Command Palette
Search for a command to run...
Analyse d'images De Documents Multimodaux Dolphin
1. Introduction au tutoriel

Dolphin est un modèle d'analyse syntaxique multimodal de documents, lancé par ByteDance en mai 2025. Ce modèle repose sur une approche en deux étapes : il génère d'abord une séquence d'éléments de mise en page du document ; ensuite, il utilise ces éléments comme points d'ancrage pour analyser le contenu en parallèle. Dolphin excelle dans diverses tâches d'analyse syntaxique, surpassant des modèles tels que GPT-4.1 et Mistral-OCR. Des articles de recherche associés sont disponibles. Dolphin : analyse d'images de documents via une invite d'ancrage hétérogène Elle a été acceptée par ACL 2025.
Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
2. Exemples de projets

3. Étapes de l'opération
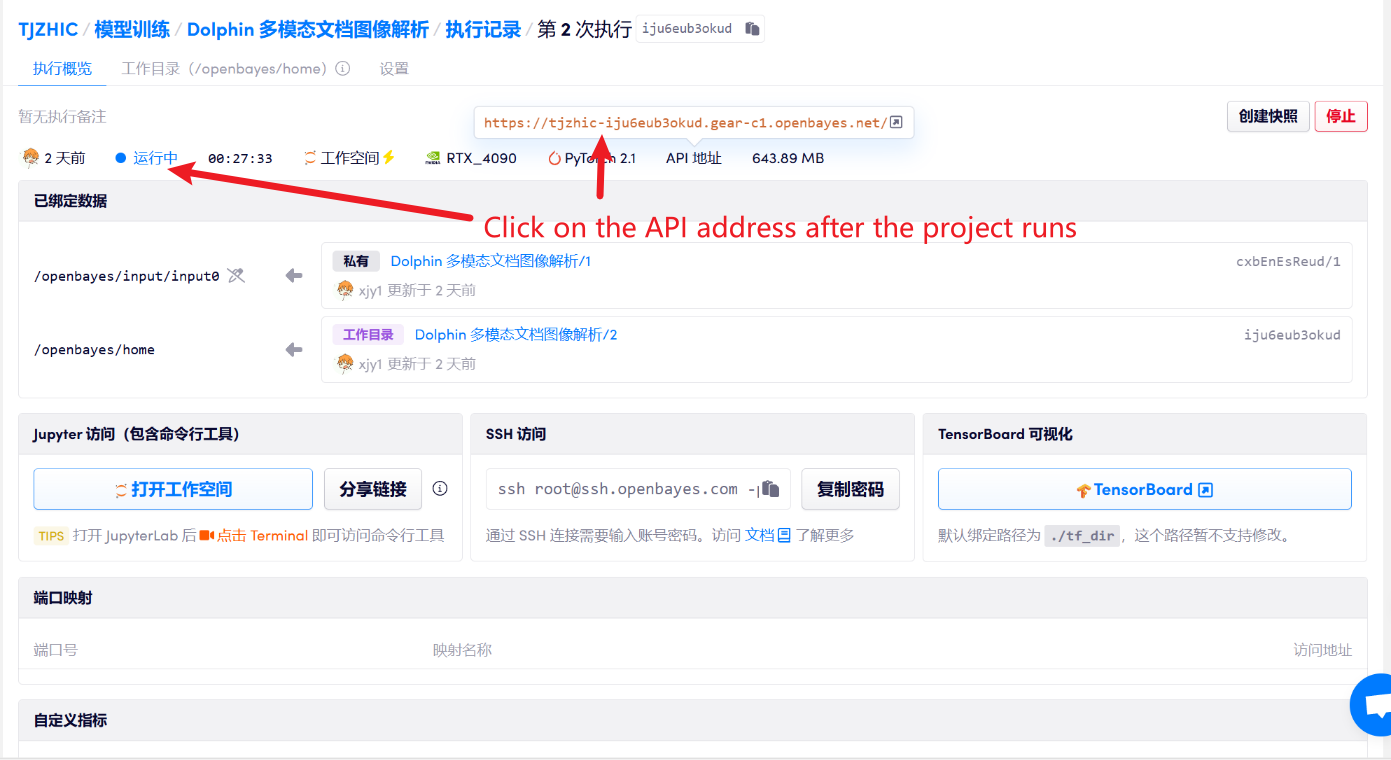
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
2. Exemples d'utilisation
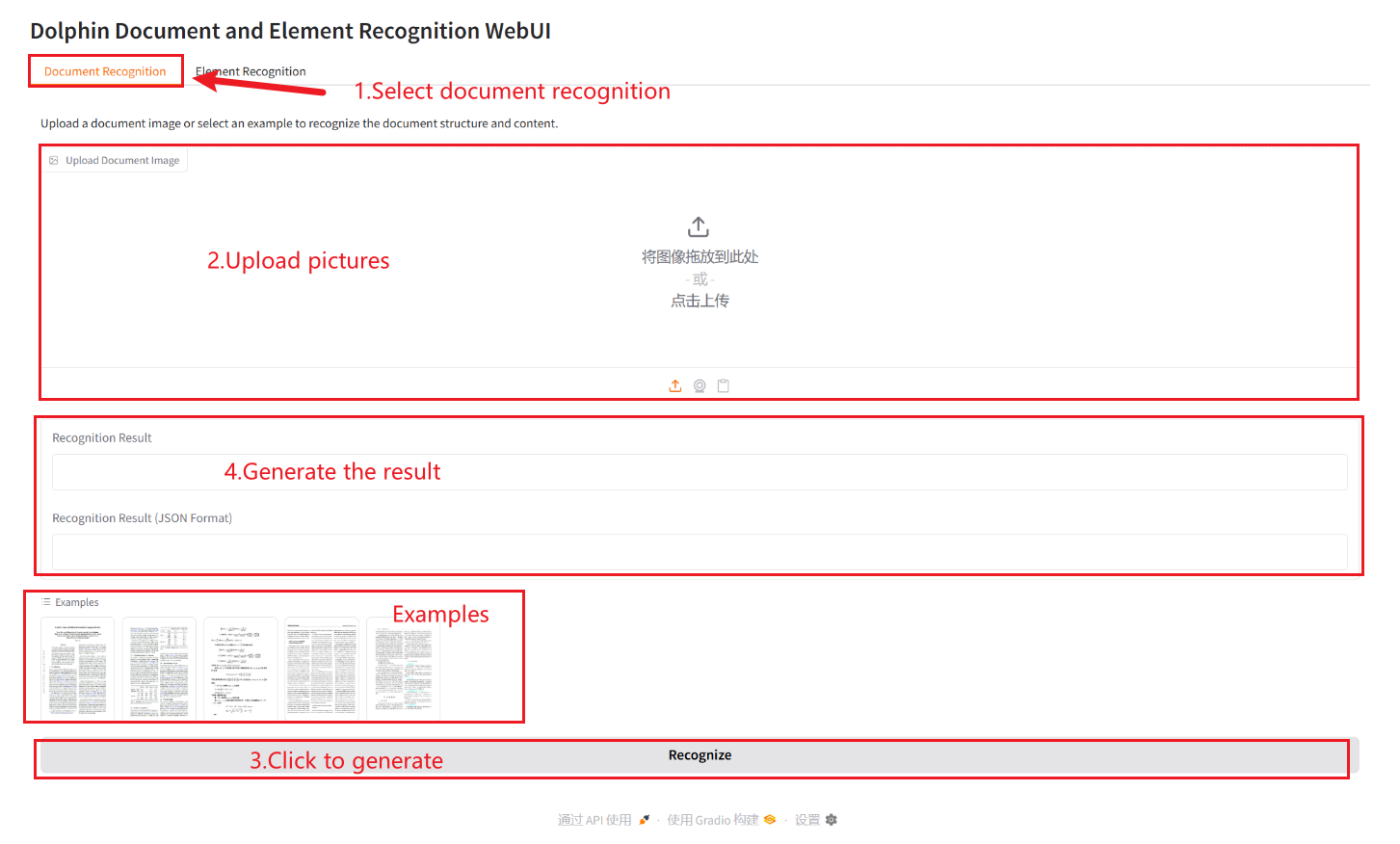
Reconnaissance de documents
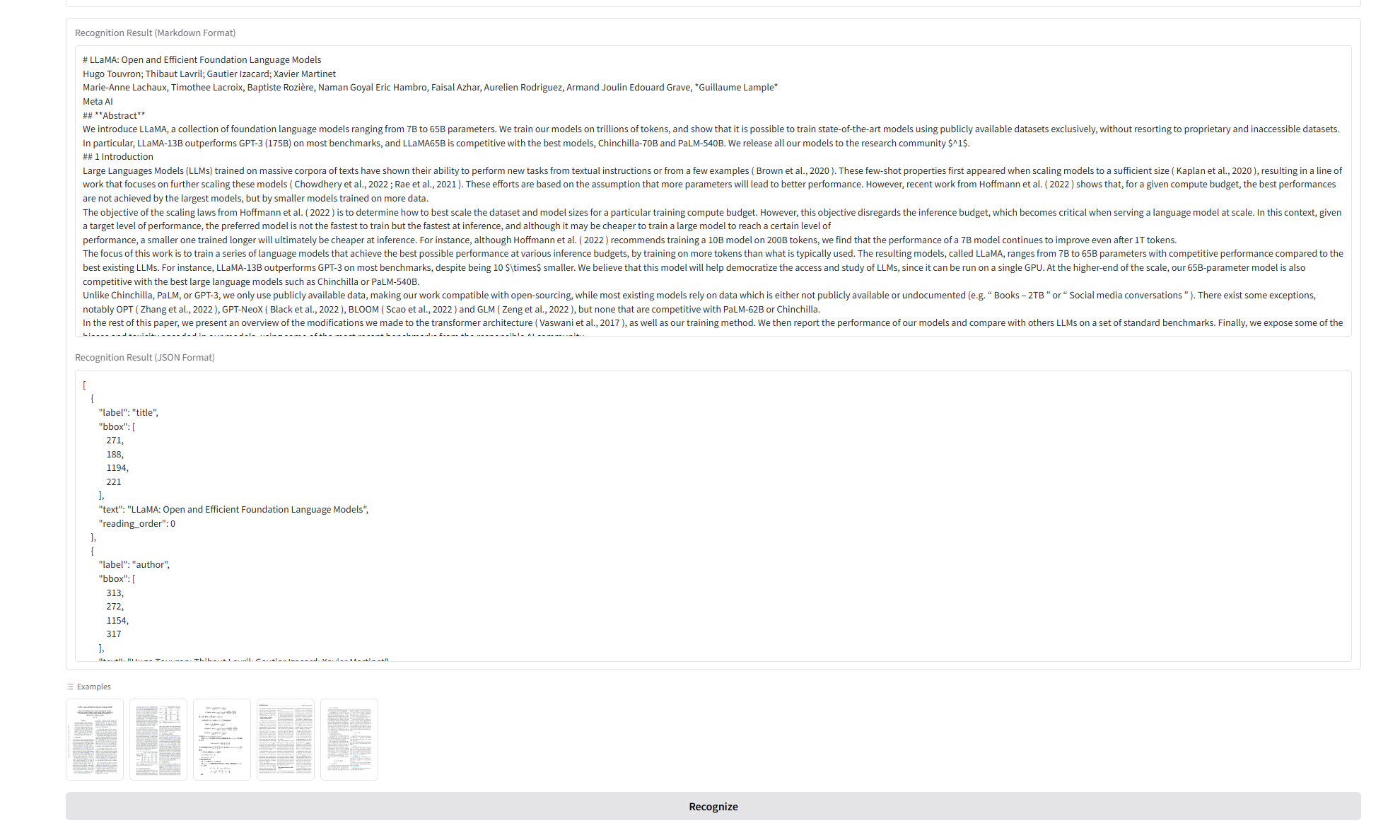
 résultat
résultat
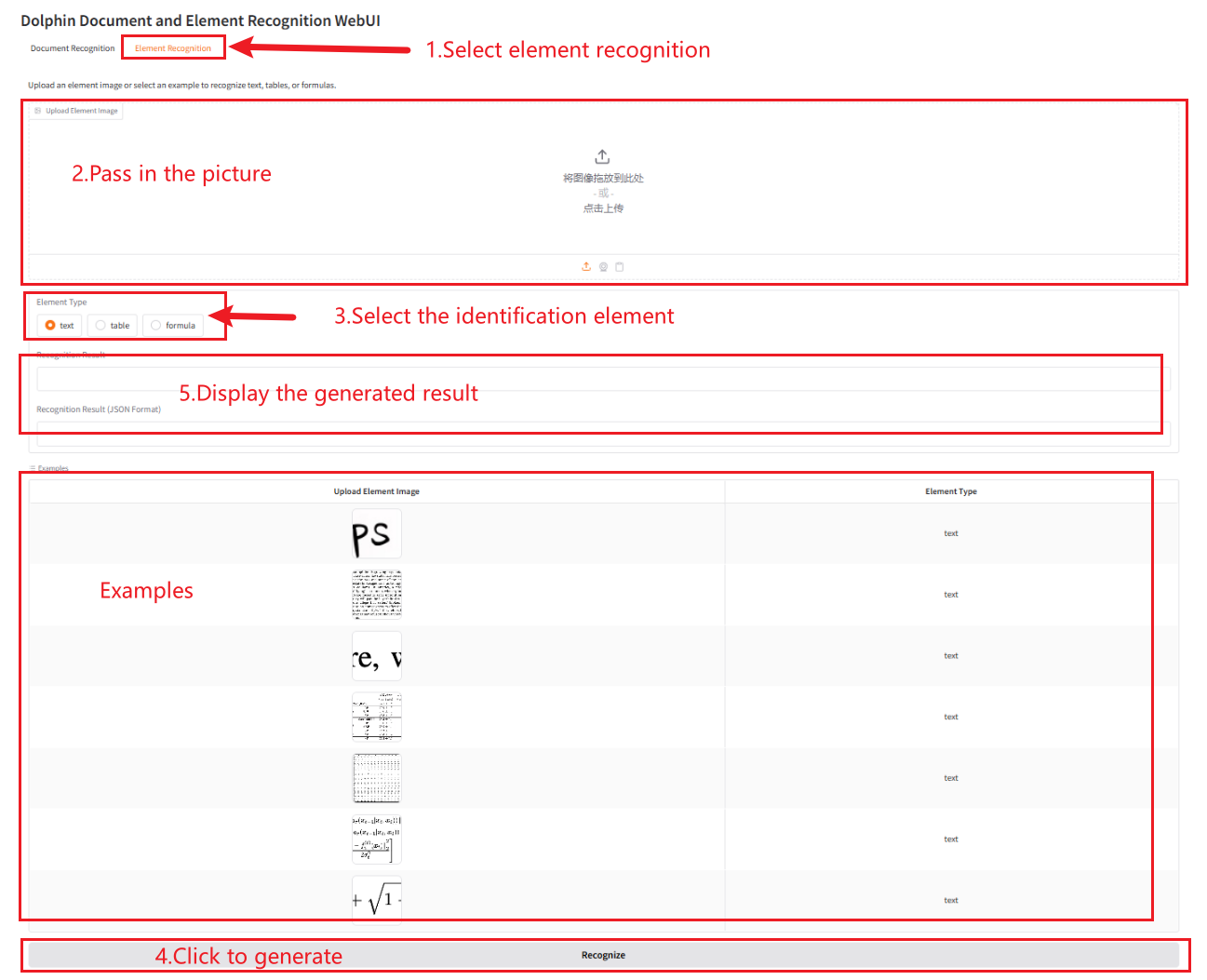
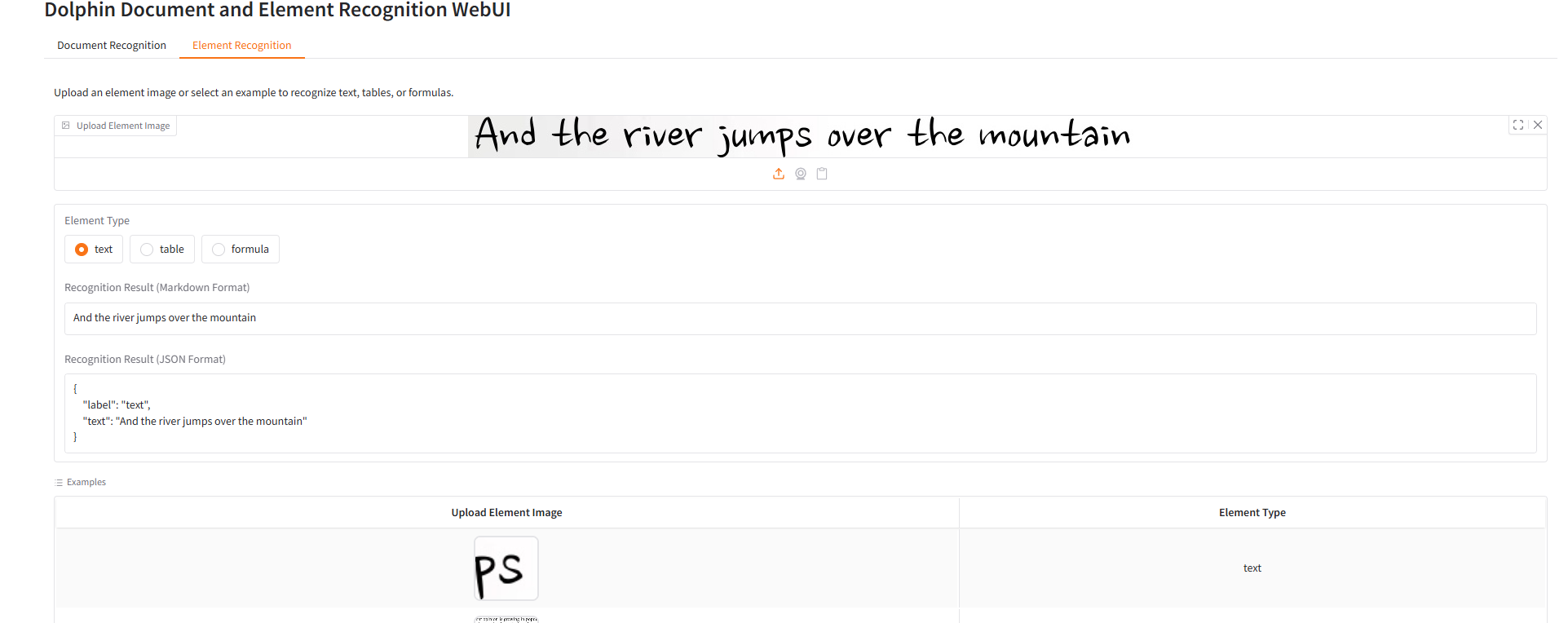
Reconnaissance des éléments
résultat
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@inproceedings{dolphin2025,
title={Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting},
author={Feng, Hao and Wei, Shu and Fei, Xiang and Shi, Wei and Han, Yingdong and Liao, Lei and Lu, Jinghui and Wu, Binghong and Liu, Qi and Lin, Chunhui and Tang, Jingqun and Liu, Hao and Huang, Can},
year={2025},
booktitle={Proceedings of the 65rd Annual Meeting of the Association for Computational Linguistics (ACL)}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.