Command Palette
Search for a command to run...
vLLM+Open WebUI Deployment KernelLLM-8B
1. Tutorial Introduction
The computing resources used in this tutorial are a single RTX 4090 card.
KernelLLM is a large language model designed for GPU kernel development launched by Meta AI. It aims to automatically translate PyTorch modules into efficient Triton kernel code, thereby simplifying and accelerating the process of high-performance GPU programming. The model is based on the Llama 3.1 Instruct architecture, has 8 billion parameters, and focuses on generating efficient Triton kernel implementations.
2. Project Examples
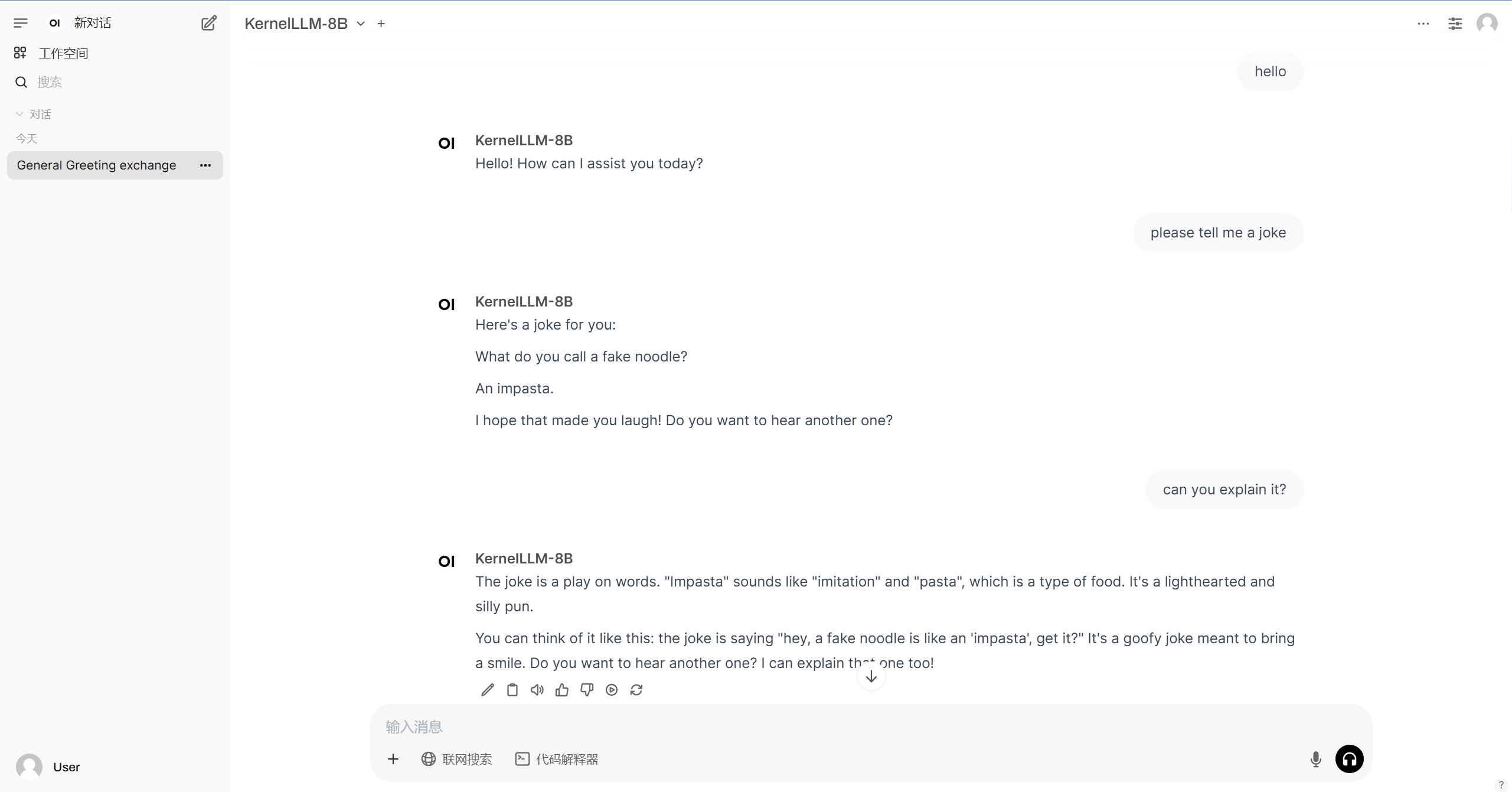
3. Operation steps
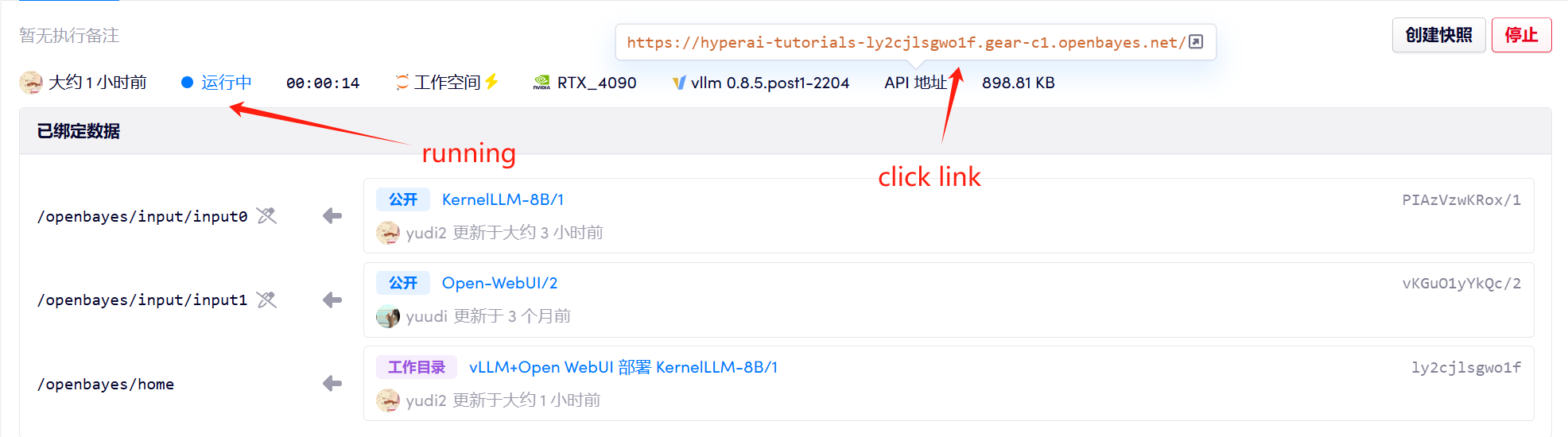
1. Start the container
If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 2-3 minutes and refresh the page.
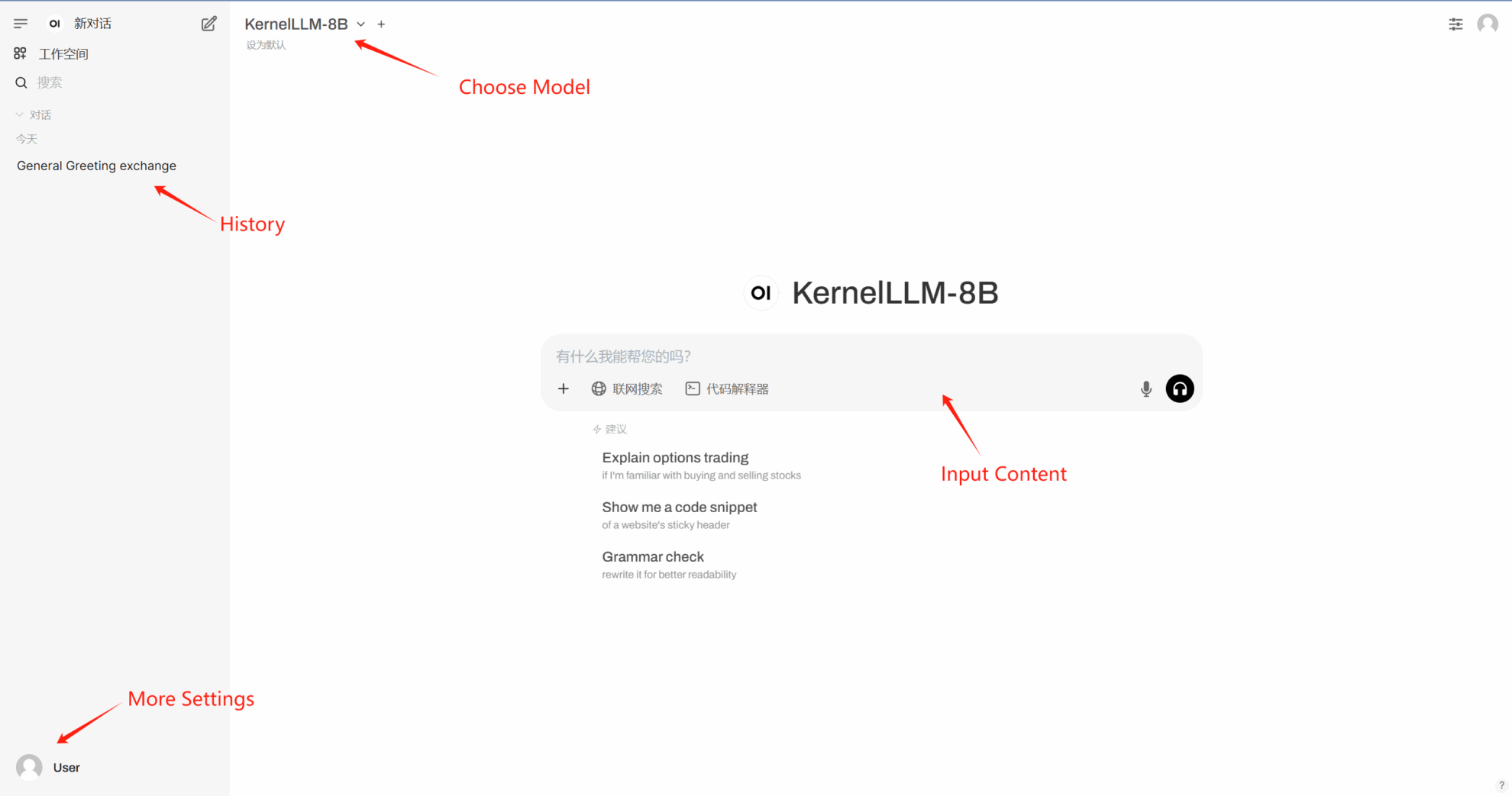
2. After entering the webpage, you can start a conversation with the model
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.