retrieval, outperforming prior encoder models in semantic search across multiple domains.
- The models are designed for high inference efficiency, processing 8192-token sequences nearly twice as fast as previous models, and are released with full training checkpoints and FlexBERT, a modular framework enabling reproducible experimentation.
Introduction
Encoder-only transformer models remain central to many NLP applications, particularly in information retrieval and discriminative tasks like classification and named entity recognition, due to their efficiency and strong performance-to-size ratio. Despite the rise of large language models, encoder models are still widely used—especially in Retrieval-Augmented Generation pipelines—yet most systems continue to rely on outdated architectures like BERT, which suffer from limited context length (512 tokens), inefficient designs, and training data that lacks modern or code-specific content. Prior modernization efforts have addressed only narrow aspects such as training efficiency or longer context, but not both performance and efficiency across diverse tasks. The authors introduce ModernBERT, a redesigned encoder model with a more efficient architecture and training on 2 trillion tokens—including code data—enabling state-of-the-art performance on retrieval, classification, and code-related tasks. It processes 8192-token sequences nearly twice as fast as prior models, while also releasing FlexBERT, a modular framework for future research, and all intermediate training checkpoints.
Dataset
- The dataset consists of 2 trillion tokens of primarily English data drawn from diverse sources, including web documents, code repositories, and scientific literature, forming a carefully curated mixture selected through ablation studies to optimize model performance.
- The data is processed using a modern BPE tokenizer based on a modified version of the OLMo tokenizer, which improves token efficiency and code task performance while maintaining backward compatibility with BERT’s special tokens ([CLS], [SEP]) and templating.
- The tokenizer’s vocabulary size is set to 50,368—chosen to be a multiple of 64 for optimal GPU utilization—plus 83 unused tokens to support future downstream applications.
- To maximize training efficiency and ensure consistent batch sizes, the authors employ sequence packing with a greedy algorithm, achieving over 99% packing efficiency and minimizing batch size variance caused by unpadding.
- For evaluation, four synthetic document sets are created, each containing 8,192 documents: two fixed-length sets (512 tokens and 8,192 tokens per document) and two varying-length sets drawn from normal distributions centered at 256 and 4,096 tokens, respectively, to simulate real-world input variability.
- Models are evaluated on inference efficiency by measuring tokens processed per second across ten runs on a single NVIDIA RTX 4090 GPU, under both standard and xformers-enhanced settings to assess the impact of optimizations like unpadding.
Method
The authors leverage a modernized encoder-only transformer architecture, building upon the foundational design of BERT while incorporating recent advancements to achieve significant performance and efficiency improvements. The overall framework extends the standard transformer architecture (Vaswani et al., 2017) with a series of architectural, efficiency-oriented, and hardware-aware modifications. Refer to the framework diagram for a high-level overview of the model's structure.
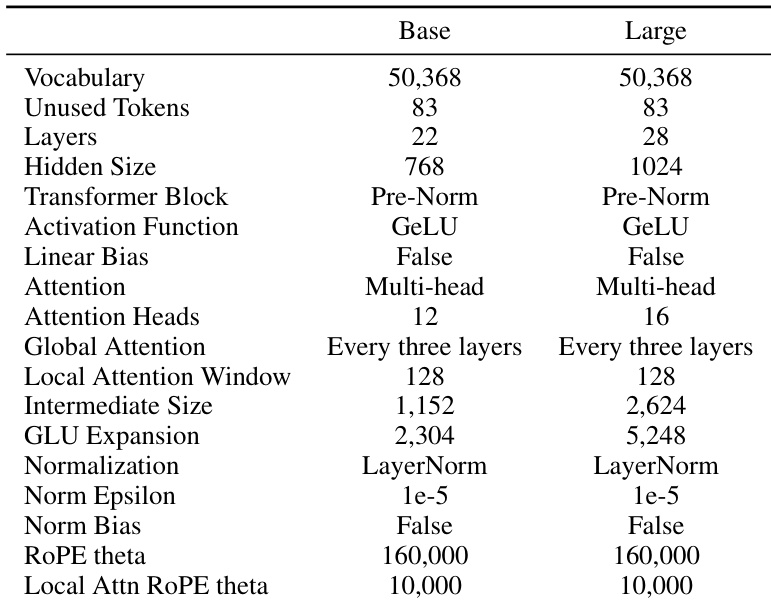
At the core of the architectural improvements, ModernBERT adopts several well-established optimizations. Bias terms are disabled in all linear layers except the final decoder linear layer, and all bias terms in Layer Norms are also removed, allowing the model to allocate more parameters to linear transformations. Positional embeddings are replaced with rotary positional embeddings (RoPE), which offer better performance in both short- and long-context settings, efficient implementation across frameworks, and ease of context extension. Normalization is implemented using pre-normalization with standard LayerNorm, which stabilizes training and includes a LayerNorm after the embedding layer, with the first LayerNorm in the first attention layer removed to avoid redundancy. The activation function is upgraded from GeLU to GeGLU, a gated linear unit variant that has demonstrated consistent empirical gains in recent studies.
To enhance computational efficiency, ModernBERT integrates multiple optimizations. Attention layers alternate between global and local attention mechanisms: every third layer uses global attention with a RoPE theta of 160,000, while the remaining layers employ a 128-token sliding window attention with a RoPE theta of 10,000. This alternating attention strategy balances long-range modeling with computational efficiency. The model also employs unpadding, a technique that eliminates padding tokens during both training and inference by concatenating sequences into a single jagged sequence. This avoids redundant computation on semantically empty tokens and is implemented using Flash Attention's variable-length attention and RoPE support, enabling efficient processing of unpadded sequences. Flash Attention is used in a hybrid manner: Flash Attention 3 for global attention layers and Flash Attention 2 for local attention layers, ensuring compatibility and performance across different hardware. Additionally, PyTorch’s torch.compile is utilized to compile compatible modules, improving training throughput by approximately 10 percent with minimal overhead.
The model design is explicitly hardware-aware, aiming to maximize GPU utilization while maintaining a deep and narrow architecture. At the same parameter count, deeper models with narrower layers tend to outperform shallower, wider ones, though they may incur higher inference latency. ModernBERT strikes a balance by designing models with 22 and 28 layers for the base and large variants, respectively, with parameter counts of 149 million and 395 million. The base model has a hidden size of 768 and a GLU expansion of 2,304, while the large model features a hidden size of 1,024 and a GLU expansion of 5,248. These dimensions are chosen to optimize tiling across tensor cores and streaming multiprocessors on a target set of common GPUs, including NVIDIA T4, A10, L4, RTX 3090, RTX 4090, A100, and H100. The design process involved extensive ablations to ensure optimal performance across this hardware basket, with a focus on inference efficiency.
Experiment
- Trained ModernBERT-base on 1.7 trillion tokens with a 30% masking rate, StableAdamW optimizer, and a 1−sqrt learning rate decay, achieving stable training and faster convergence via weight initialization from ModernBERT-base and batch size scheduling.
- Extended ModernBERT’s context length to 8192 tokens by increasing RoPE theta to 160,000 and training for an additional 300 billion tokens, resulting in balanced performance across retrieval and classification tasks.
- On the GLUE benchmark, ModernBERT-base outperforms all existing base models, including DeBERTaV3-base, marking the first MLM-trained model to do so, while ModernBERT-large achieves near-DeBERTaV3-large performance with 10× fewer parameters.
- In short-context retrieval (BEIR), both ModernBERT variants surpass existing encoders, including GTE-en-MLM and NomicBERT, with ModernBERT-large achieving a larger lead despite having fewer parameters (395M vs. 435M).
- In long-context retrieval (MLDR), ModernBERT outperforms shorter-context models and matches or exceeds GTE-en-MLM in multi-vector settings, with at least a 9 NDCG@10 point lead, attributed to long pretraining and local attention synergy.
- On code-related tasks (CodeSearchNet, StackQA), ModernBERT outperforms all other models, demonstrating strong code understanding due to training on programming data.
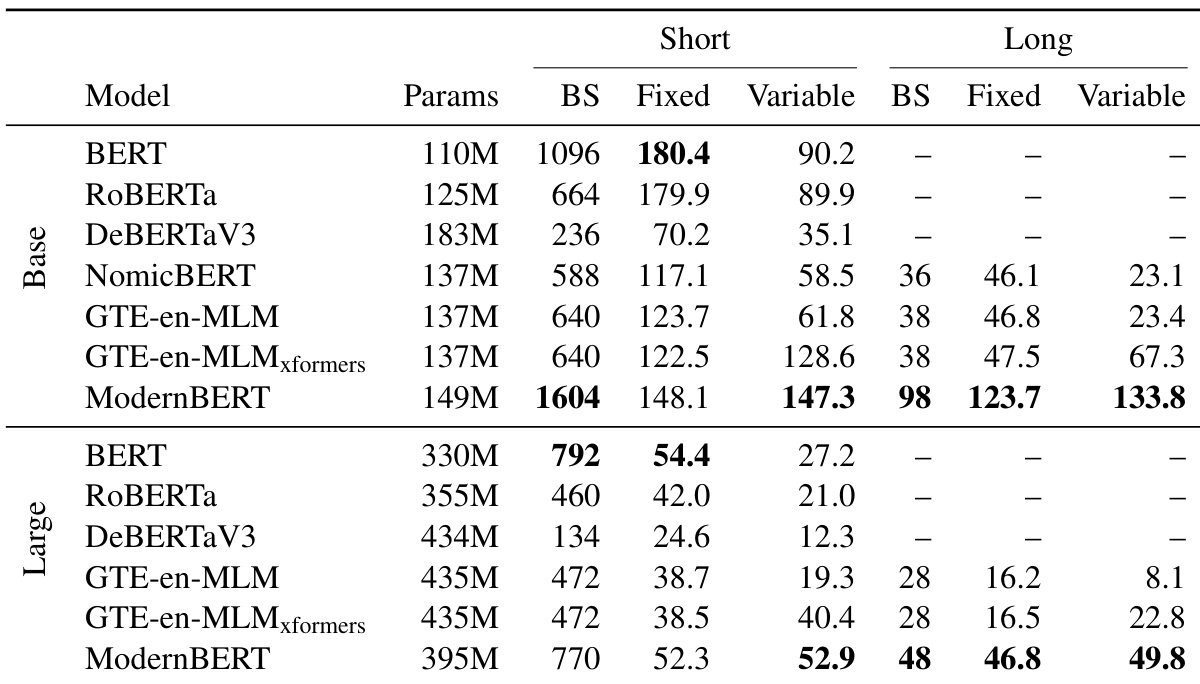
- ModernBERT is the most efficient model overall: it processes 512-token inputs faster than recent encoders and is 2.65× (base) and 3× (large) faster on 8192-token inputs, with 98.8–118.8% higher throughput at long contexts due to local attention.
- ModernBERT achieves the highest memory efficiency, supporting batch sizes twice as large as other models at base size and at least 60% larger at large size, with significantly lower memory usage than DeBERTaV3.
Results show that ModernBERT outperforms all other models in both short and long context retrieval tasks, achieving the highest scores in both fixed and variable length settings. ModernBERT also demonstrates superior memory and inference efficiency, processing tokens faster and supporting larger batch sizes than competing models.
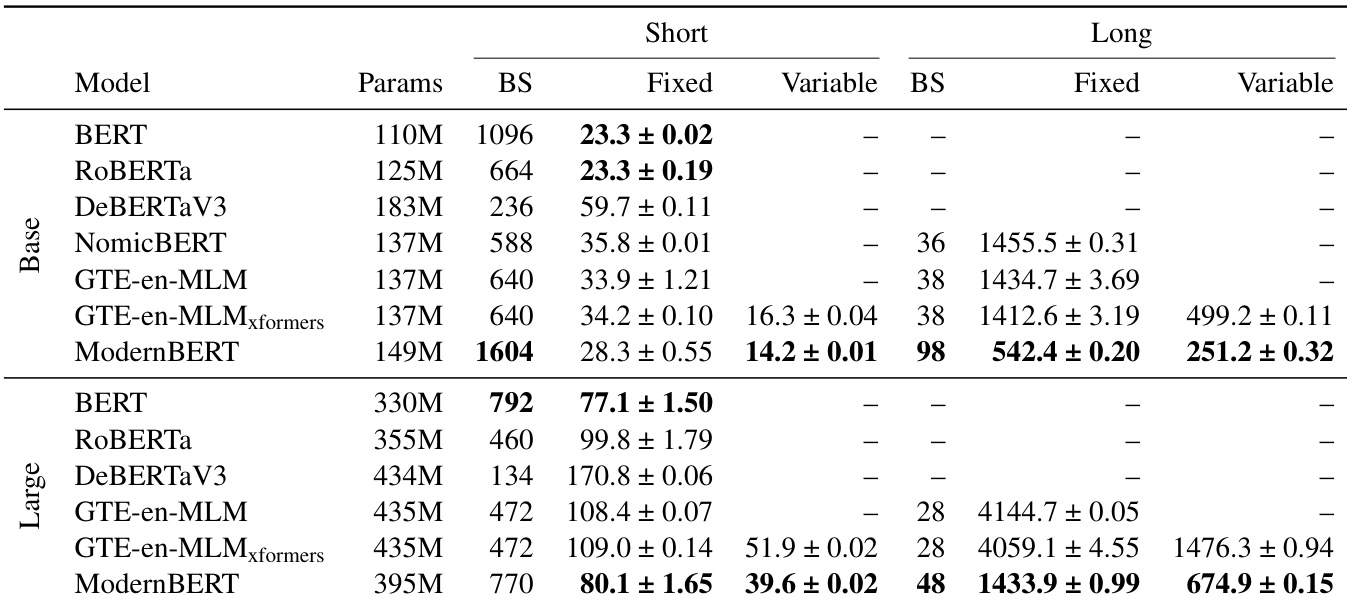
Results show that ModernBERT achieves the highest memory efficiency and inference speed across both short and long context settings. ModernBERT-base processes fixed-length inputs 14.5–30.9% faster than GTE-en-MLM-base and handles batch sizes twice as large, while ModernBERT-large processes long-context inputs 2.65 times faster than the next-fastest encoder and maintains a significant lead in memory efficiency.
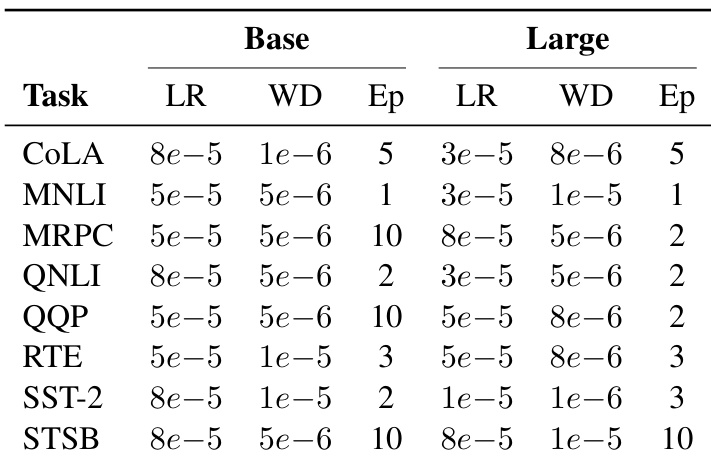
The authors use a hyperparameter search to determine optimal training settings for ModernBERT on GLUE tasks, with learning rates ranging from 5e-5 to 8e-5, weight decay values between 1e-6 and 5e-6, and epochs varying from 1 to 10 depending on the task. Results show that ModernBERT achieves strong performance across all GLUE benchmarks, with the base model outperforming all existing base models and the large model ranking second among large encoders.
The authors use a modified trapezoidal learning rate schedule with a 1−sqrt decay and StableAdamW optimizer for training ModernBERT, achieving strong performance across downstream tasks. Results show that ModernBERT outperforms existing models in both natural language understanding and retrieval tasks, with notable efficiency gains in memory and inference speed, particularly at longer context lengths.
Results show that ModernBERT achieves the highest average score across all evaluated tasks, outperforming all other models in both base and large sizes. ModernBERT-base surpasses all existing base models on GLUE, while ModernBERT-large demonstrates strong performance on long-context retrieval and natural language understanding, achieving the best results on most tasks despite having fewer parameters than competitors.
