Command Palette
Search for a command to run...
OpenAudio-s1-mini: A high-efficiency TTS Generation Tool
Date
License
Apache 2.0
GitHub
1. Tutorial Introduction

This tutorial uses resources for a single RTX 4090 card.
2. Project Examples
Text-to-speech

3. Operation steps
1. After starting the container, click the API address to enter the Web interface
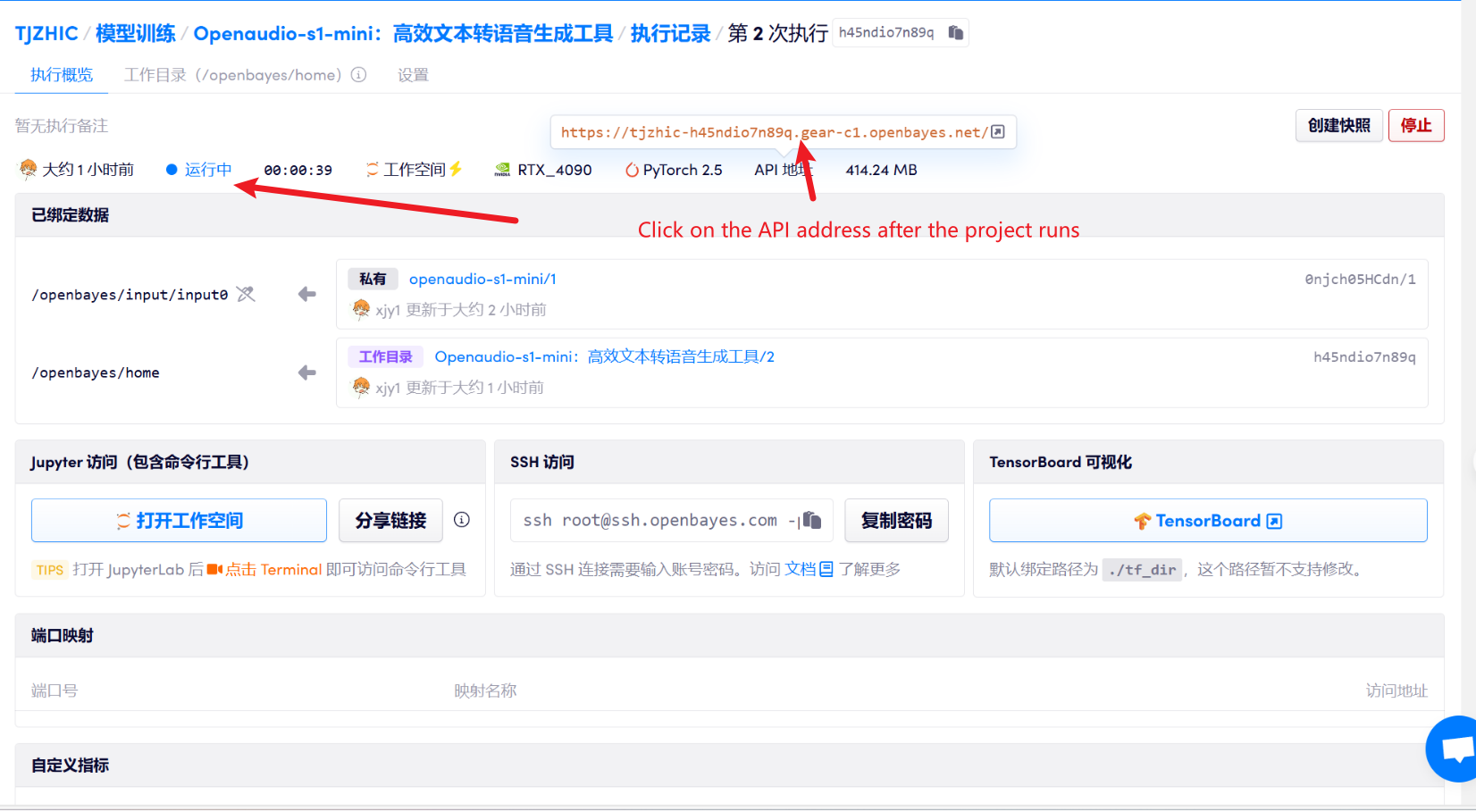
2. Once you enter the webpage, you can use the model
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page. When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
How to use
2.1 Text to Audio
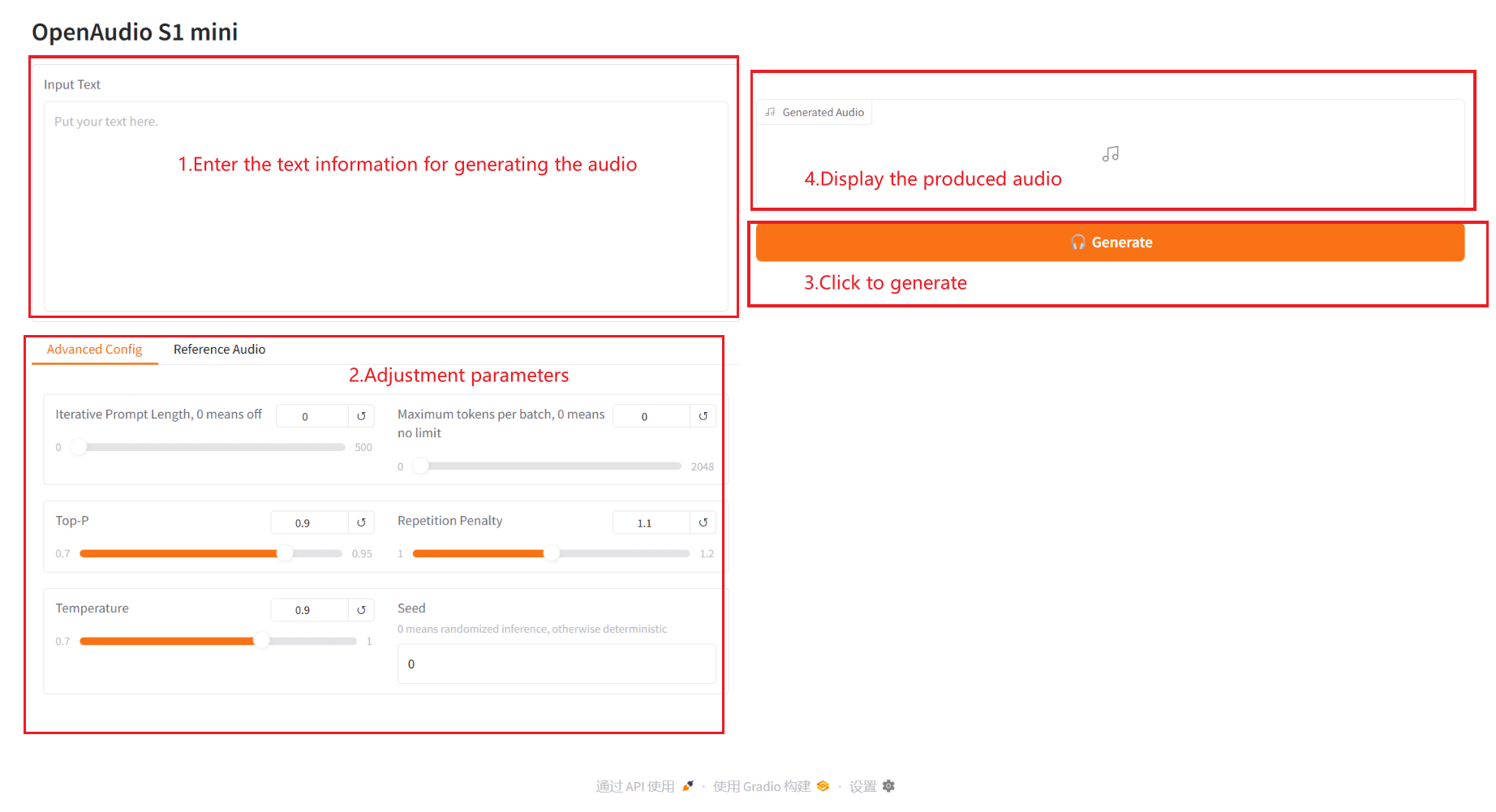
Parameter Description:
- Advanced Config:
- Iterative Prompt Length: Iterative prompt length. 0 means off. Non-zero value controls the length of prompt text used each time when iteratively generating speech.
- Maximum tokens per batch: The maximum number of tokens per batch. 0 means unlimited. A non-zero value limits the maximum number of tokens processed per batch.
- Top – P: kernel sampling probability, which controls the diversity and certainty of generated text.
- Repetition Penalty: Repetition penalty coefficient, used to control the frequency of repeated content in the generated text. The larger the value, the more repetition is avoided.
- Temperature: Temperature coefficient, which adjusts the randomness of the generated text. The larger the value, the more random it is.
- Seed: Random seed, used to generate fixed random numbers to ensure reproducible results.
- Reference Audio:
- Use Memory Cache: Select whether to use memory cache.
- Reference Audio: Upload an audio file (wav file) to be used as a reference.
- Reference Text: Enter the text content of the uploaded audio.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.