Command Palette
Search for a command to run...
Pusa-VidGen Video Generation Model Demo
Date
Size
322.68 MB
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

Pusa V1, proposed by Yaofang-Liu's team on July 25, 2025, is a high-efficiency multimodal video generation model. Based on Vectorized Temporal Adaptation (VTA) technology, it solves the core problems of high training cost, low inference efficiency, and poor temporal consistency in traditional video generation models. Unlike traditional methods that rely on large-scale data and computing power, Pusa V1 achieves breakthrough optimizations based on Wan2.1-T2V-14B through a lightweight fine-tuning strategy: its training cost is only $500 (1/200th of similar models), the dataset requires only 4K samples (1/2500th of similar models), and training can be completed on eight 80 GB GPUs, significantly lowering the application threshold of video generation technology. Simultaneously, it possesses powerful multi-tasking capabilities, supporting not only text-driven video (T2V) and image-guided video (I2V), but also zero-shot tasks such as video completion, first and last frame generation, and cross-scene transitions, without requiring additional training for specific scenes. More importantly, its generation performance is particularly outstanding. Employing a short-step inference strategy (surpassing the baseline model in just 10 steps), it achieved a total score of 87.32% on the VBench-I2V platform, demonstrating excellent performance in dynamic detail reproduction (such as limb movements and lighting changes) and temporal coherence. Furthermore, the non-destructive adaptation mechanism implemented through VTA technology injects temporal dynamic capabilities into the base model while preserving the original model's image generation quality, achieving a "1+1>2" effect. At the deployment level, its low inference latency meets diverse needs from rapid preview to high-definition output, making it suitable for creative design, short video production, and other scenarios. Related paper results are... PUSA V1.0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation .
This tutorial uses dual-card RTX A6000 resources.
2. Project Examples
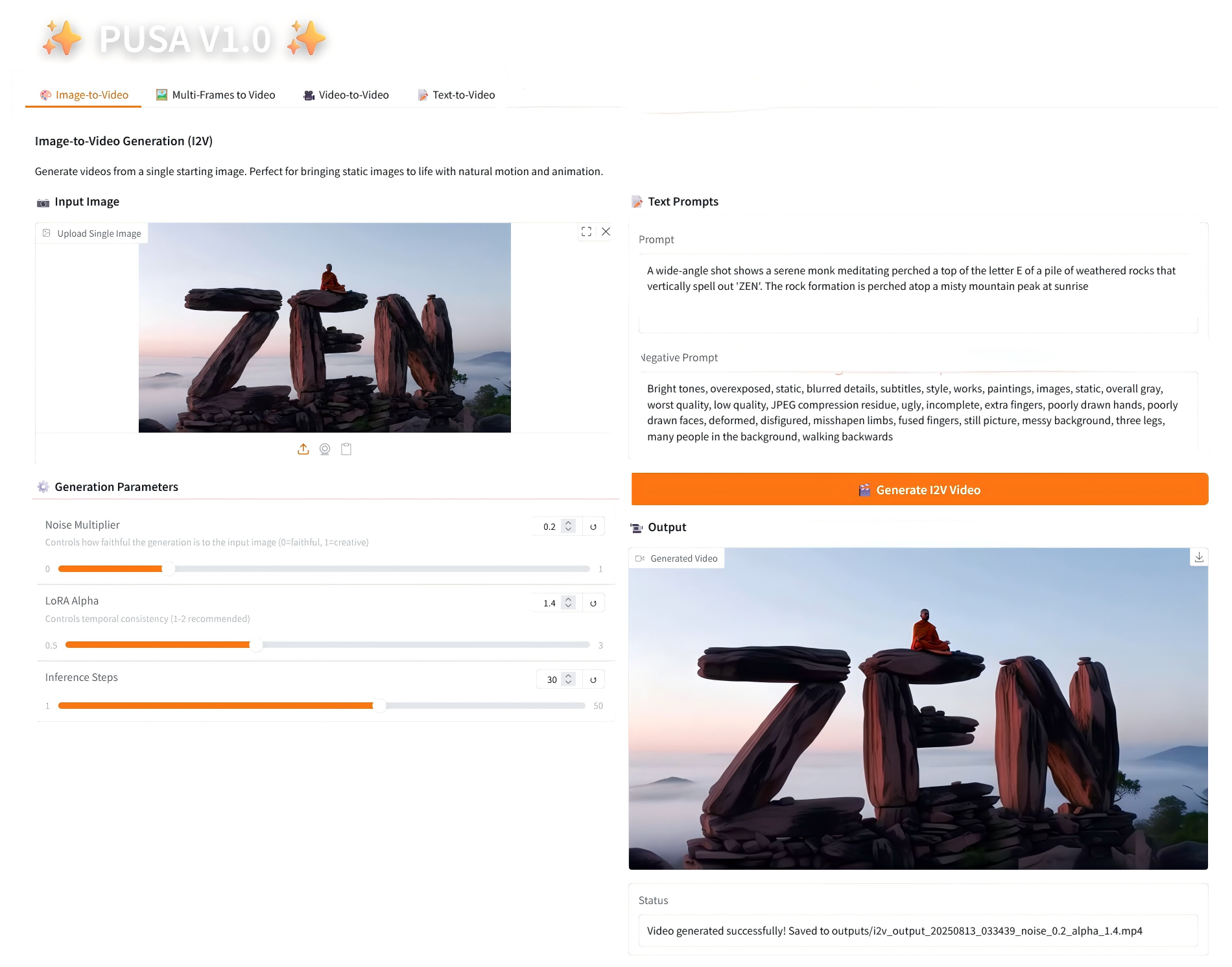
1. Image-to-Video
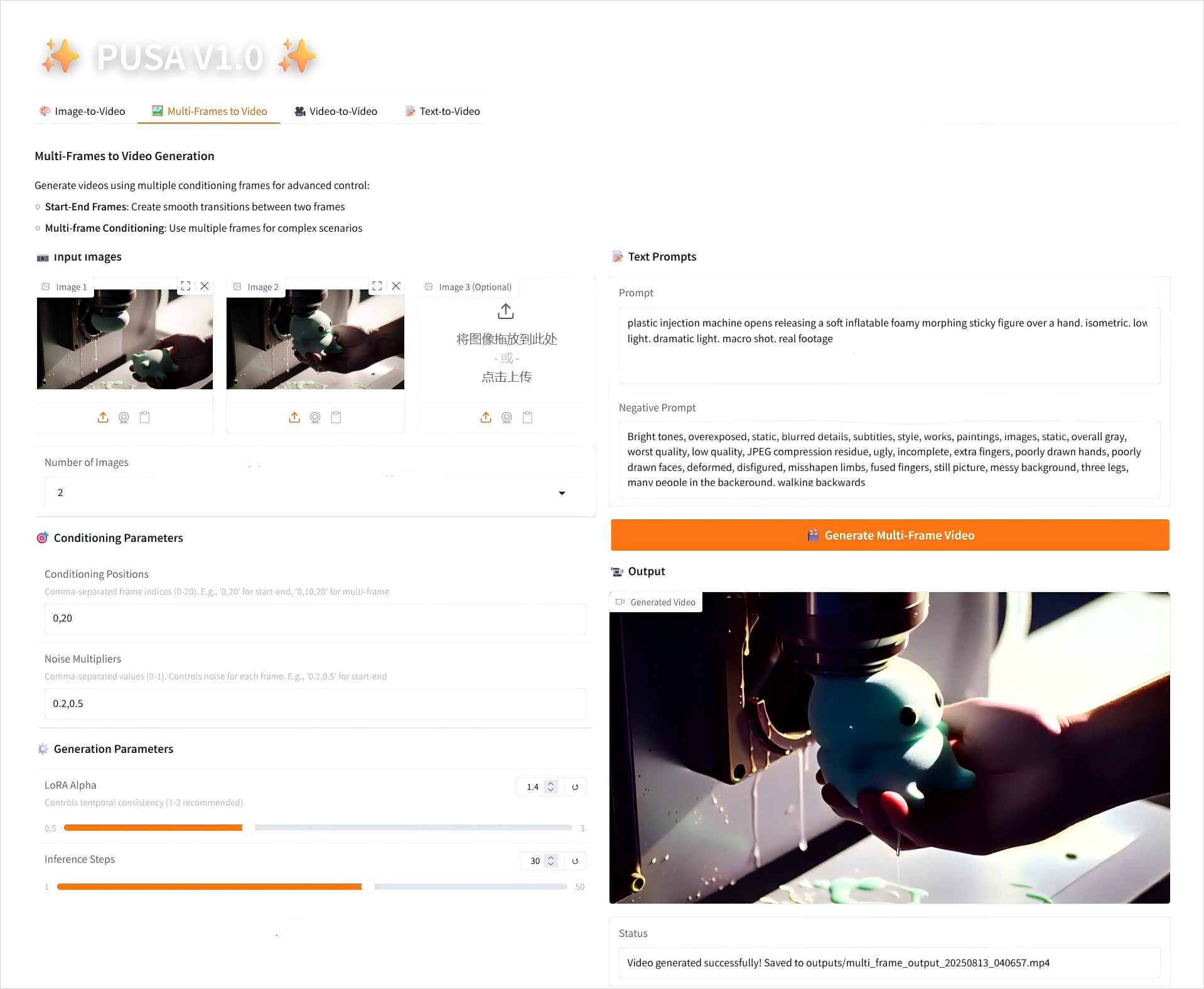
2. Multi-Frames to Video
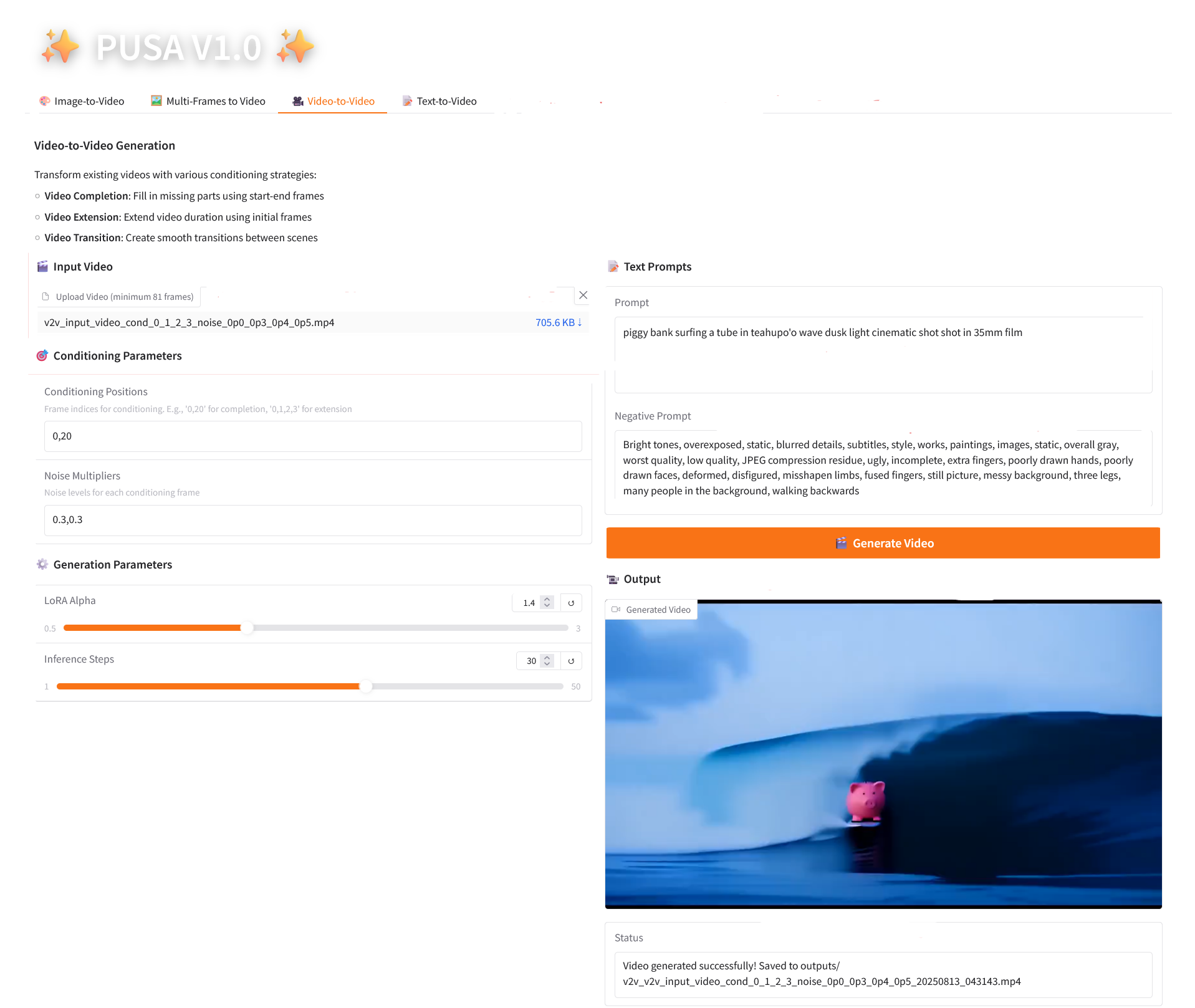
3. Video-to-Video
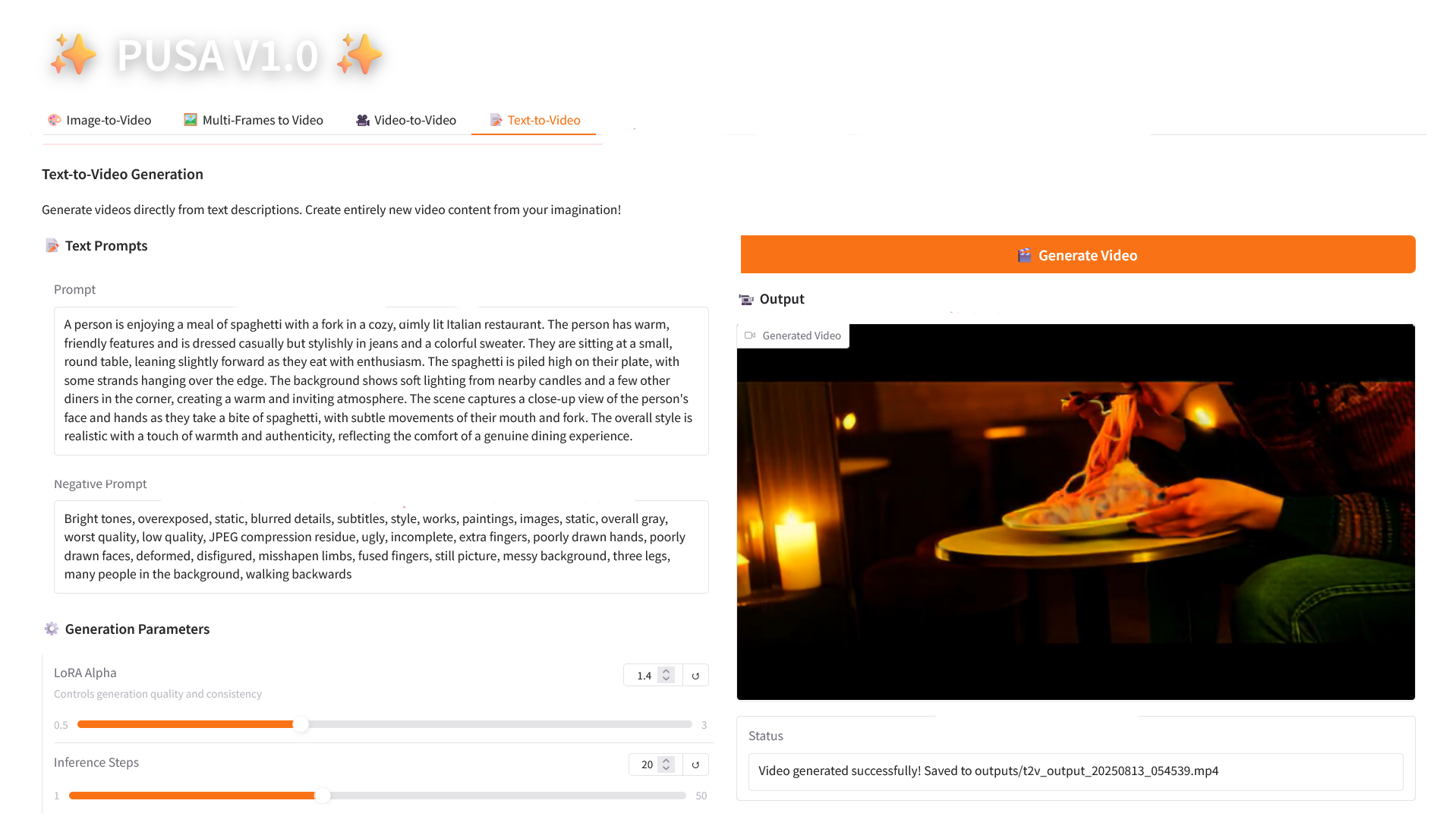
4. Text-to-Video
3. Operation steps
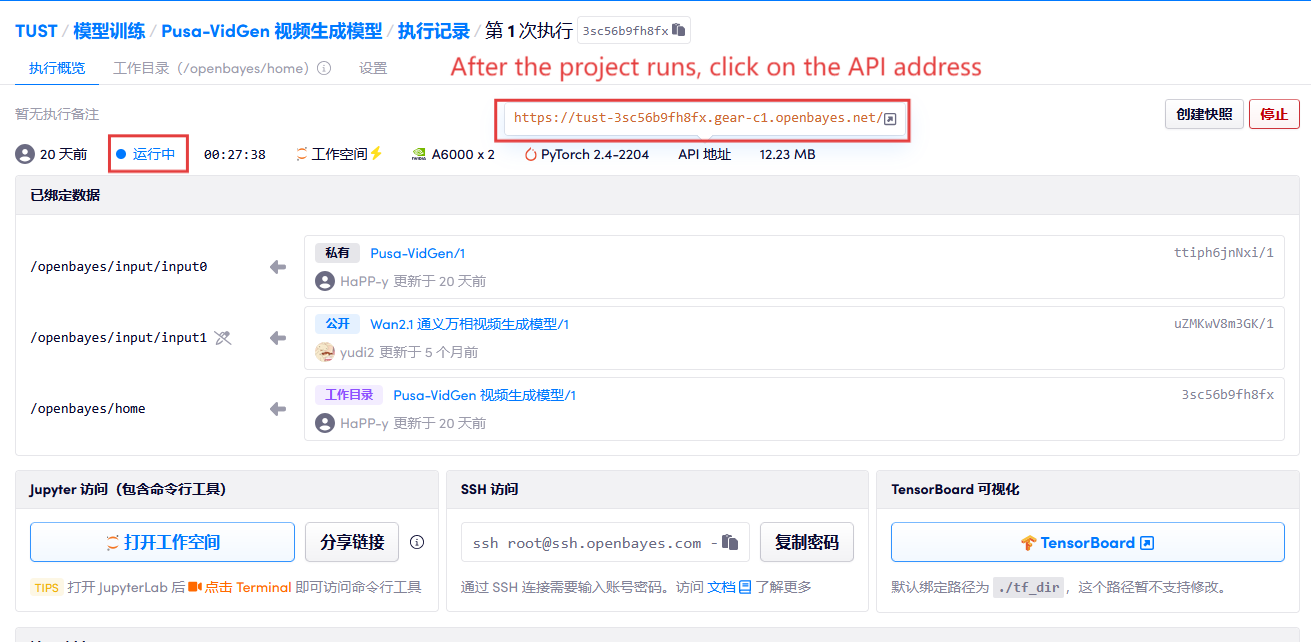
1. After starting the container, click the API address to enter the Web interface
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
2.1 Image-to-Video
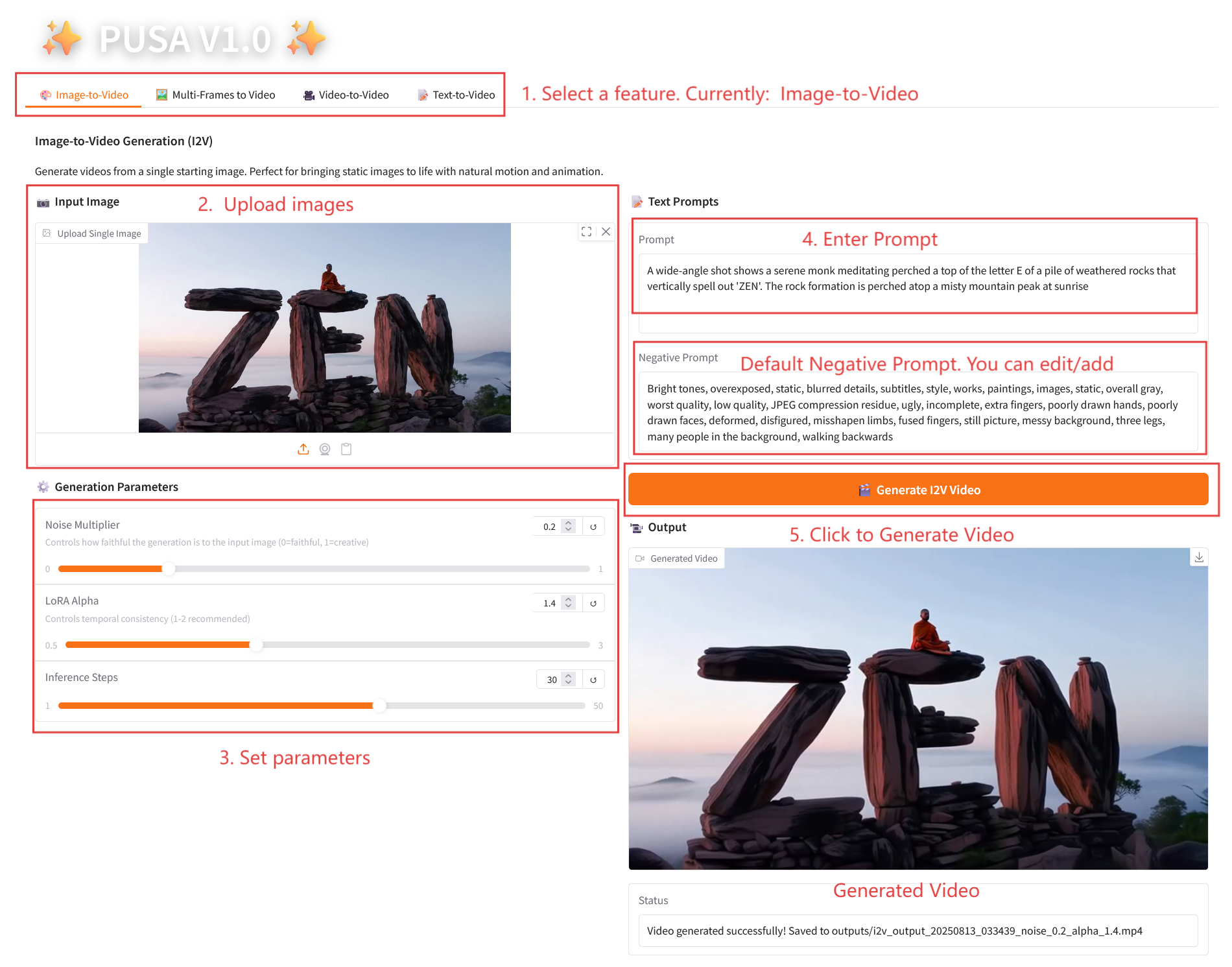
Parameter Description
- Generation Parameters
- Noise Multiplier: Adjustable from 0.0 to 1.0, default 0.2 (lower values are more faithful to the input image, higher values are more creative).
- LoRA Alpha: 0.1-5.0 adjustable, default 1.4 (controls style consistency, too high and it will be stiff, too low and it will lose coherence).
- Inference Steps: Adjustable from 1 to 50, default is 10 (the higher the number of steps, the richer the details, but the time consumed increases linearly).
2.2 Multi-Frames to Video
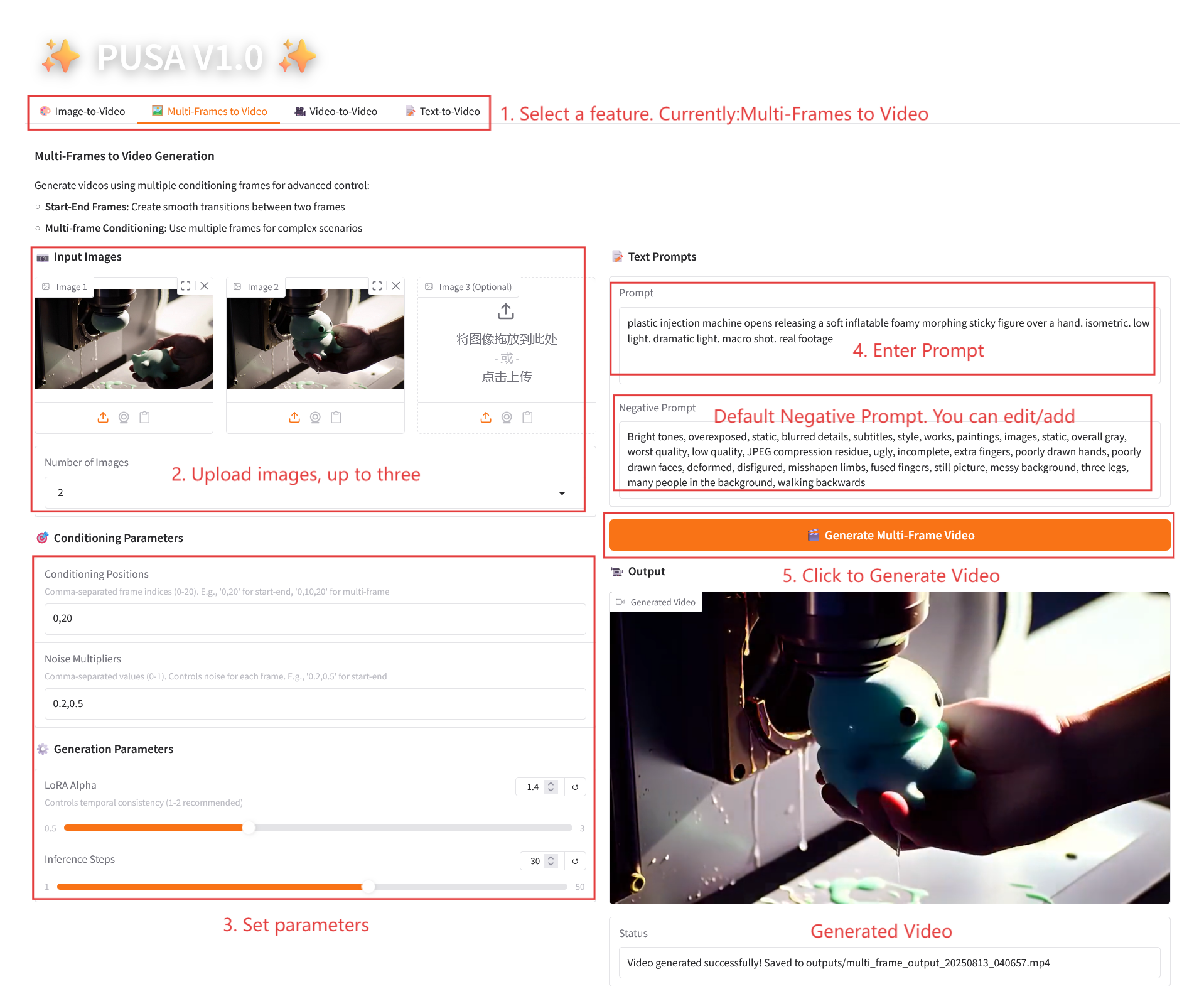
Parameter Description
- Conditioning Parameters
- Conditioning Positions: Comma-separated frame indices (e.g. "0,20" defines the time points of the keyframes in the video).
- Noise Multipliers: Comma-separated 0.0-1.0 values (e.g. "0.2,0.5", corresponding to the creative freedom of each keyframe, lower values are more faithful to the frame, higher values are more varied).
- Generation Parameters
- LoRA Alpha: 0.1-5.0 adjustable, default 1.4 (controls style consistency, too high and it will be stiff, too low and it will lose coherence).
- Inference Steps: Adjustable from 1 to 50, default is 10 (the higher the number of steps, the richer the details, but the time consumed increases linearly).
2.3 Video-to-Video
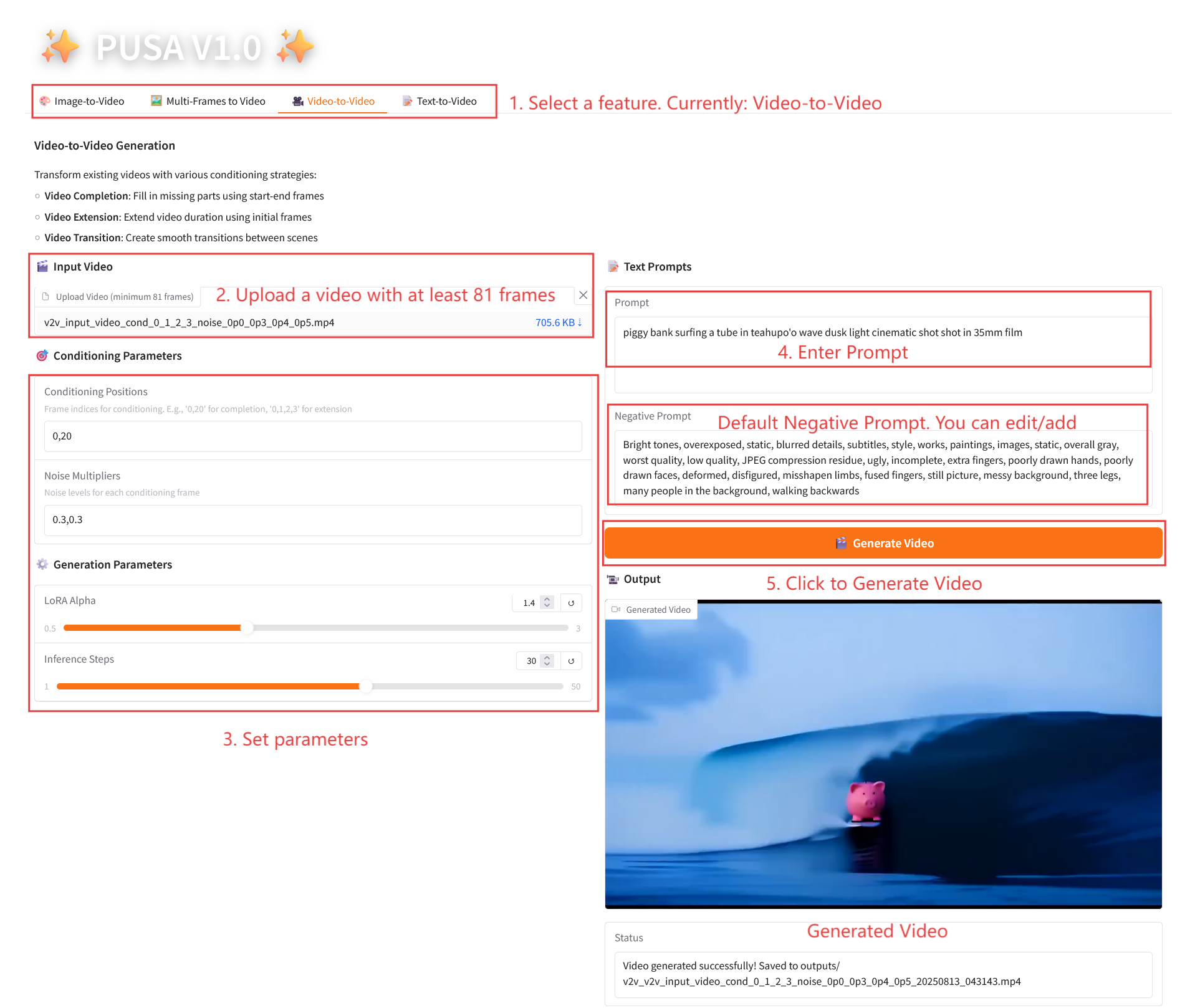
Parameter Description
- Conditioning Parameters
- Conditioning Positions: Comma-separated frame indices (e.g., "0,1,2,3", specifying the keyframe positions in the original video used for constraint generation, required).
- Noise Multipliers: Comma-separated 0.0-1.0 values (e.g. "0.0,0.3", corresponding to the degree of influence of each conditional frame, lower values are closer to the original frame, higher values are more flexible).
- Generation Parameters
- LoRA Alpha: 0.1-5.0 adjustable, default 1.4 (controls style consistency, too high and it will be stiff, too low and it will lose coherence).
- Inference Steps: Adjustable from 1 to 50, default is 10 (the higher the number of steps, the richer the details, but the time consumed increases linearly).
2.4 Text-to-Video
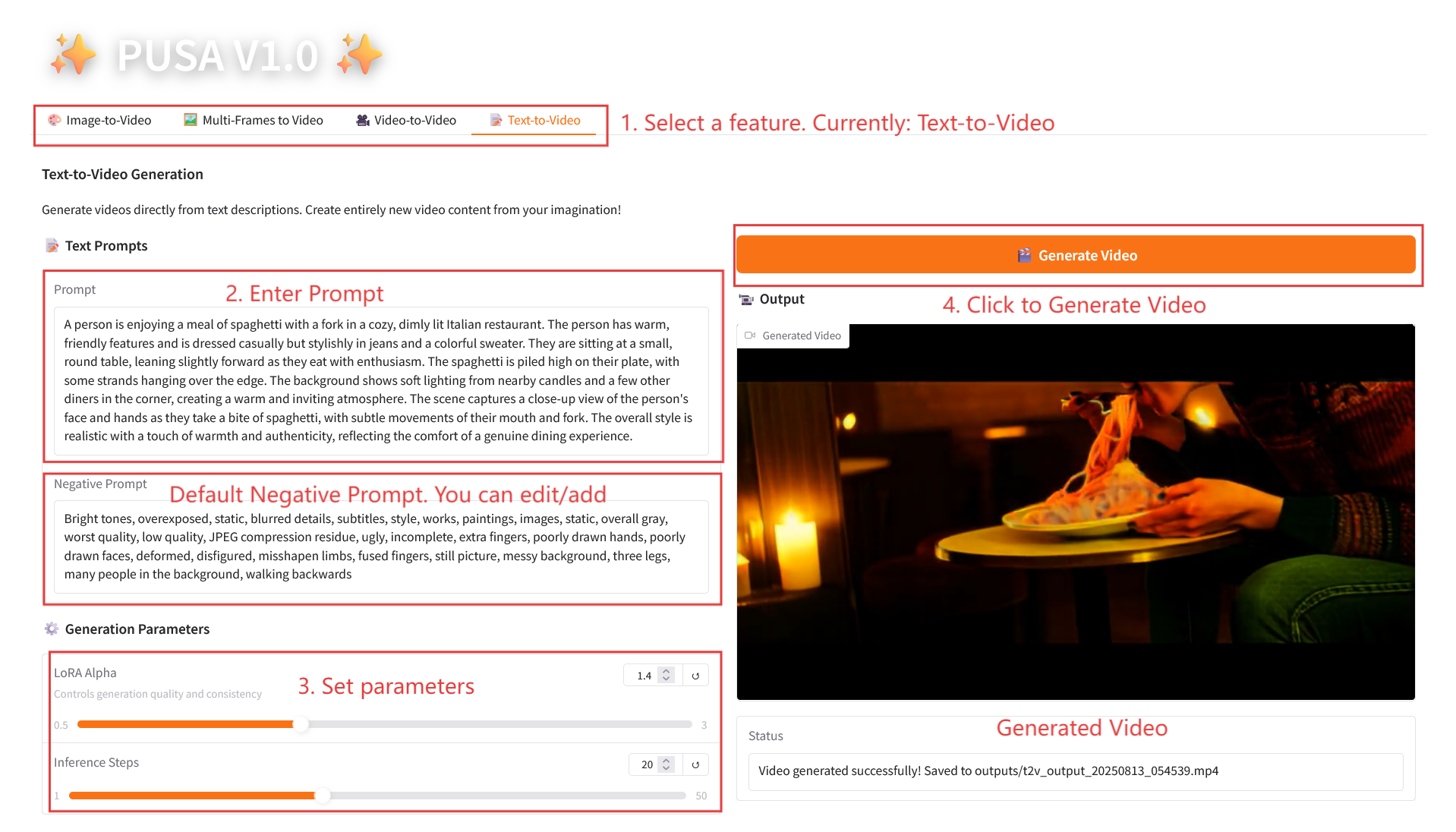
Parameter Description
- Generation Parameters
- LoRA Alpha: 0.1-5.0 adjustable, default 1.4 (controls style consistency, too high and it will be stiff, too low and it will lose coherence).
- Inference Steps: Adjustable from 1 to 50, default is 10 (the higher the number of steps, the richer the details, but the time consumed increases linearly).
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.