Command Palette
Search for a command to run...
PlayDiffusion: Open Source Audio Local Editing Model
Date
Size
1.35 MB
Tags
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

Key features:
- Partial audio editing: supports partial replacement, modification or deletion of audio without regenerating the entire audio segment, keeping the voice natural and seamless.
- Efficient TTS: When masking the entire audio, as an efficient TTS model, the inference speed is 50 times faster than traditional TTS, and the speech naturalness and consistency are better.
- Maintain speech continuity: Preserve context when editing to ensure speech continuity and consistent speaker timbre.
- Dynamic voice modification: Automatically adjust voice pronunciation, tone and rhythm according to new text, suitable for scenarios such as real-time interaction.
Technical principle:
- Audio encoding: Encodes the input audio sequence into a discrete sequence of tokens, where each token represents a unit of audio. Applicable to real speech and audio generated by text-to-speech models.
- Mask processing: When a part of the audio needs to be modified, mark the part as a mask to facilitate subsequent processing.
- Diffusion Model Denoising: Denoise the masked region based on a diffusion model that updates the text. The diffusion model generates a high-quality sequence of audio tokens based on step-by-step noise removal. All tokens are generated simultaneously using a non-autoregressive method and refined based on a fixed number of denoising steps.
- Decoding to audio waveform: The generated token sequence is converted back to speech waveform based on the BigVGAN decoder model to ensure that the final output speech is natural and coherent.
This tutorial uses a single RTX A6000 computing resource and provides three examples for testing: Inpaint, Text to Speech, and Voice Conversion. This tutorial only supports English.
2. Effect display
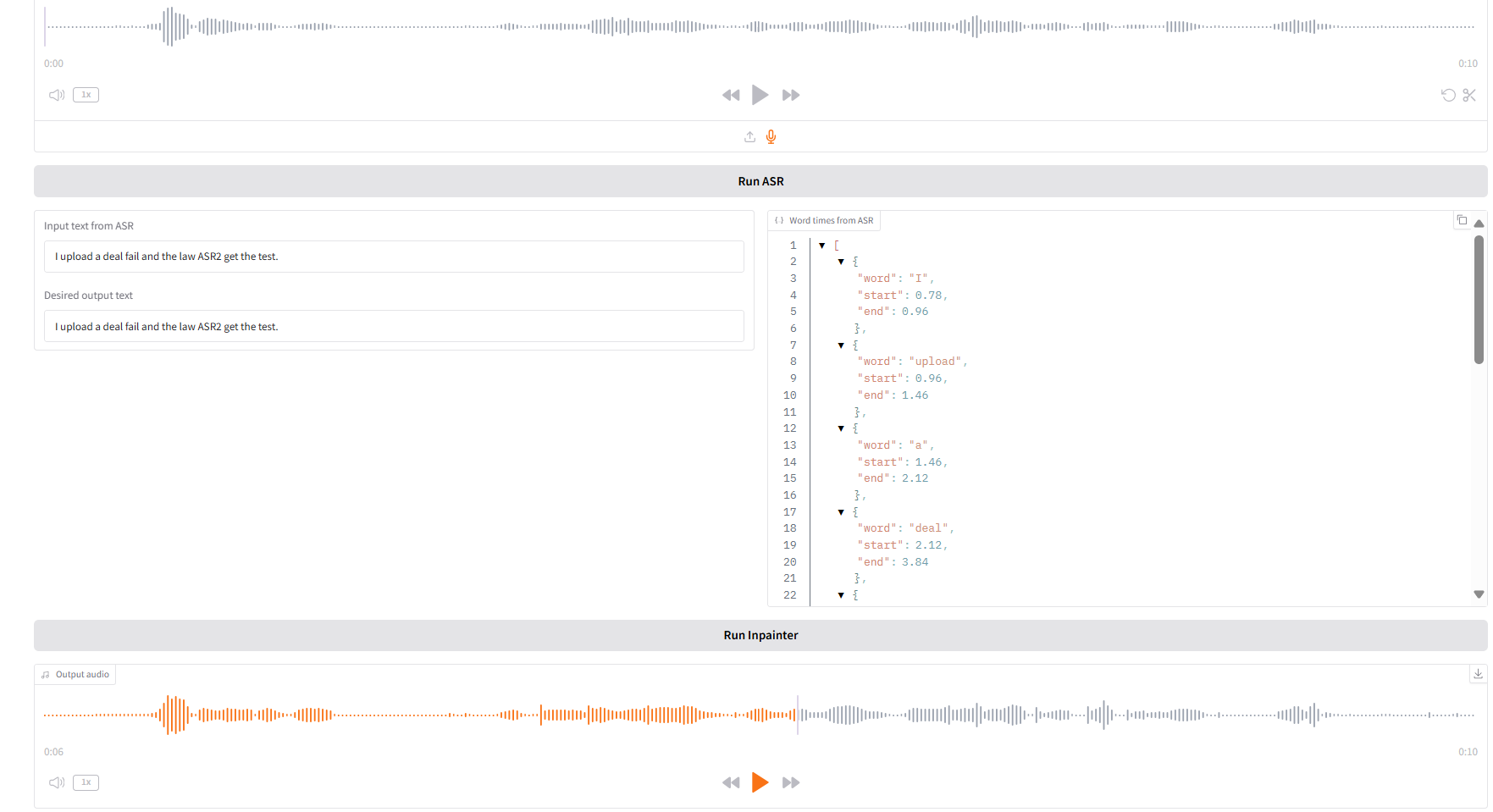
1. Inpaint
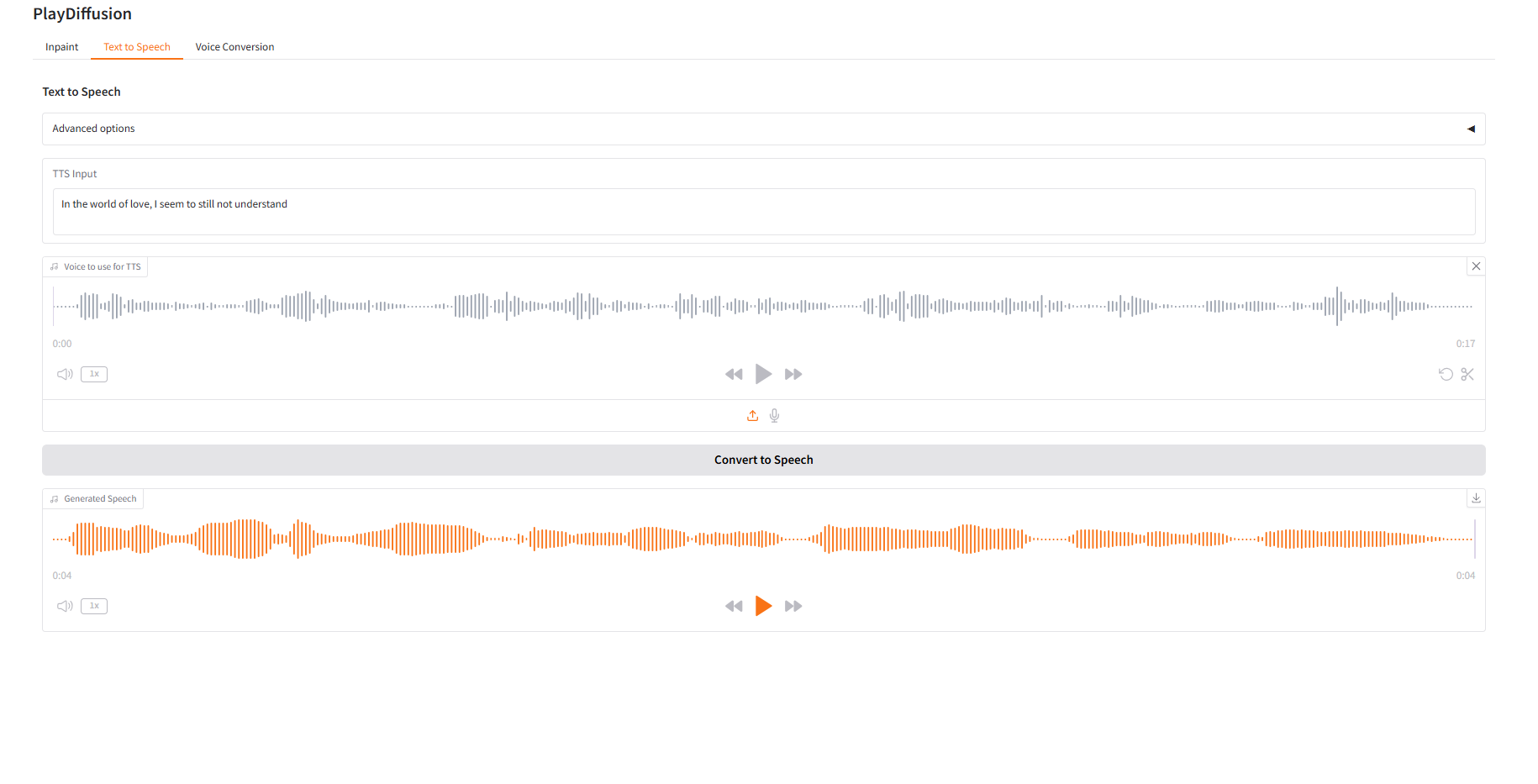
2. Text to Speech
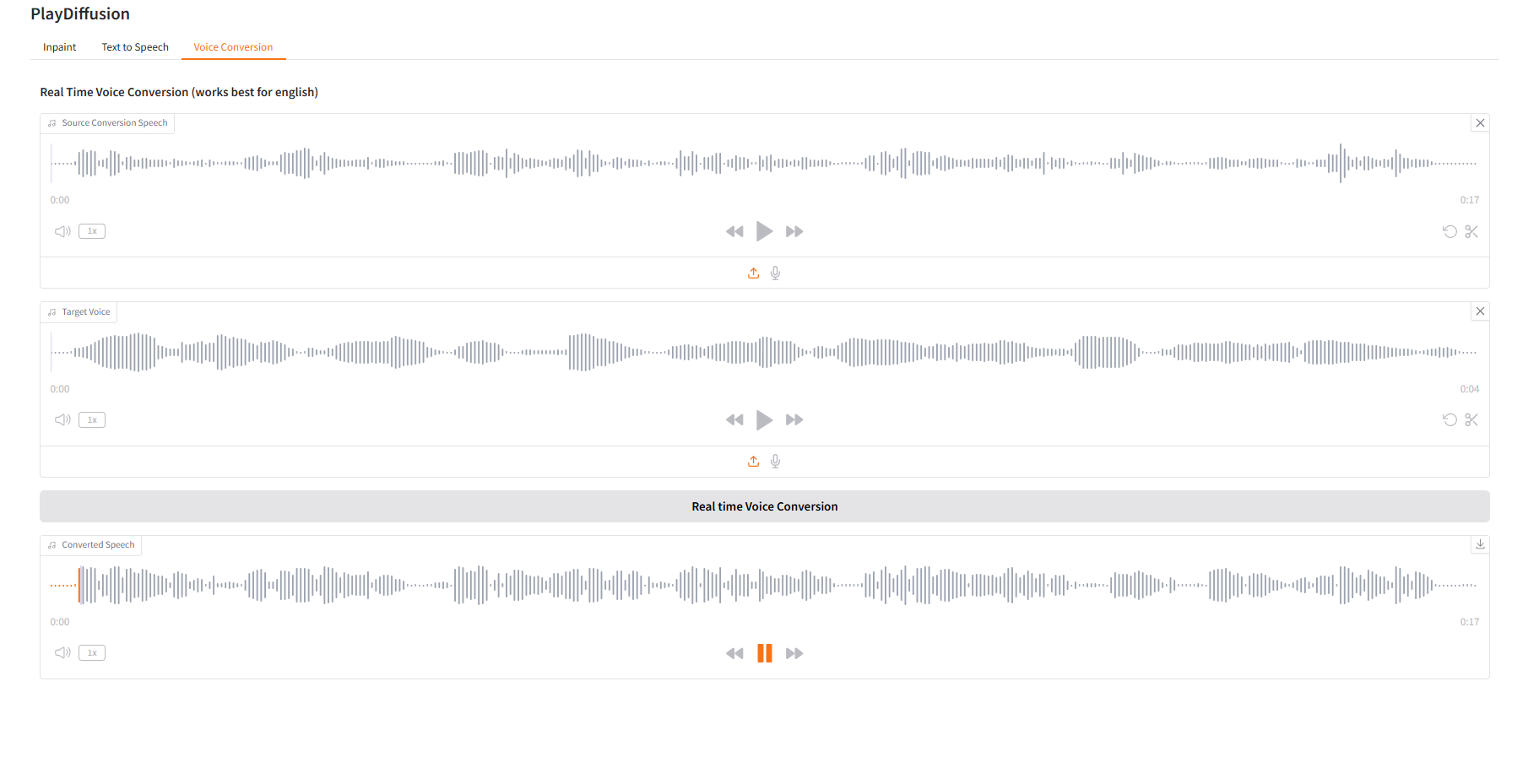
3. Voice Conversion
3. Operation steps
1. Start the container
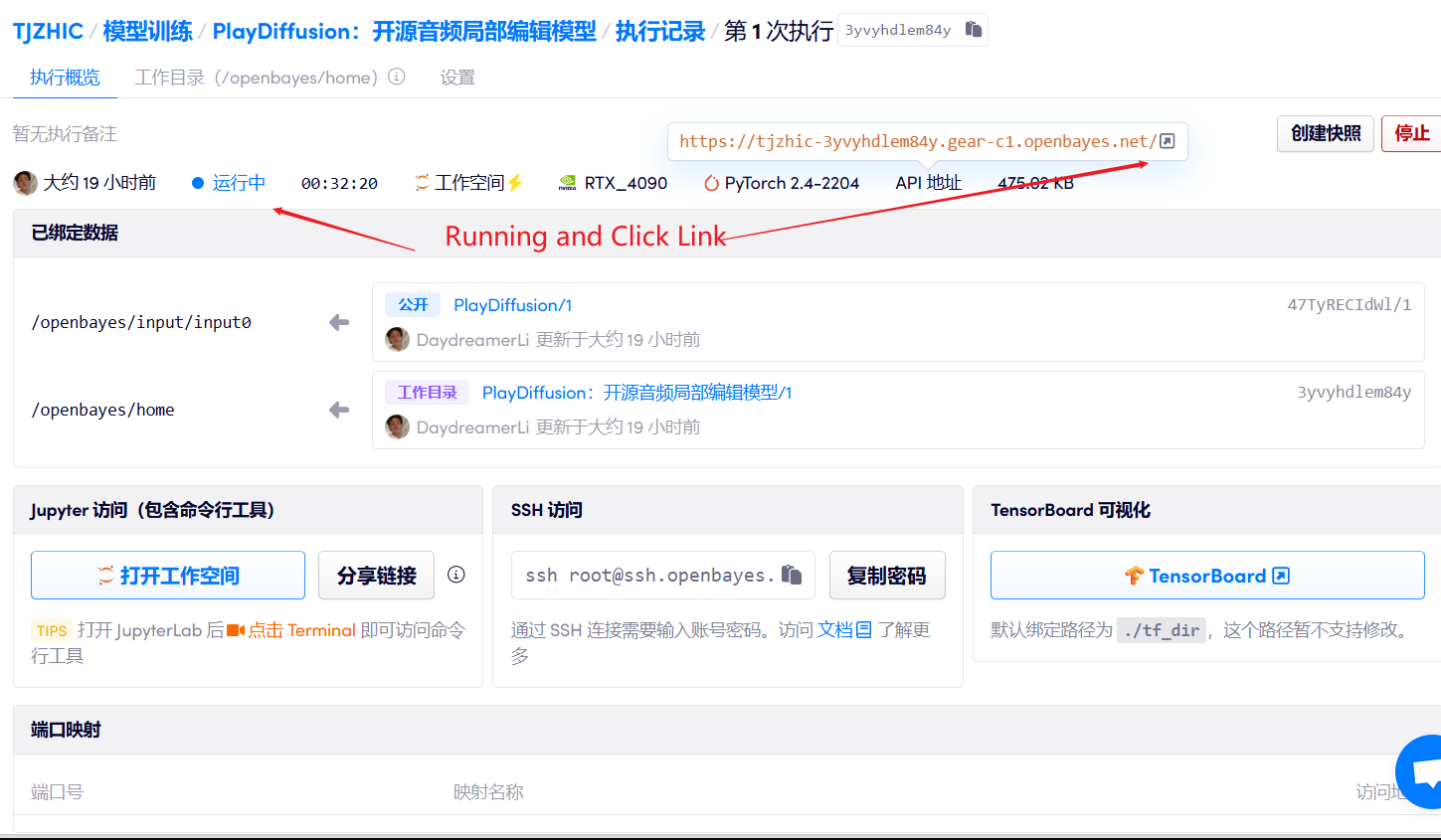
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
1. Inpaint
This module can partially replace, modify or delete audio without regenerating the entire audio, keeping the speech natural and seamless.
- Upload the original audio, click "Run SAR" to run, and then modify and edit the audio content you want to output in "Desired output text".
- Then click "Run Inpainter" to generate the edited audio.
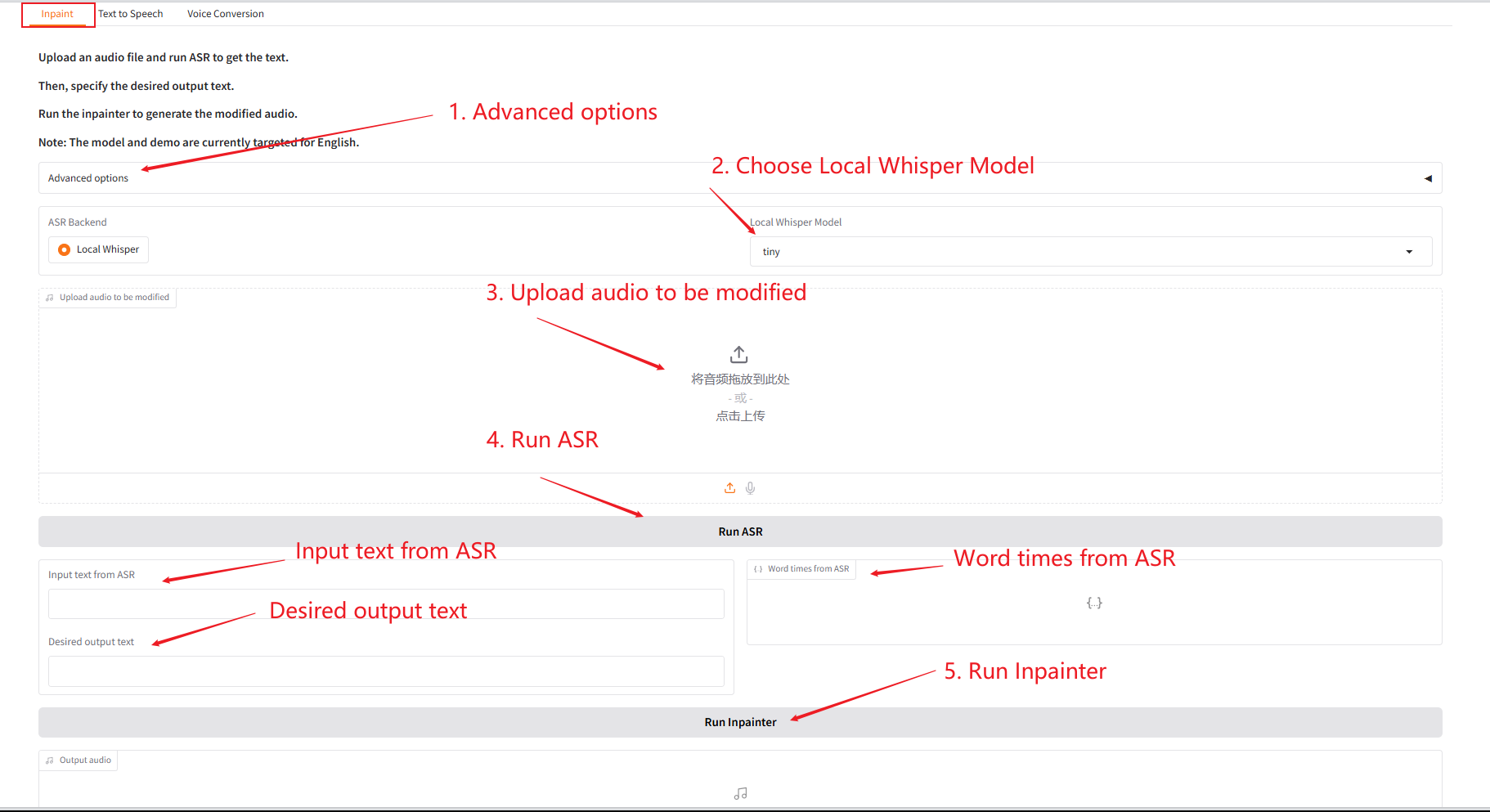
Parameter Description:
- Number of sampling steps: The number of iterations in the diffusion model generation process. The more steps, the higher the generation quality but the longer the time.
- Codebook: A dictionary of discrete symbols in the vector quantization layer, used to map continuous features into discrete representations.
- Initial temperature: A parameter that controls the randomness of sampling. The higher the value, the greater the diversity, and the lower the value, the more certain the result.
- Initial diversity: Parameters that control the degree of variation in generated samples to avoid generating results that are too similar.
- Guidance: Adjusts the degree of influence of conditional information (such as text) on the generated results.
- Guidance rescale factor: The weight ratio used to balance conditional guidance and unconditional generation.
- Sampling from top-k logits: Select only from the K candidates with the highest probability to improve the generation quality.
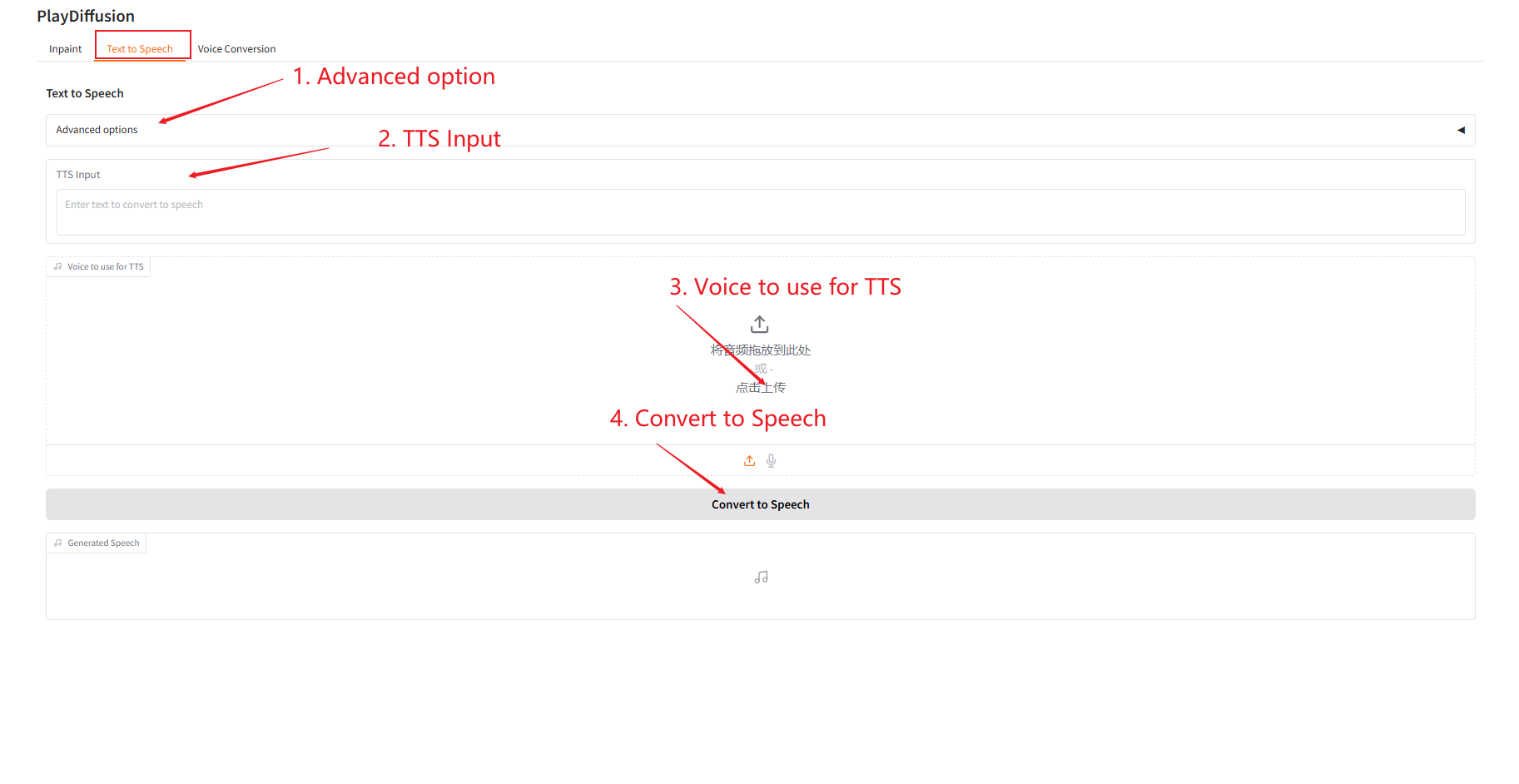
2. Text to Speech
As an efficient TTS model, its inference speed is 50 times faster than traditional TTS, and its speech naturalness and consistency are better.
- Enter the text content you want to generate audio for in "TTS Input" and then upload the target audio.
- Then click "Convert to Speech" to generate audio.
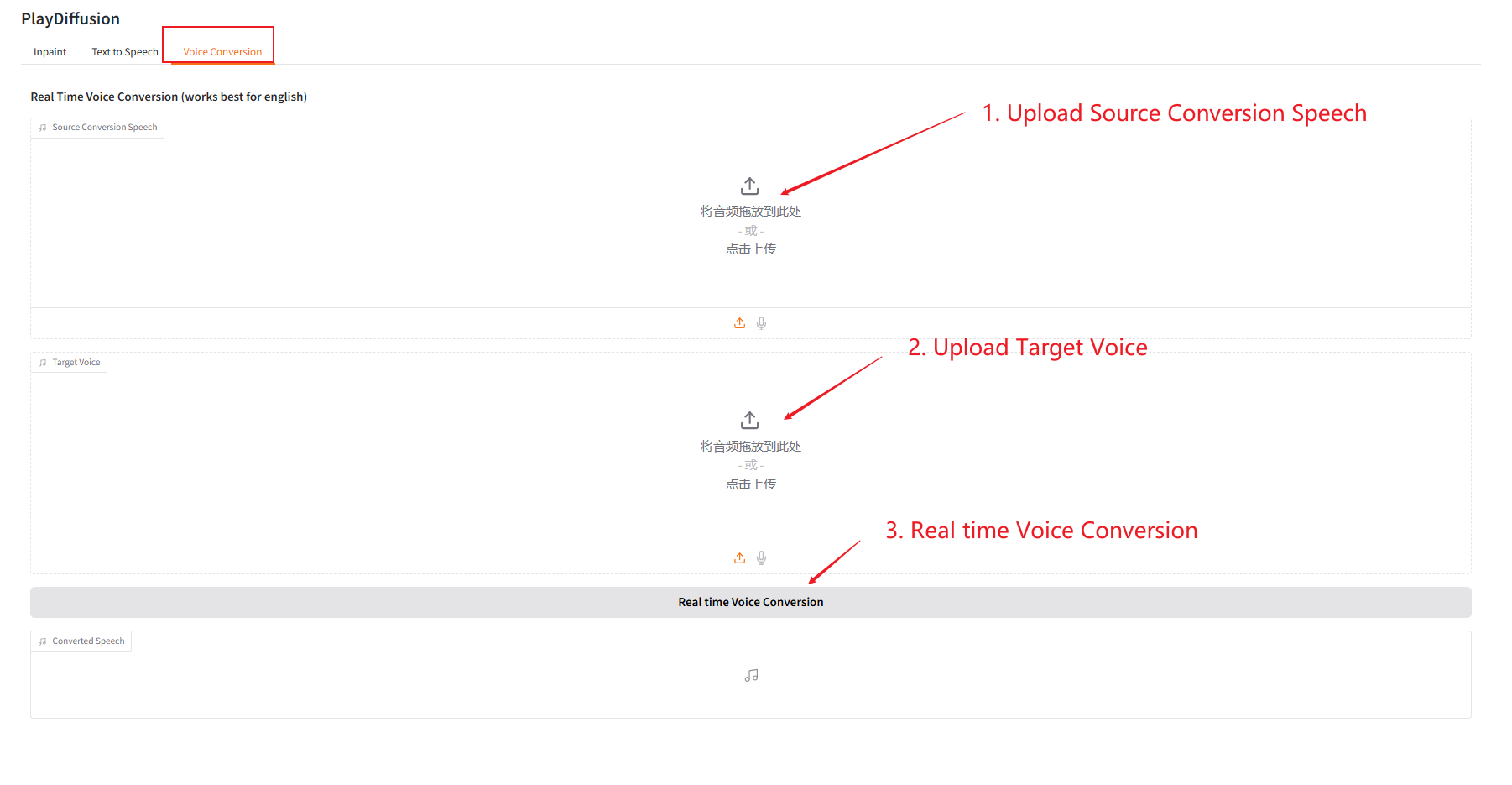
3. Voice Conversion
Dynamically adjust the voice content, and you can directly clone the original audio content to the target timbre.
- Upload the original audio, then upload the target audio.
- Then click "Real time Voice Conversion" to directly generate the original audio content of the target tone.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.