Command Palette
Search for a command to run...
Ensemble De Données De Référence Pour l'évaluation Multimodale Médicale GMAI-MMBench
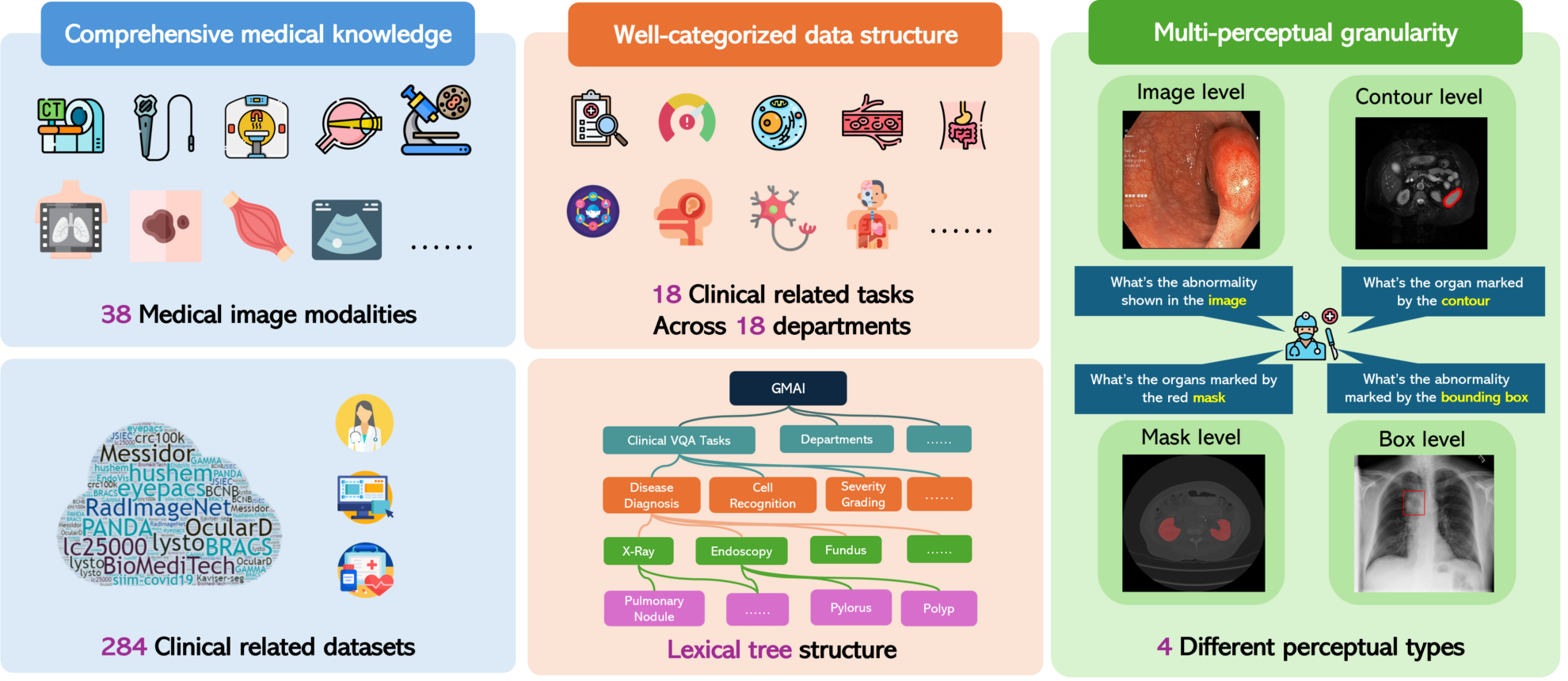
GMAI-MMBench est un benchmark d'évaluation multimodal conçu pour promouvoir le développement de l'intelligence artificielle médicale générale. Il a été lancé conjointement en 2024 par neuf institutions, dont le Laboratoire d'intelligence artificielle de Shanghai, l'Université de Washington, l'Université Monash, l'Université normale de Chine orientale, l'Université de Cambridge, l'Université Jiao Tong de Shanghai, l'Université chinoise de Hong Kong (Shenzhen), l'Institut de Big Data de Shenzhen et l'Institut de technologie avancée de Shenzhen, Académie chinoise des sciences.GMAI-MMBench : une évaluation multimodale complète de l'IA médicale généraleIl aide les chercheurs et les développeurs à mieux comprendre les effets des applications des grands modèles vision-langage (LVLM) dans le domaine médical et à identifier les lacunes techniques en fournissant des évaluations complètes et détaillées. Ce benchmark couvre un large éventail d'ensembles de données, dont 284 provenant de différentes sources, impliquant 38 modalités d'imagerie médicale et 18 tâches cliniquement pertinentes, couvrant 18 services médicaux différents et évalués selon quatre granularités perceptuelles différentes, prenant ainsi en compte les performances des LVLM sous plusieurs angles. Une caractéristique notable de GMAI-MMBench est son évaluation de la granularité multi-perceptuelle, qui se concentre non seulement sur l'évaluation au niveau global de l'image, mais va également en profondeur au niveau régional, offrant une perspective d'évaluation plus détaillée et plus complète. De plus, comme l’ensemble de données provient principalement des hôpitaux et est annoté par des médecins professionnels, les tâches d’évaluation de GMAI-MMBench sont plus proches des scénarios cliniques réels et ont une pertinence clinique élevée. Cette corrélation rend les résultats des benchmarks instructifs pour les applications médicales du monde réel. GMAI-MMBench permet également aux utilisateurs de personnaliser les tâches d’évaluation. En mettant en œuvre une structure arborescente de vocabulaire, les utilisateurs peuvent définir des tâches d’évaluation en fonction de leurs propres besoins, ce qui offre une flexibilité pour la recherche et les applications de l’IA médicale. En évaluant 50 LVLM, dont certains modèles GPT-4o avancés, l'équipe de recherche a constaté que même les modèles les plus avancés n'atteignaient qu'une précision de 52% dans le traitement des problèmes professionnels médicaux, ce qui montre qu'il y a encore beaucoup de place pour l'amélioration dans l'application des LVLM actuels dans le domaine médical. Le développement de GMAI-MMBench fournit une ressource précieuse pour évaluer et améliorer l’application des LVLM dans le domaine médical, tout en révélant les défis auxquels sont confrontées les technologies actuelles et en indiquant les directions de recherche futures.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.