Command Palette
Search for a command to run...
One-click Deployment GLM-4.1V-9B-Thinking
Date
Paper URL
License
Apache 2.0
GitHub
1. Tutorial Introduction

GLM-4.1V-9B-Thinking is an open-source visual language model released on July 2, 2025, by Zhipu AI in collaboration with a team from Tsinghua University. Designed specifically for complex cognitive tasks, it supports multimodal inputs such as images, videos, and documents. Based on the GLM-4-9B-0414 base model, GLM-4.1V-9B-Thinking introduces a thinking paradigm and comprehensively enhances the model's capabilities through Curriculum Sampling (RLCS), achieving the highest performance among visual language models with 10B parameters. In 18 leaderboard tasks, it matches or even surpasses Qwen-2.5-VL-72B, which has 8 times the number of parameters. Related research papers are available. GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning .
The computing resources of this tutorial use a single RTX A6000 card. This tutorial supports text conversations, pictures, videos, PDF, and PPT understanding.
2. Effect display
Text Conversation
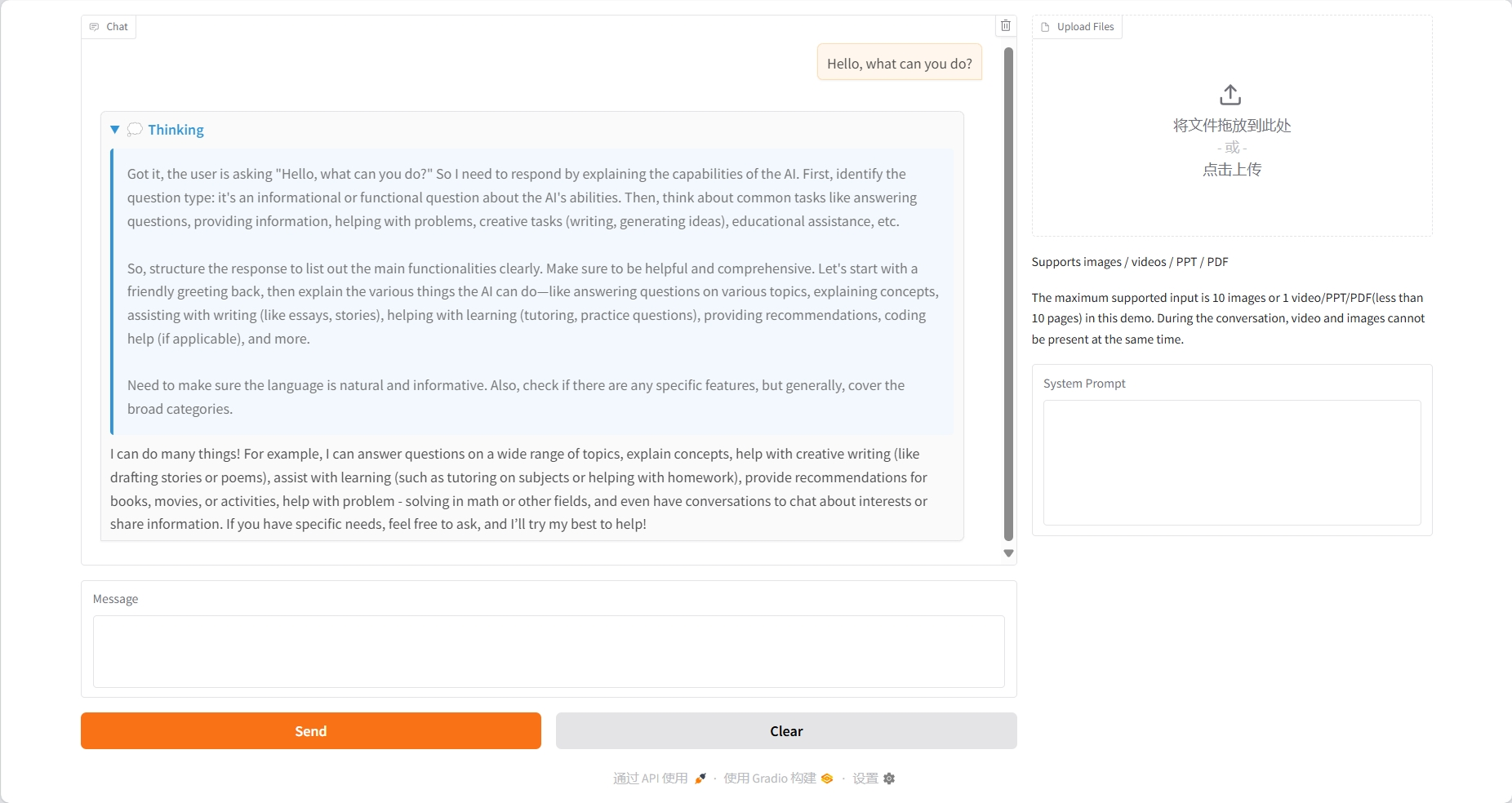
Image understanding
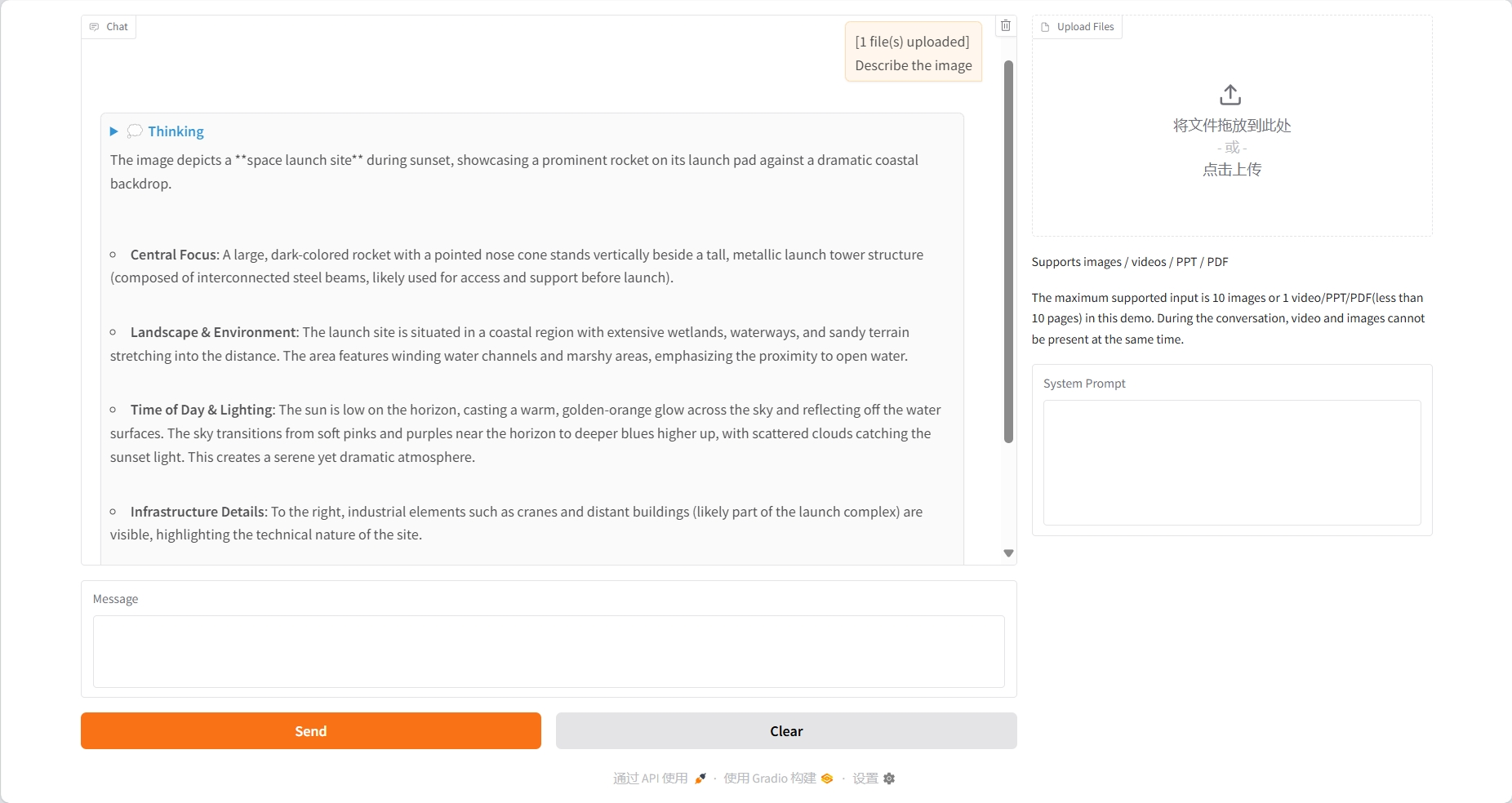
Video Understanding
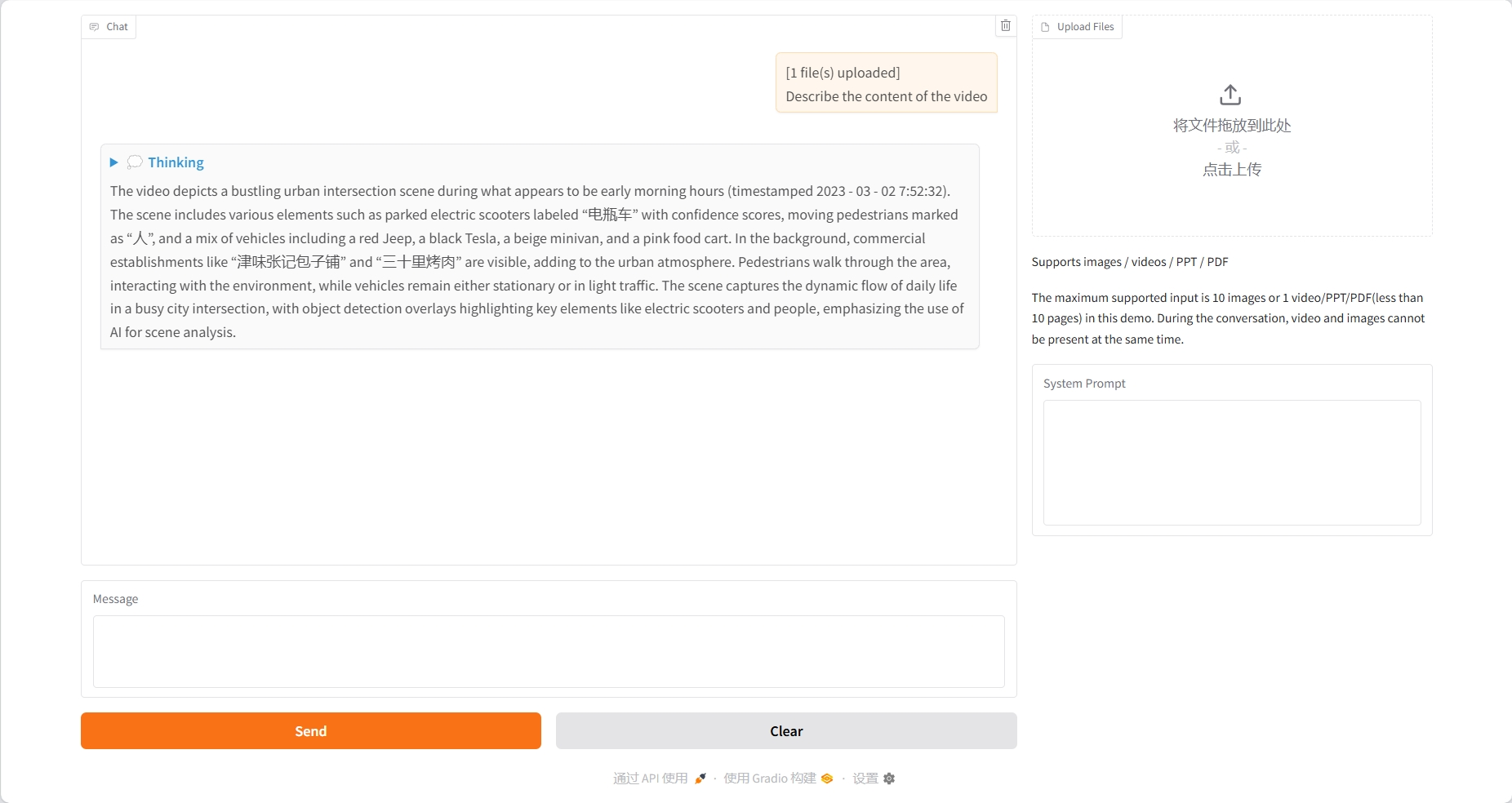
PDF Understanding
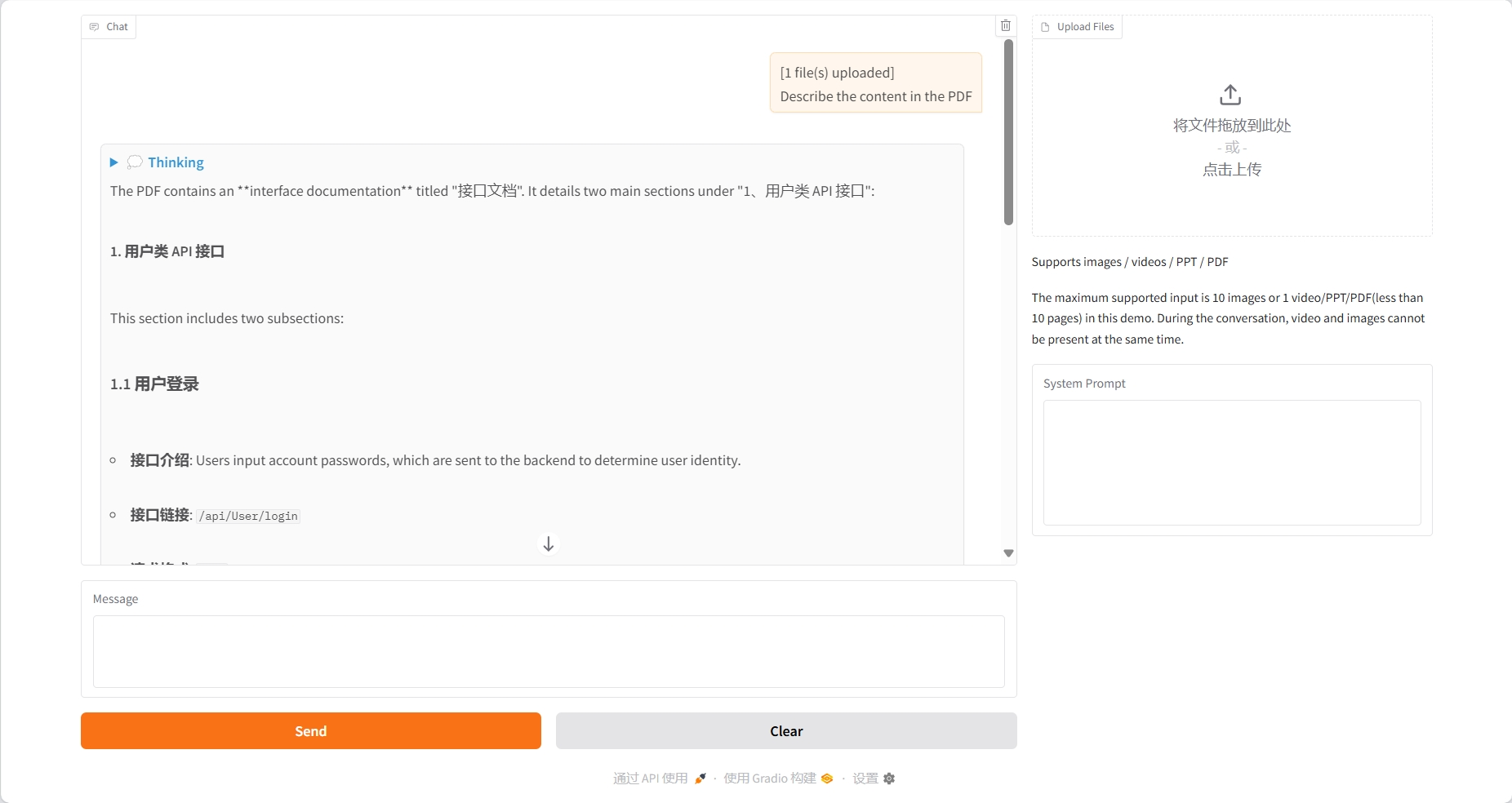
PPT understanding
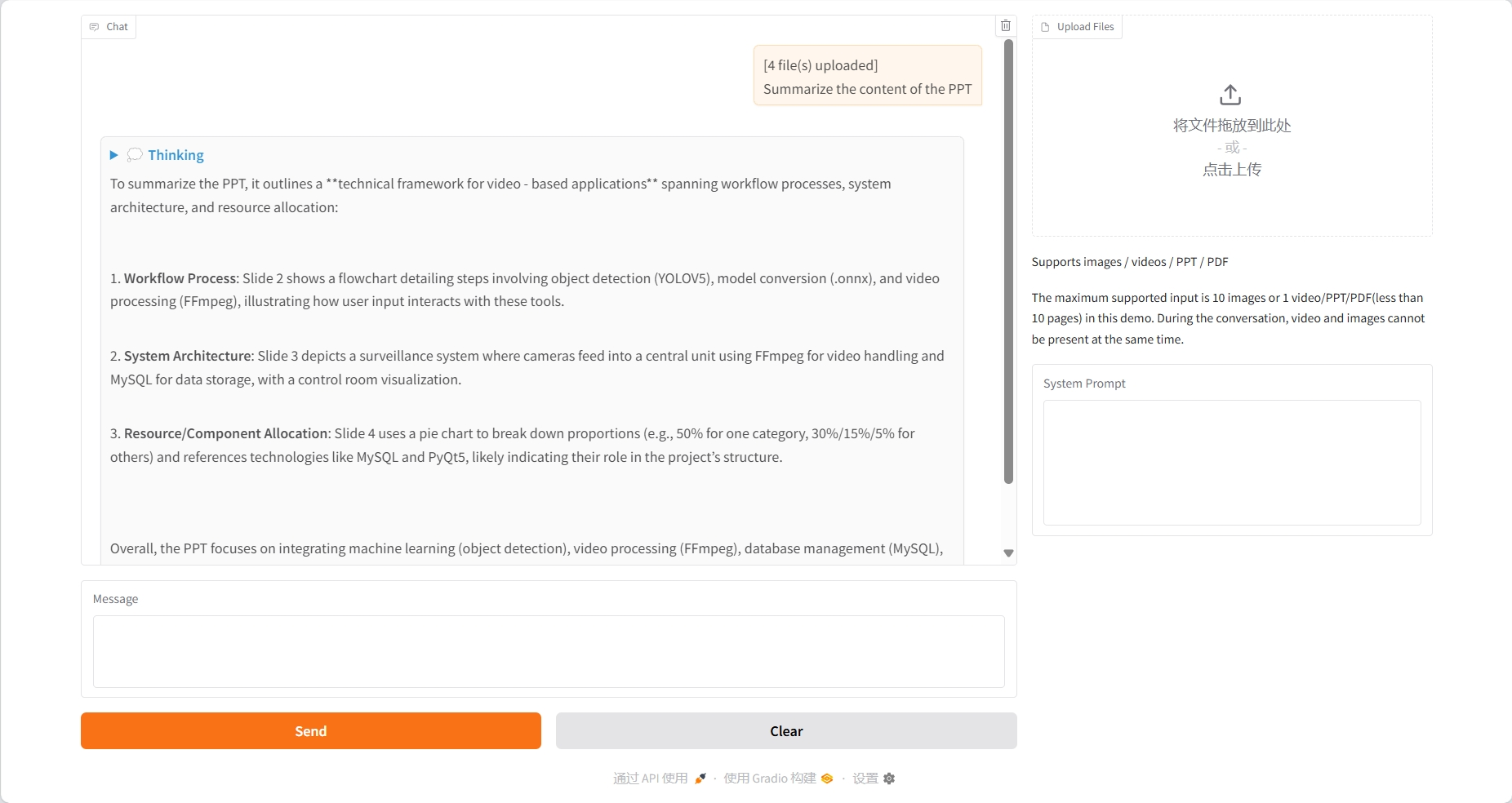
3. Operation steps
1. Start the container
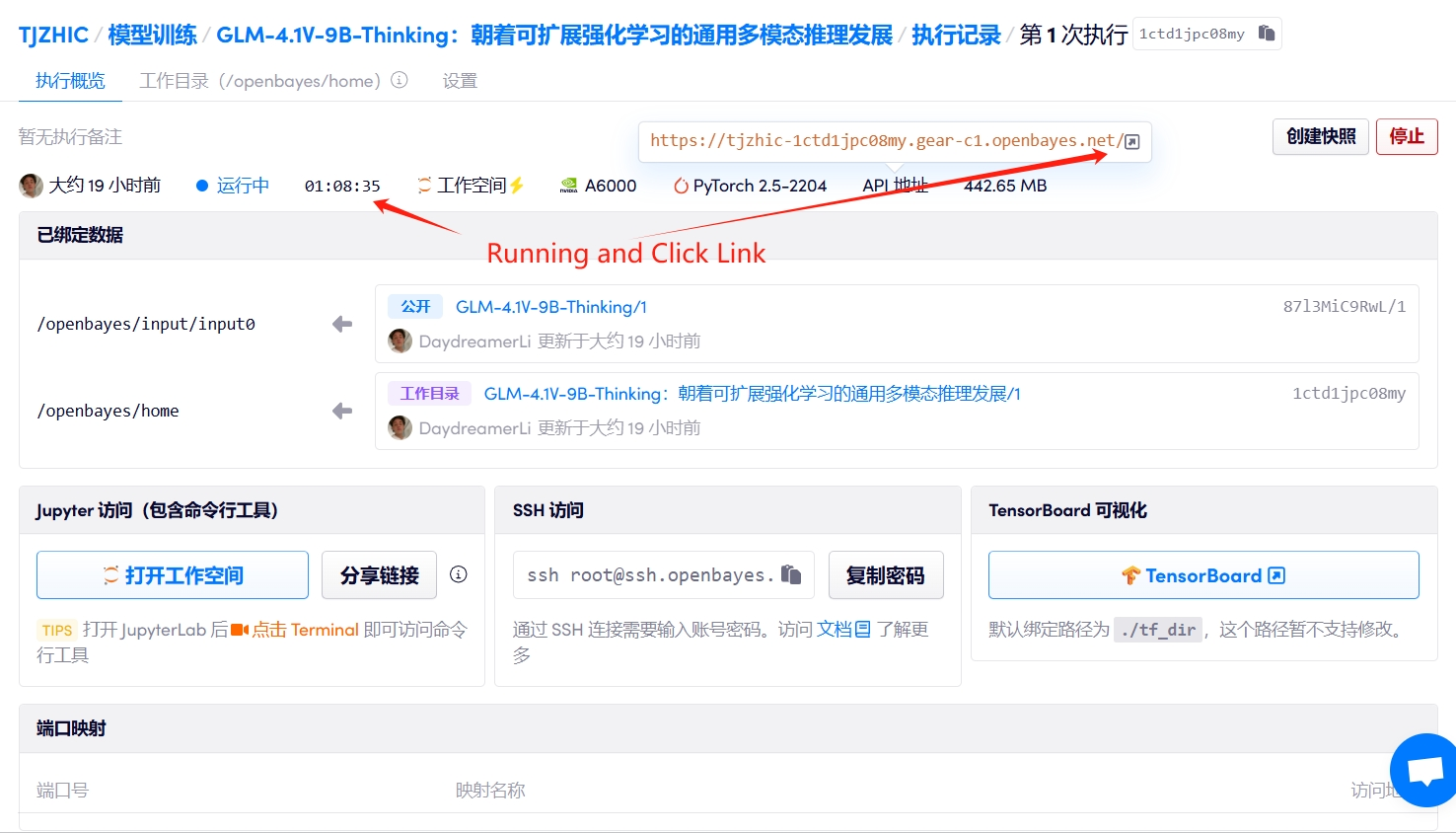
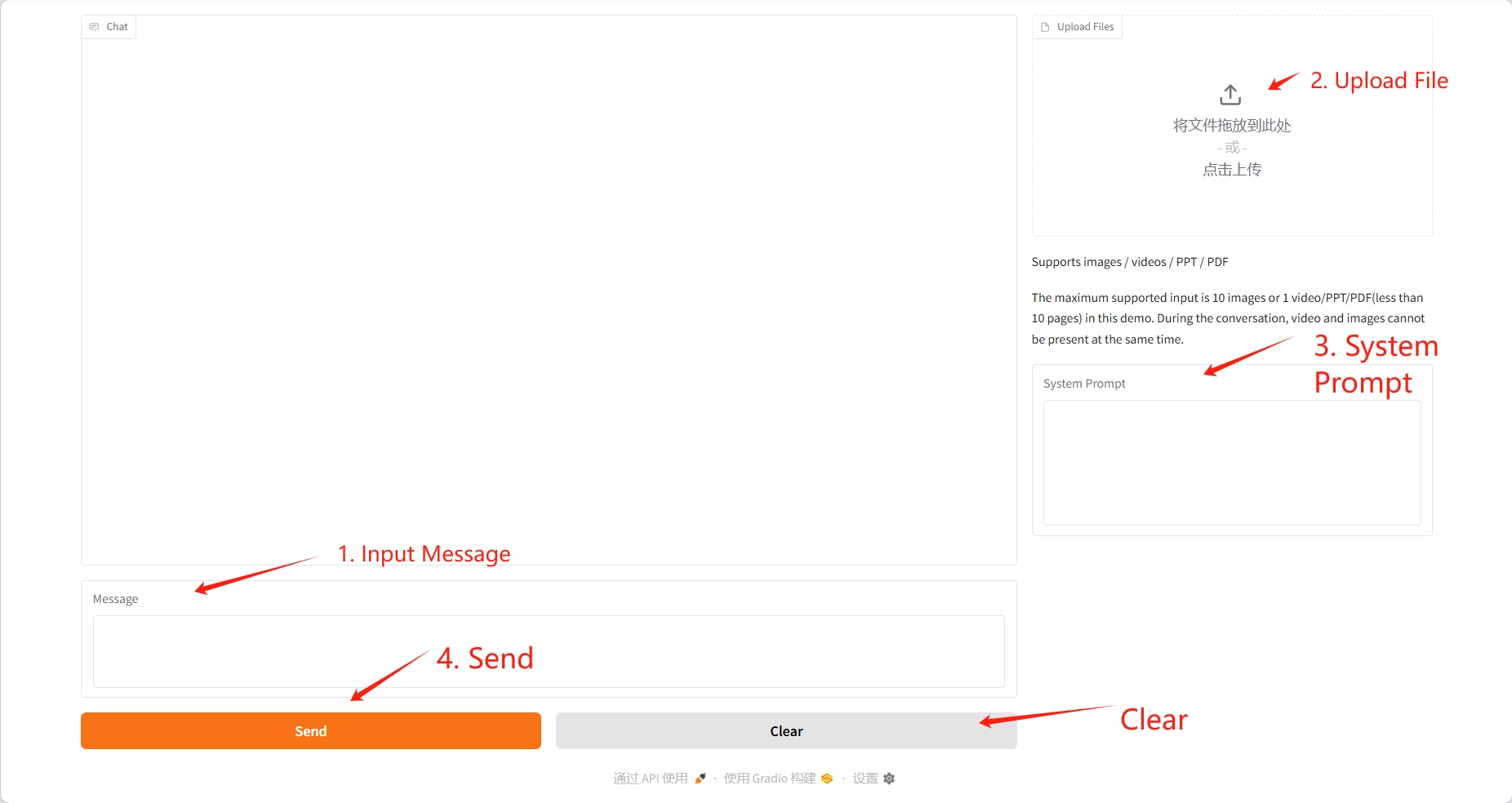
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
The uploaded video should not exceed 10 seconds, and the PDF and PPT should not exceed 10 pages. During the conversation, the video and the picture cannot exist at the same time. It is recommended to clear the operation after each conversation.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@misc{glmvteam2025glm41vthinkingversatilemultimodalreasoning,
title={GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={GLM-V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Wenkai Li and Wei Jia and Xin Lyu and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuxuan Zhang and Zhanxiao Du and Zhenyu Hou and Zhao Xue and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.