Command Palette
Search for a command to run...
EX-4D: Generate Free View From Monocular Video
Date
Size
89.06 MB
Tags
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

EX-4D, released on July 3, 2025, by Pico, a team under ByteDance, is a novel 4D video generation framework. It can generate high-quality 4D videos from monocular video input under extreme viewpoints. The framework is based on a unique Deep Waterproof Mesh (DW-Mesh) representation, explicitly modeling visible and occluded regions to ensure geometric consistency under extreme camera poses. The framework uses a simulated occlusion masking strategy to generate effective training data from monocular video and synthesizes physically consistent and temporally coherent videos using a lightweight LoRA-based video diffusion adapter. EX-4D significantly outperforms existing methods under extreme viewpoints, providing a new solution for 4D video generation. Related research papers are available. EX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh .
This tutorial uses a single RTX A6000 card as the resource.
2. Project Examples

3. Operation steps
1. After starting the container, click the API address to enter the Web interface
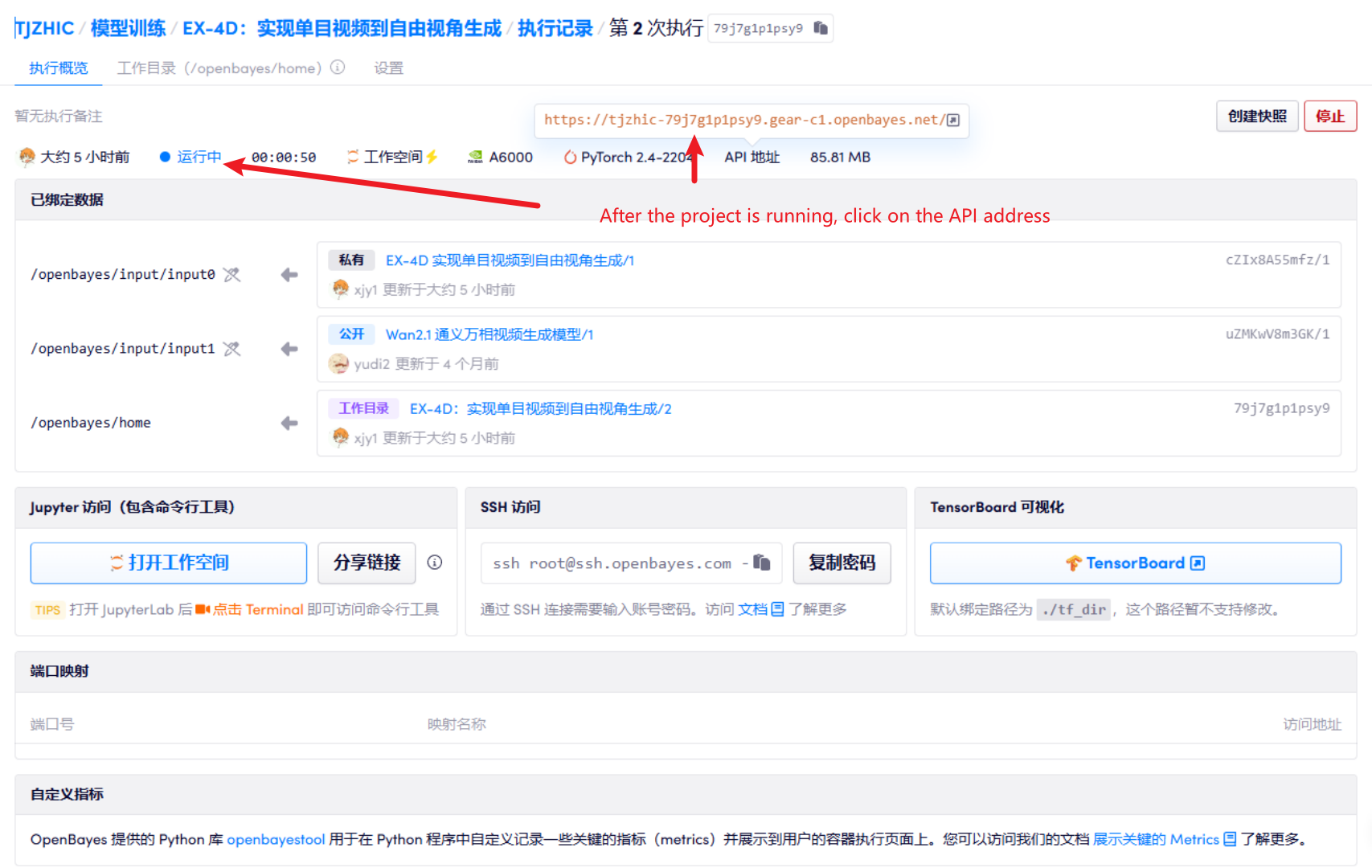
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
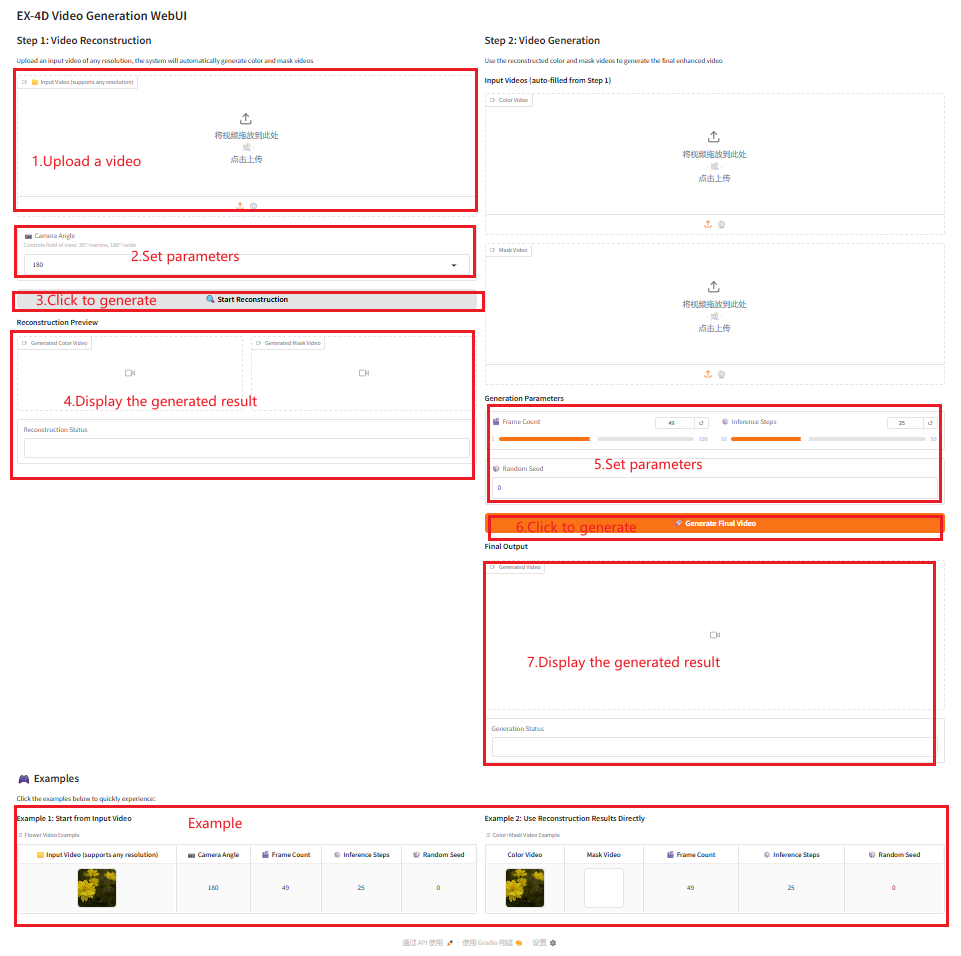
Parameter Description
- Camera Angle: Camera angle, 30°-180°. The larger the angle, the wider the field of view.
- Frame Count: Number of video frames.
- Inference Steps: Inference steps.
- Random Seed: Random seed.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@misc{hu2025ex4dextremeviewpoint4d,
title={EX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh},
author={Tao Hu and Haoyang Peng and Xiao Liu and Yuewen Ma},
year={2025},
eprint={2506.05554},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05554},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.