Command Palette
Search for a command to run...
Ensemble De Données De Reconnaissance Vocale VoxCeleb2
Date
Taille
URL de publication
URL du document
Licence
CC BY 4.0
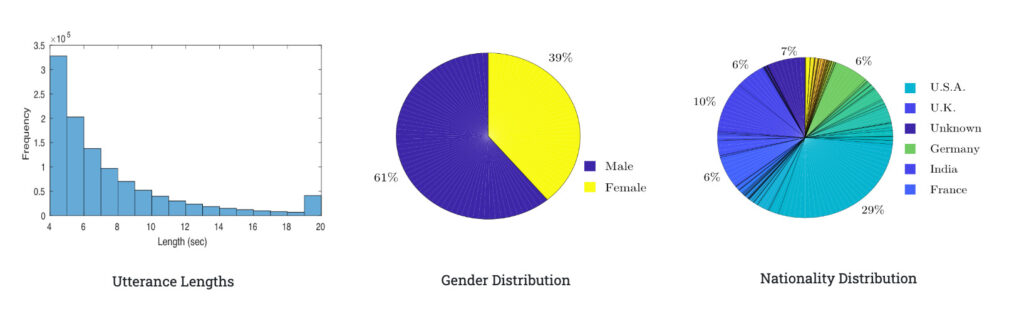
VoxCeleb2 est un ensemble de données de reconnaissance de locuteurs à grande échelle dérivé de médias open source, composé d'un million de corpus provenant de plus de 6 000 locuteurs. Étant donné que l'ensemble de données est collecté dans des scènes naturelles, les interférences telles que les rires, les conversations, les effets de canal, la musique, etc. ne manquent pas dans les clips vocaux.
Le corpus de VoxCeleb2 est multilingue, avec des locuteurs de 145 pays couvrant un large éventail d'accents, d'âges, d'ethnies et de langues. Dans le même temps, cet ensemble de données comprend de l'audio et de la vidéo et convient également à la résolution de problèmes tels que la synthèse vocale visuelle, la séparation de la parole, la conversion intermodale visage-voix et la reconnaissance faciale vidéo.
Détails de l'ensemble de données :
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.