Command Palette
Search for a command to run...
POINTS-Reader: A Lightweight Document vision-language Model With end-to-end distillation-free Architecture
Date
Size
1.2 GB
License
Other
GitHub
Paper URL
1. Tutorial Introduction

POINTS-Reader is a lightweight visual-language model (VLM) jointly launched by Tencent, Shanghai Jiao Tong University, and Tsinghua University in August 2025, specifically designed for converting document images to text. POINTS-Reader does not pursue large parameter counts, nor does it rely on teacher model "distillation." Instead, it uses a two-stage self-evolving framework to achieve high-precision end-to-end recognition of complex Chinese and English documents (including tables, formulas, and multi-column layouts) while maintaining a minimalist structure. Related research papers are available. POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion It has been accepted by EMNLP 2025 and will be presented at the main conference.
The computing resources used in this tutorial are a single RTX 4090 card.
2. Effect display
Single Column with Latex Formula

Single Column with Table
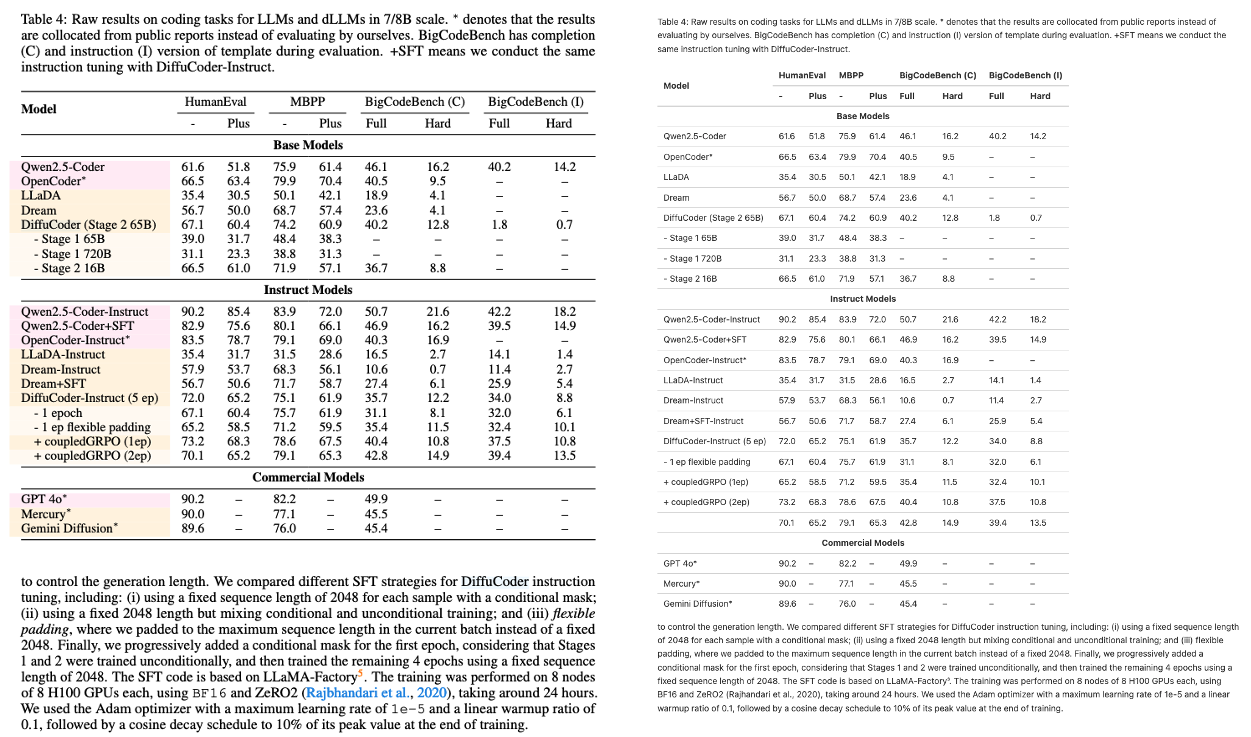
Multi-column with Latex Formula

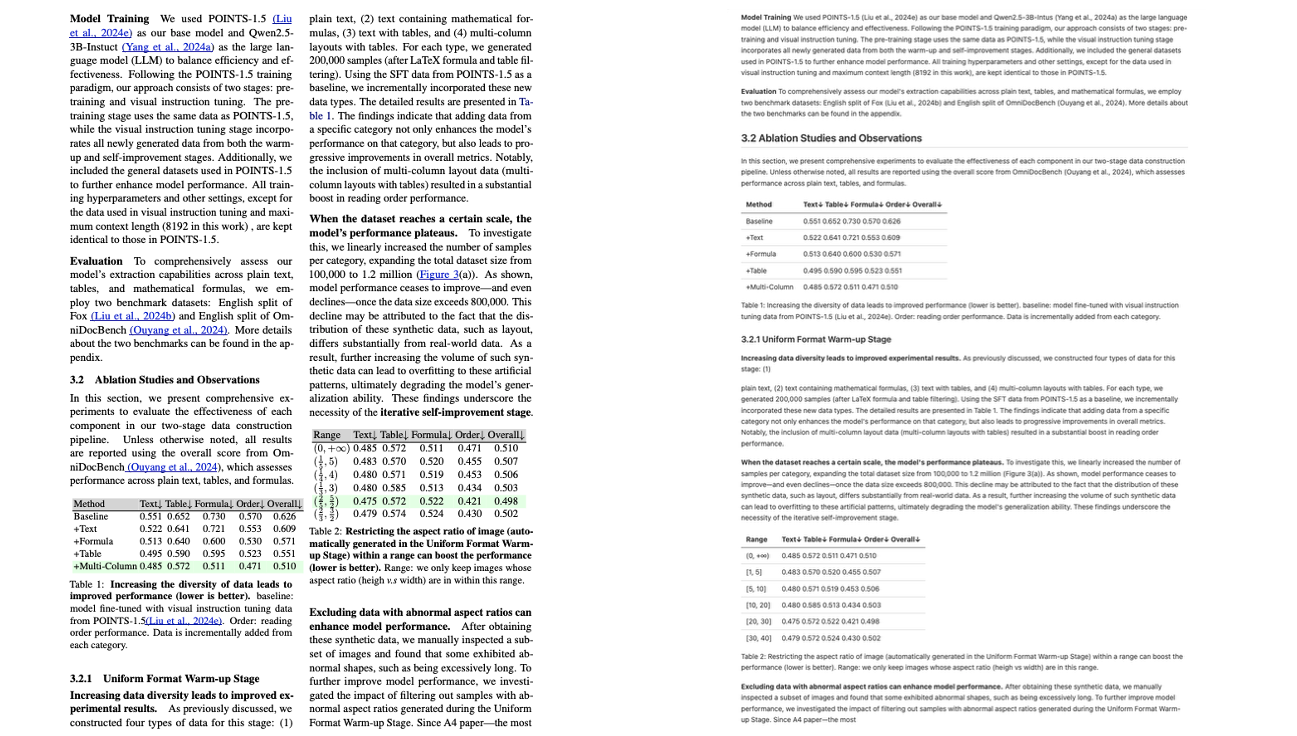
Multi-column with Table
3. Operation steps
1. Start the container
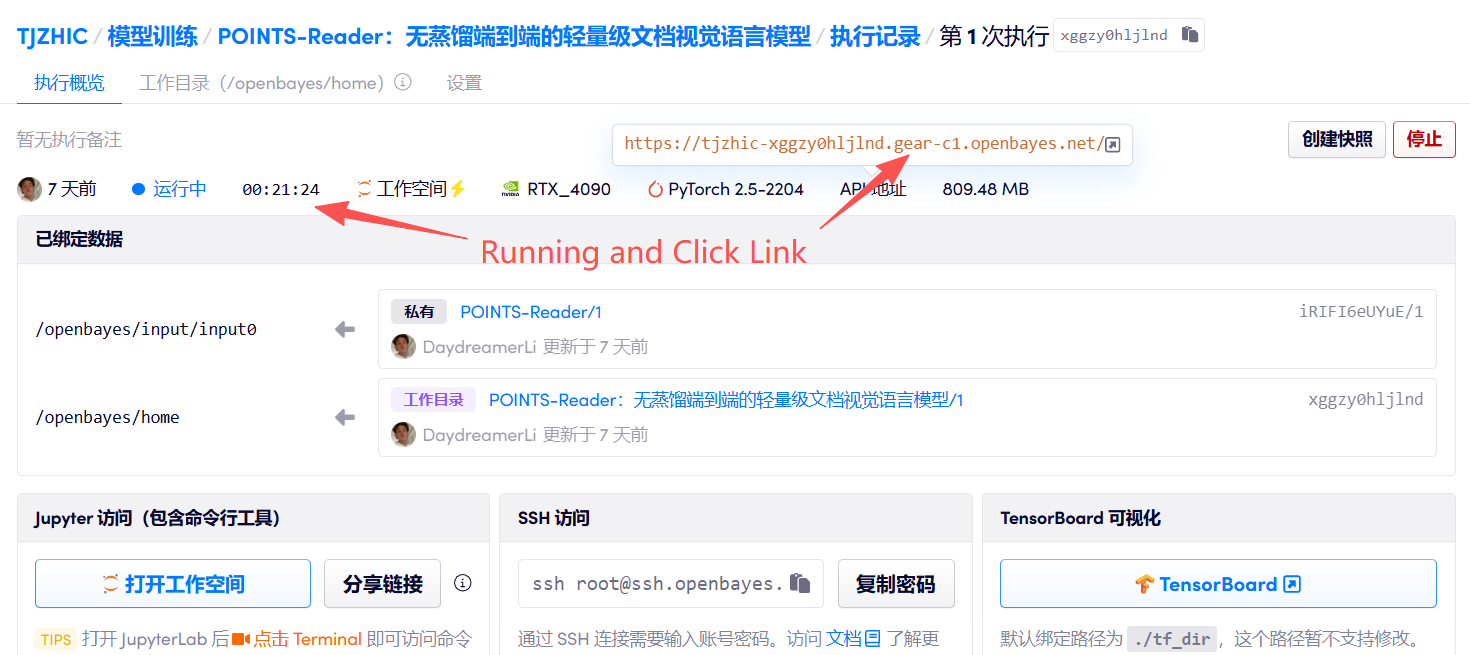
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
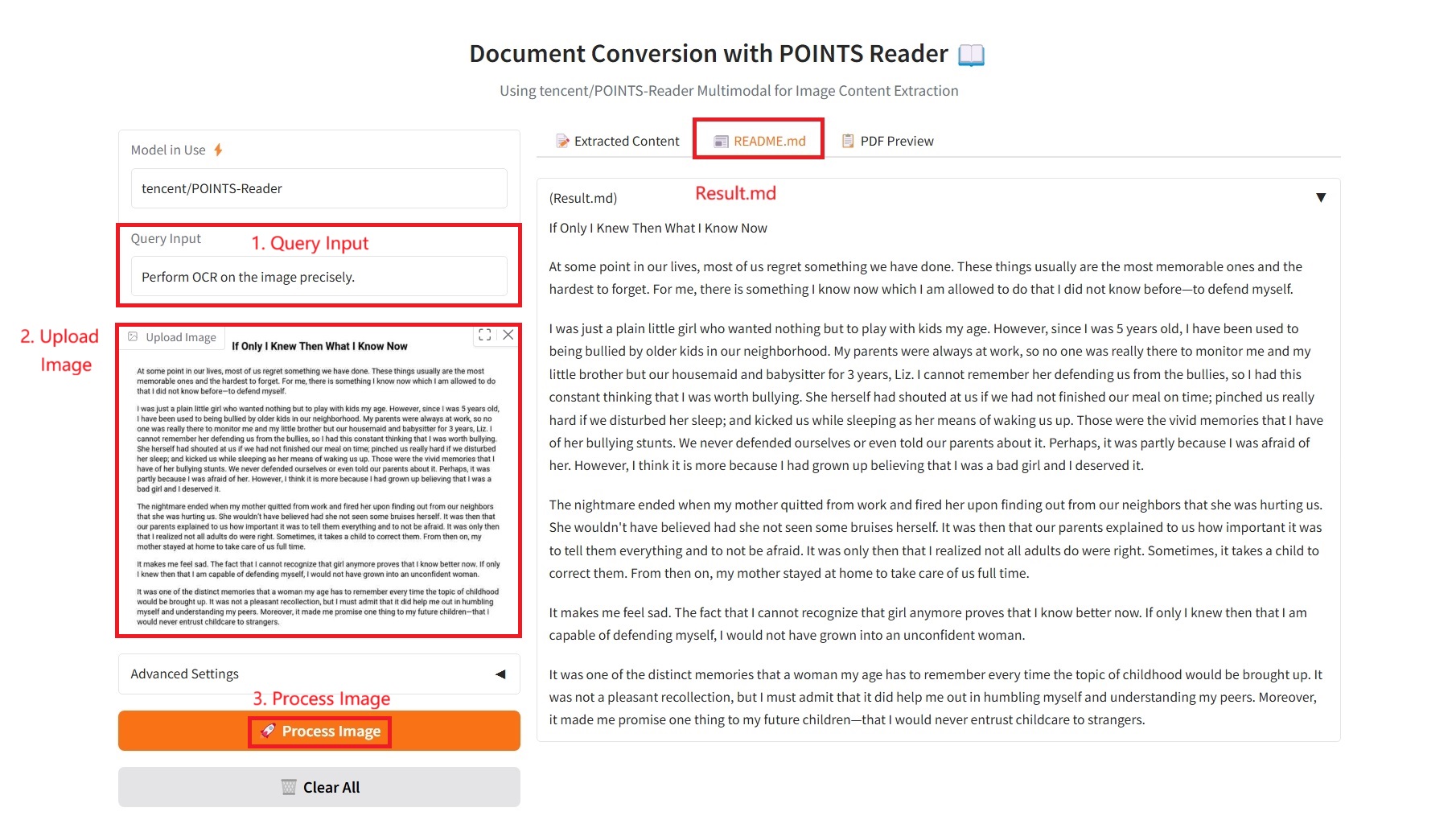
1. Extracted Content
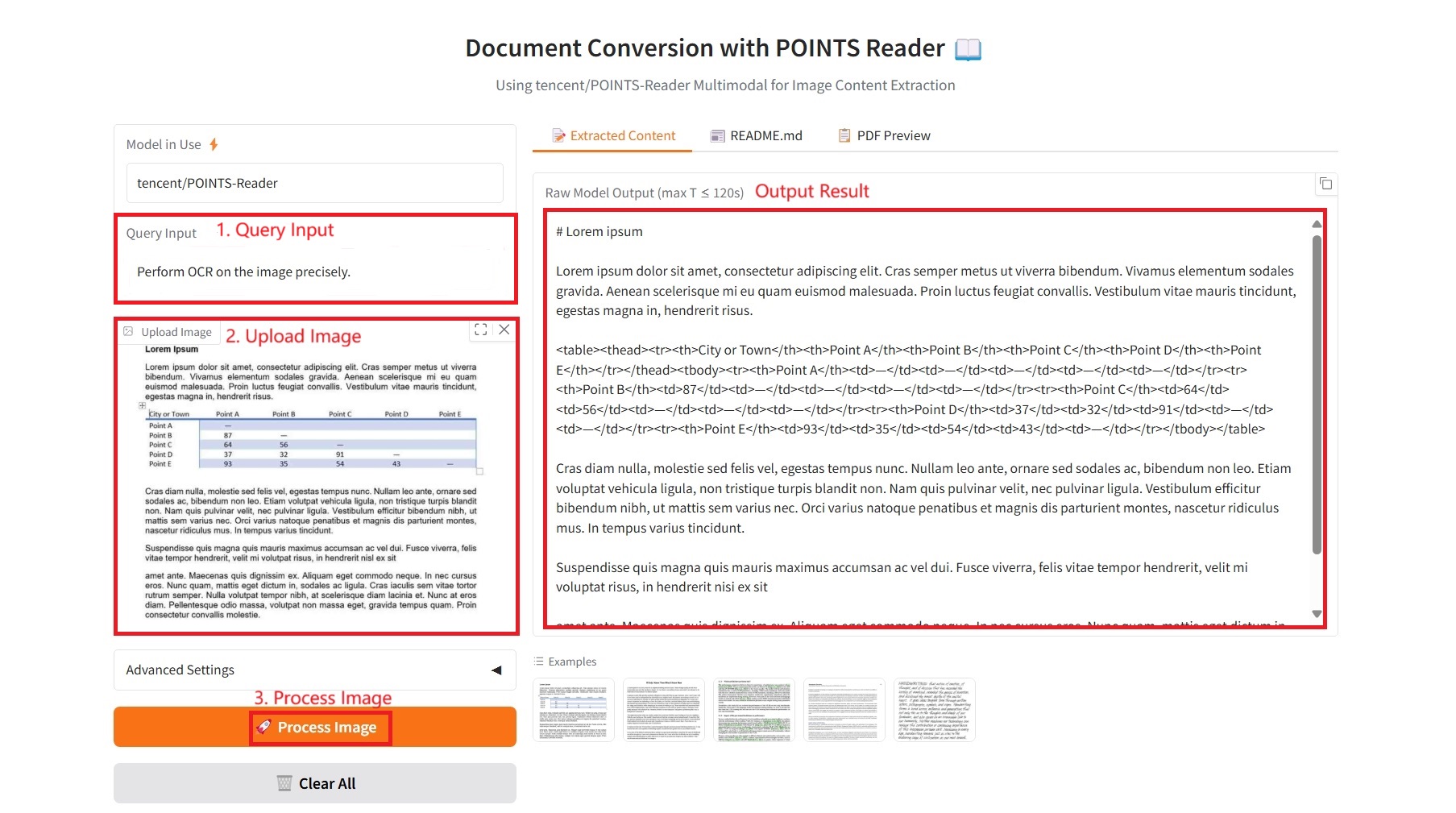
Specific parameters:
- Query Input: Enter text requirements.
- Image Upscale Factor: Increases the image size before processing. Can improve OCR of small text. Default: 1.0 (no change).
- Max New Tokens: The maximum length limit of the generated text, which controls the upper limit of the number of words in the output content.
- Top-p (nucleus sampling): a nucleus sampling parameter that selects the minimum word set with a cumulative probability of p for sampling to control output diversity.
- Top-k: Sample from the k candidate words with the highest probability. The larger the value, the more random the output; the smaller the value, the more certain the output.
- Temperature: Controls the randomness of the generated text. Higher values result in more random and diverse output, while lower values result in more deterministic and conservative output.
- Repetition penalty: A value greater than 1.0 will reduce the generation of duplicate content. The larger the value, the stronger the penalty.
- PDF Export Settings:
- Font Size: The font size of the text in the PDF, which controls the readability of the exported document.
- Line Spacing: The line spacing between paragraphs in a PDF affects the aesthetics and readability of the document.
- Text Alignment: The alignment of text in PDF, including left alignment, center alignment, right alignment, or justification.
- Image Size in PDF: The size of the image embedded in the PDF, including small, medium and large options.
2. README.md
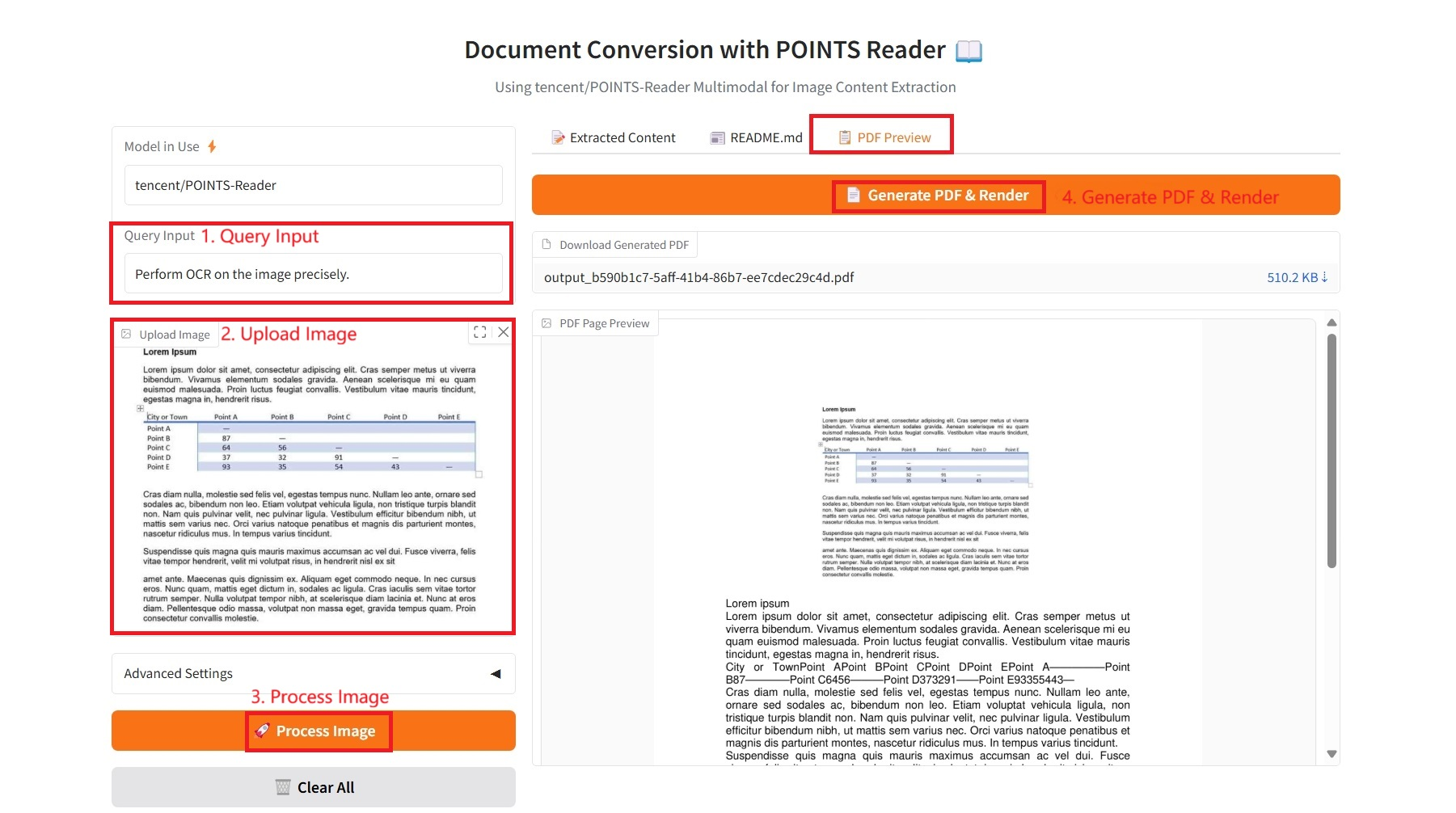
3. PDF Preview
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@article{points-reader, title={POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion}, author={Liu, Yuan and Zhongyin Zhao and Tian, Le and Haicheng Wang and Xubing Ye and Yangxiu You and Zilin Yu and Chuhan Wu and Zhou, Xiao and Yu, Yang and Zhou, Jie}, journal={EMNLP2025}, year={2025} } @article{liu2024points1,
title={POINTS1. 5: Building a Vision-Language Model towards Real World Applications},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Gao, Xinyu and Yu, Kavio and Yu, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2412.08443},
year={2024}
} @article{liu2024points,
title={POINTS: Improving Your Vision-language Model with Affordable Strategies},
author={Liu, Yuan and Zhao, Zhongyin and Zhuang, Ziyuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2409.04828},
year={2024}
}@article{liu2024rethinking,
title={Rethinking Overlooked Aspects in Vision-Language Models},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2405.11850},
year={2024}
}
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.