Command Palette
Search for a command to run...
Ensemble De Données De Référence Pour La Génération De Compréhension De La Parole WildSpeech-Bench
Date
Taille
Organisation
URL du document
Licence
CC BY 4.0
Balises
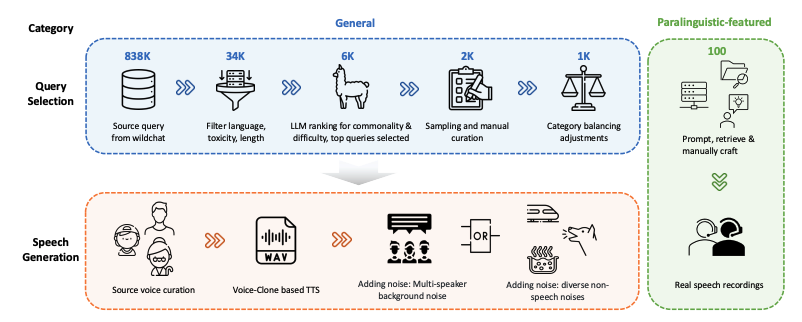
WildSpeech-Bench est le premier benchmark permettant d'évaluer les capacités de conversion parole-parole de SpeechLLM, publié par Tencent en 2025. Les résultats de l'article associé sont «WildSpeech-Bench : analyse comparative des LLM de bout en bout en milieu sauvage", qui vise à mesurer la capacité du modèle à comprendre et à générer une entrée vocale complète vers une sortie vocale (Speech-to-Speech, S2S) dans des scénarios d'interaction vocale réels. L'ensemble de données contient 1 100 requêtes réparties en cinq catégories principales : requêtes d'information, demandes de solutions, échanges d'opinions, création de texte et expressions paralinguistiques. Chaque catégorie correspond à une intention utilisateur courante. 1 000 de ces requêtes proviennent de scénarios d'interaction vocale généraux (notamment des requêtes d'information, des demandes de solutions, des échanges d'opinions et la création de texte), tandis que 100 autres sont caractérisées par des caractéristiques paralinguistiques telles que les pauses, l'intonation, le bégaiement et la reconnaissance quasi phonétique des mots. Chaque requête est accompagnée d'exemples de discours variés, couvrant un large éventail d'attributs du locuteur (sexe, âge, variantes vocales), de conditions acoustiques et de paramètres d'environnement sonore, afin de simuler de manière plus réaliste la diversité et les défis de l'interaction vocale naturelle.
Citation
@misc{zhang2025wildspeechbenchbenchmarkingendtoendspeechllms, titre={WildSpeech-Bench : Évaluation comparative de bout en bout des programmes SpeechLLM en situation réelle}, author={Linhao Zhang et Jian Zhang et Bokai Lei et Chuhan Wu et Aiwei Liu et Wei Jia et Xiao Zhou}, année={2025}, eprint={2506.21875}, préfixe d'archive={arXiv}, primaryClass={cs.CL}, }
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.