Command Palette
Search for a command to run...
MonkeyOCR: Document Parsing Based on the structure-recognition-relation Triple Paradigm
1. Tutorial Introduction

MonkeyOCR is a document parsing model open-sourced on June 5, 2025, by Huazhong University of Science and Technology in collaboration with Kingsoft Office. The model efficiently converts unstructured document content into structured information. Based on accurate layout analysis, content recognition, and logical sorting, it significantly improves the accuracy and efficiency of document parsing. Compared to traditional methods, MonkeyOCR performs exceptionally well in processing complex documents (such as those containing formulas and tables), achieving an average performance improvement of 5.11 TP3T, and improvements of 15.01 TP3T and 8.61 TP3T in formula and table parsing, respectively. The model excels in processing multi-page documents, achieving 0.84 pages per second, far exceeding other similar tools. MonkeyOCR supports various document types, including academic papers, textbooks, and newspapers, and is compatible with multiple languages, providing powerful support for document digitization and automated processing. Related research papers are available. MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm .
Key features:
- Document parsing and structuring: Convert unstructured content (including text, tables, formulas, images, etc.) in documents of various formats (such as PDF, images, etc.) into structured machine-readable information.
- Multi-language support: Supports multiple languages, including Chinese and English.
- Efficiently handle complex documents: It performs well when processing complex documents (such as those containing formulas, tables, multi-column layouts, etc.).
- Fast multi-page document processing: Efficiently process multi-page documents with a processing speed of 0.84 pages per second, significantly better than other tools (such as MinerU 0.65 pages per second Qwen2.5-VL-7B 0.12 pages per second).
- Flexible deployment and expansion: Supports efficient deployment on a single NVIDIA 3090 GPU to meet needs of different scales.
Technical principle:
- Structure-Recognition-Relation (SRR) triplet paradigm: A document layout detector based on YOLO that identifies the location and category of key elements in a document (such as text blocks, tables, formulas, images, etc.). Content recognition is performed on each detected region, and end-to-end recognition is performed using a large multi-morphic model (LMM) to ensure high accuracy. Based on a block-level reading order prediction mechanism, the logical relationship between the detected elements is determined to reconstruct the semantic structure of the document.
- MonkeyDoc dataset: MonkeyDoc is the most comprehensive document parsing dataset to date, containing 3.9 million instances, covering more than ten document types in Chinese and English. The dataset is built based on a multi-stage pipeline, integrating careful manual annotation, programmatic synthesis, and model-driven automatic annotation. It is used to train and evaluate MonkeyOCR models, ensuring strong generalization capabilities in diverse and complex document scenarios.
- Model optimization and deployment: The AdamW optimizer and cosine learning rate scheduling are used in combination with large-scale datasets for training to ensure a balance between model accuracy and efficiency. Based on the LMDeplov tool, MonkeyOCR can run efficiently on a single NVIDIA 3090 GPU, supporting fast reasoning and large-scale deployment.
This tutorial uses a single RTX 5090 graphics card as computing resource.
2. Effect display
Formula Document Example

Table document example

Newspaper Example

Financial Report Example


3. Operation steps
1. Start the container
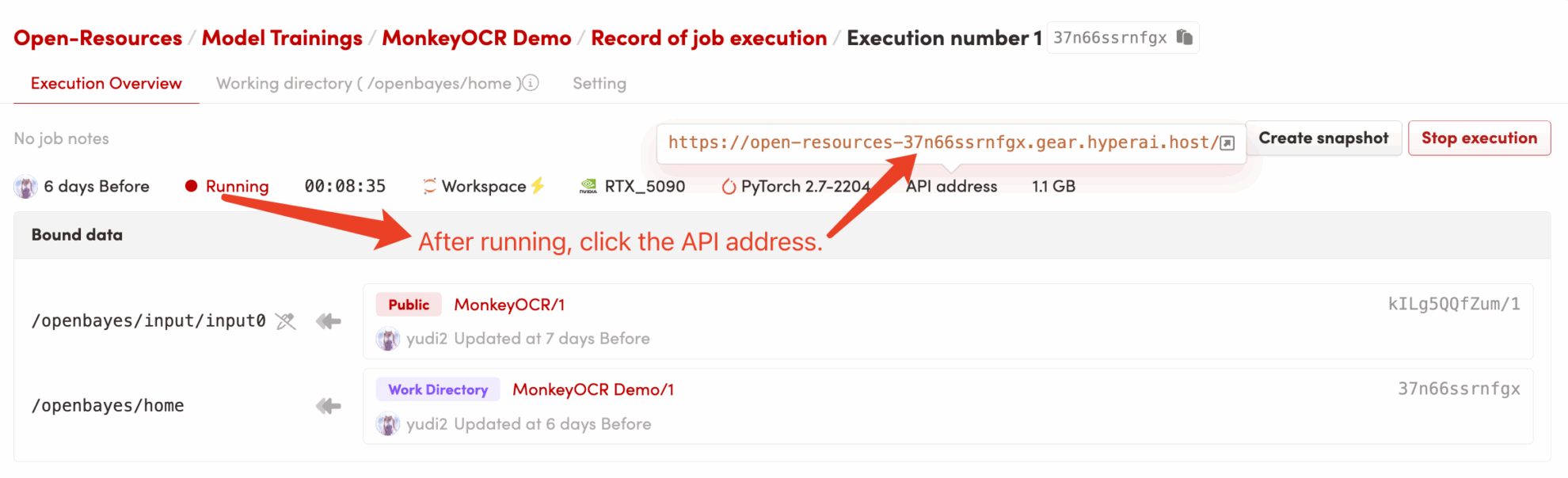
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.

Citation Information
The citation information for this project is as follows:
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.