Command Palette
Search for a command to run...
MiniCPM-V 4.5: The Most Powerful edge-to-edge Multimodal Model
1. Tutorial Introduction

MiniCPM-V 4.5 is an extremely efficient edge-side AI model open-sourced in August 2025 by the Natural Language Processing Lab at Tsinghua University in collaboration with Wallfacer AI. MiniCPM-V 4.5 has 8 bytes of parameters. The model excels in multiple domains including image, video, and OCR, achieving breakthroughs particularly in high refresh rate video understanding, capable of processing high refresh rate videos and accurately recognizing content. The model supports a hybrid inference mode, balancing performance and response speed. MiniCPM-V 4.5 is edge-side deployment friendly, with low memory usage and fast inference speed, making it suitable for applications in automotive systems, robots, and other devices, setting a new benchmark for edge AI development. Related research papers are available. MiniCPM-V: A GPT-4V Level MLLM on Your Phone .
The computing resources used in this tutorial are a single RTX 4090 card.
2. Effect display
Image Understanding
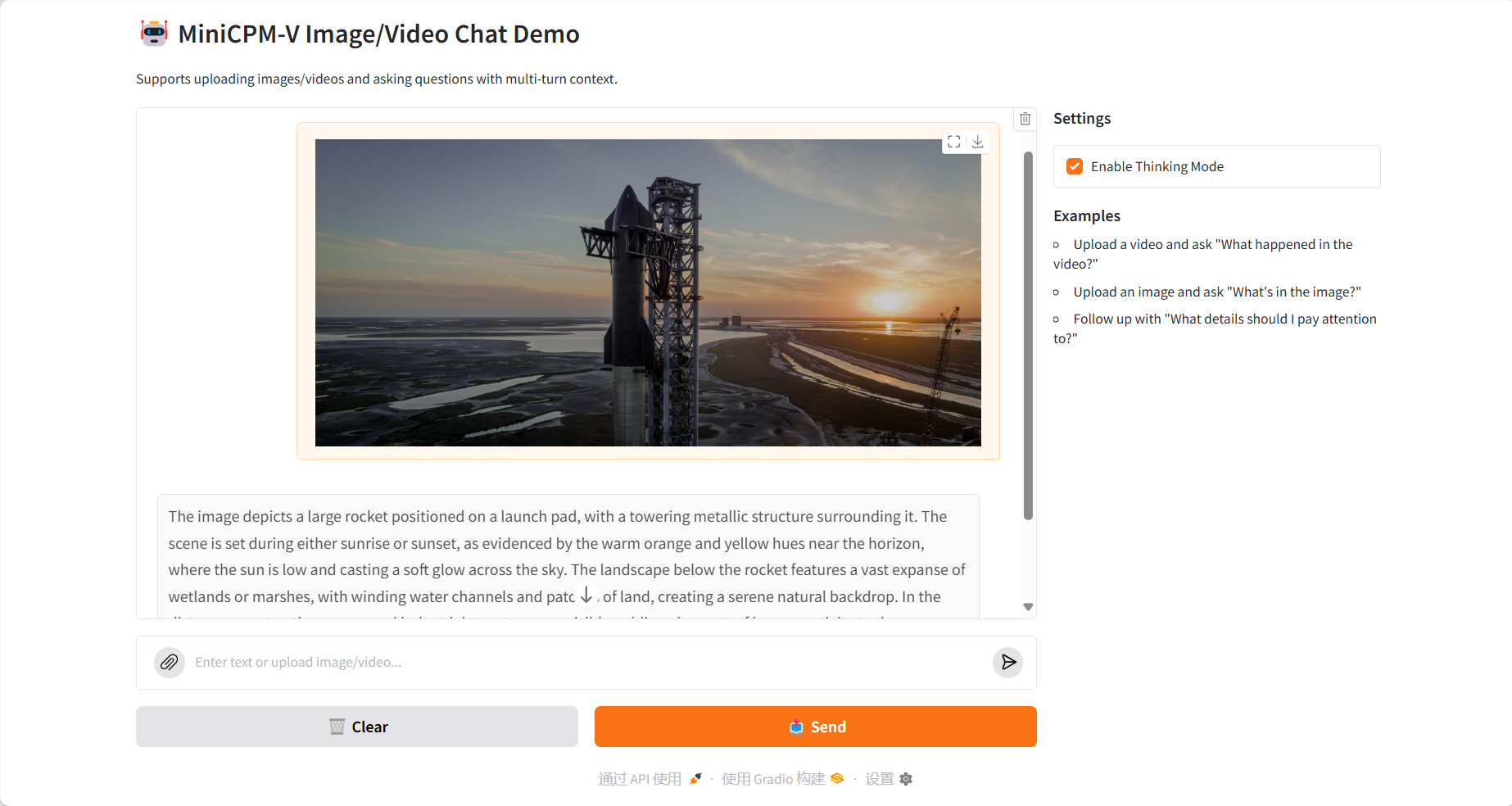
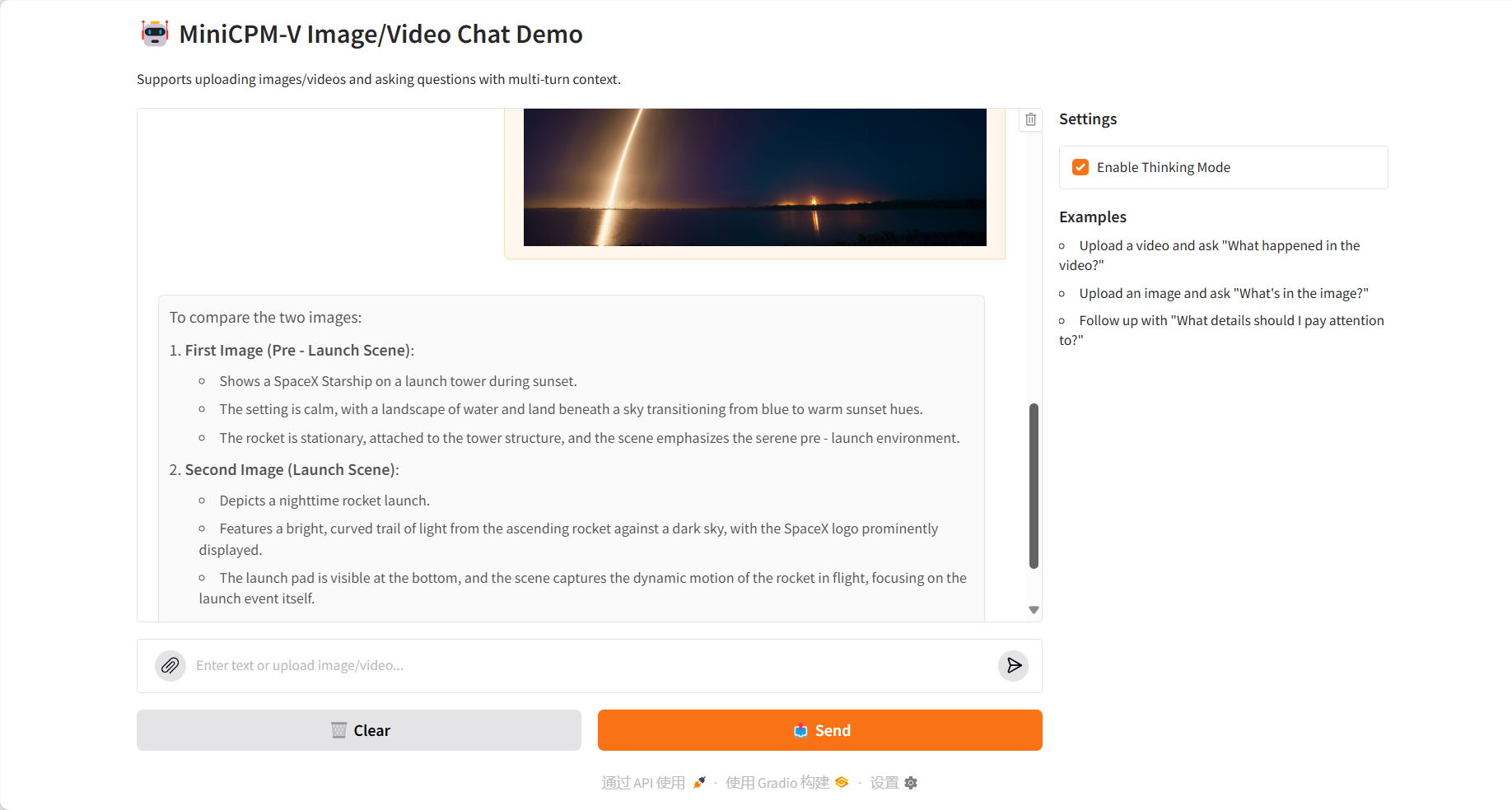
Multi-image comparison
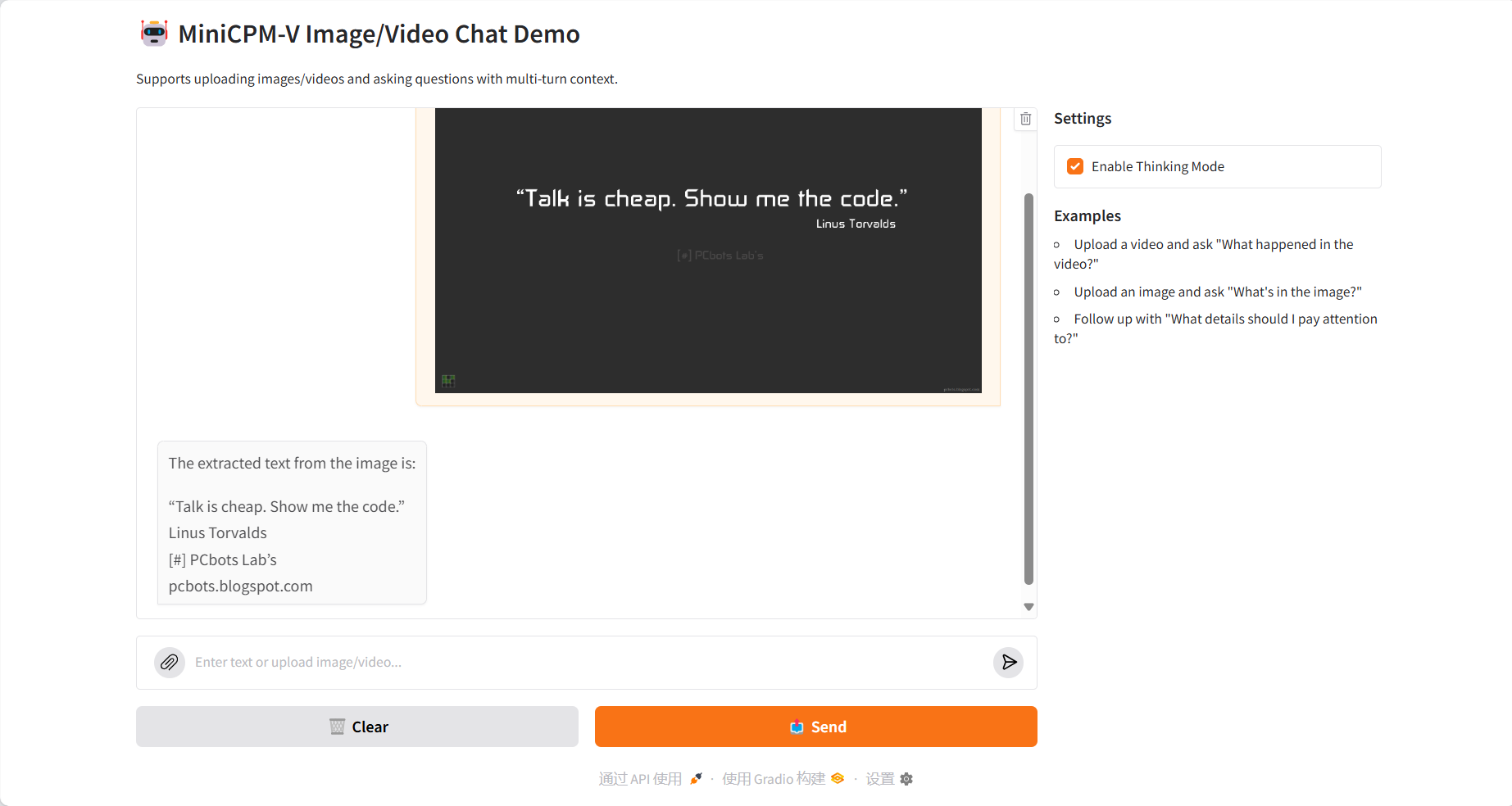
OCR text extraction
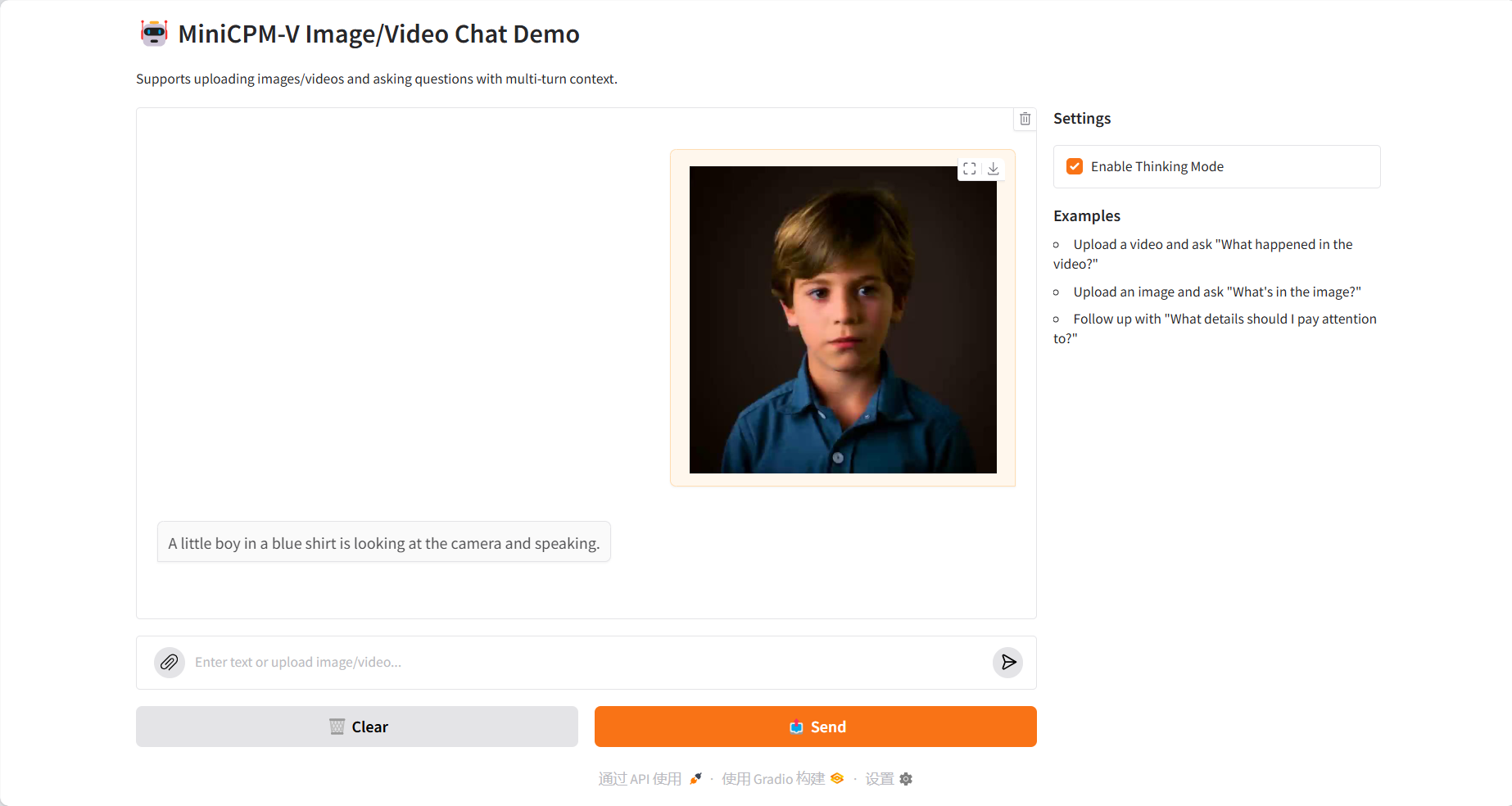
Video Understanding
3. Operation steps
1. Start the container
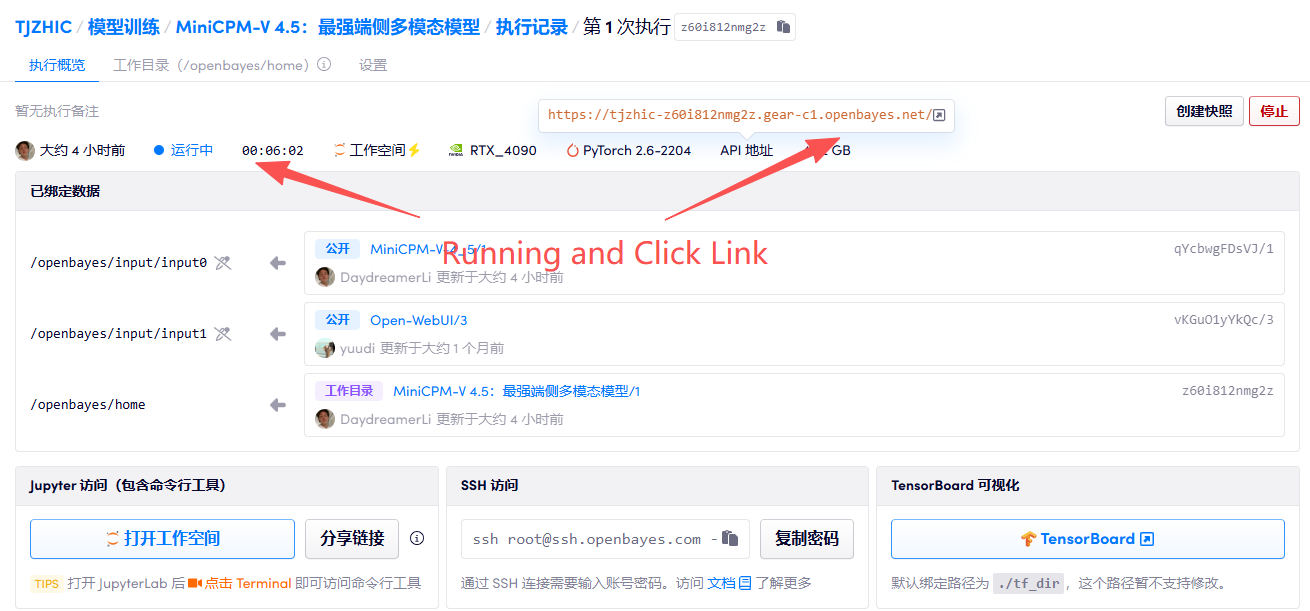
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
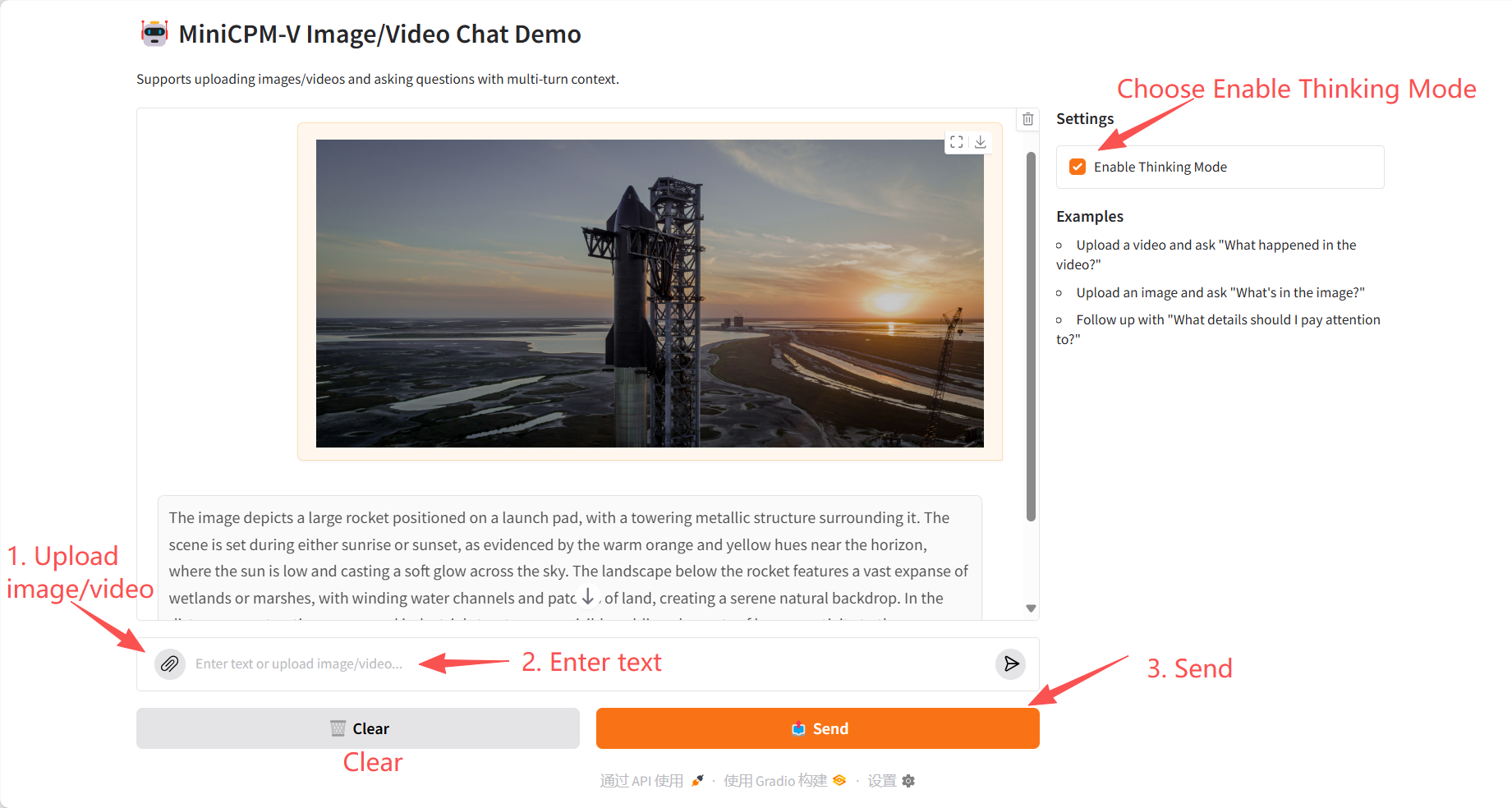
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={arXiv preprint arXiv:2408.01800},
year={2024}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.