Command Palette
Search for a command to run...
MMaDA: Multimodal Large Diffuse Language Model
Date
Size
757.43 MB
License
MIT
GitHub
Paper URL
1. Tutorial Introduction

MMaDA-8B-Base is a multimodal diffusion-based large language model jointly developed by Princeton University, ByteDance Seed team, Peking University, and Tsinghua University, and released on May 23, 2025. This model is the first unified model to systematically explore diffusion architecture as a fundamental paradigm for multimodal learning, aiming to achieve general intelligent capabilities across modal tasks through deep fusion of text reasoning, multimodal understanding, and image generation. Related research papers are available. MMaDA: Multimodal Large Diffusion Language Models .
The computing resources of this tutorial use a single A6000 card, and the model deployed in this tutorial is MMaDA-8B-Base. Three examples of Text Generation, Multimodal Understanding, and Text-to-Image Generation are provided for testing.
2. Operation steps
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
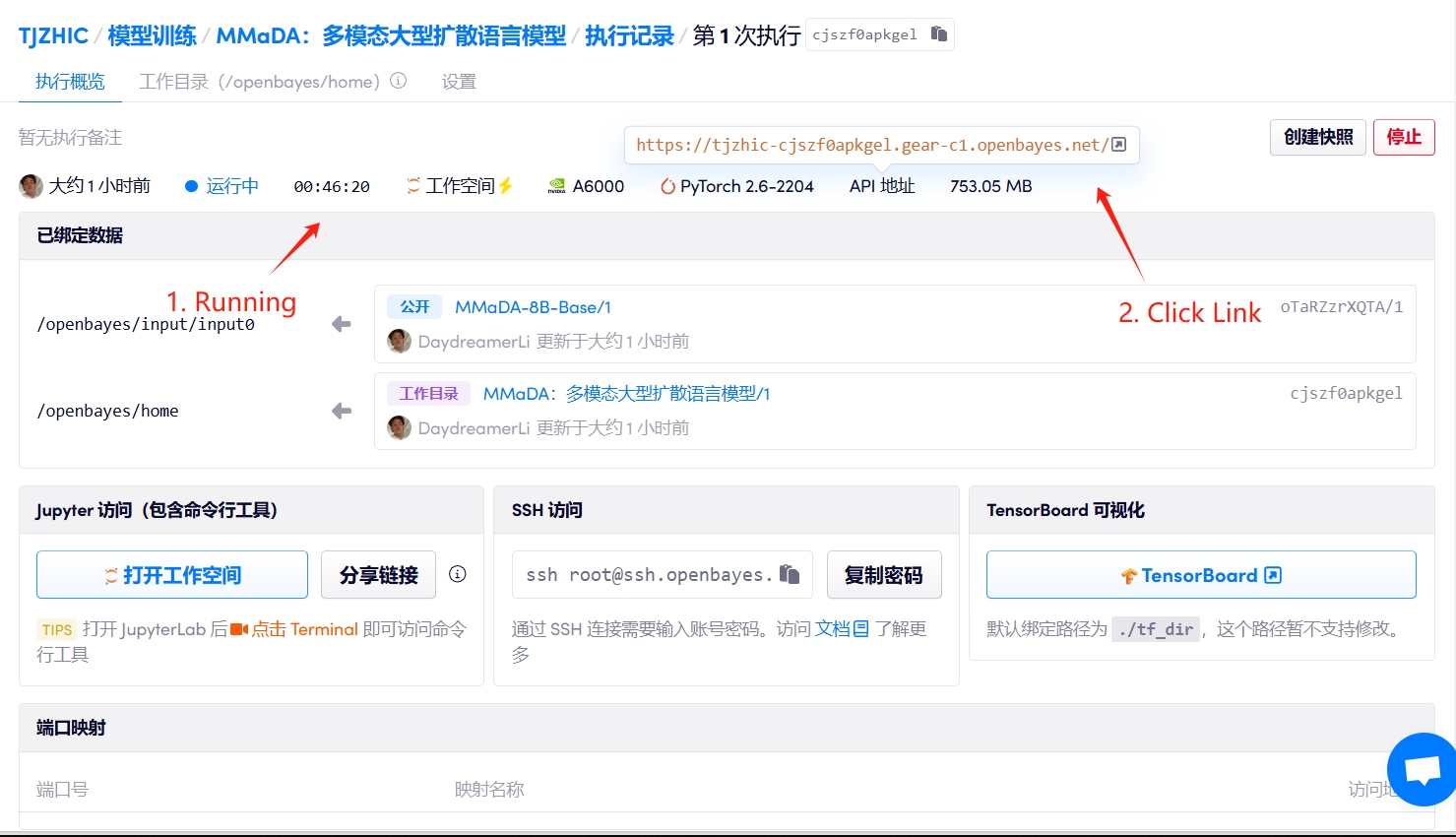
2. Usage steps
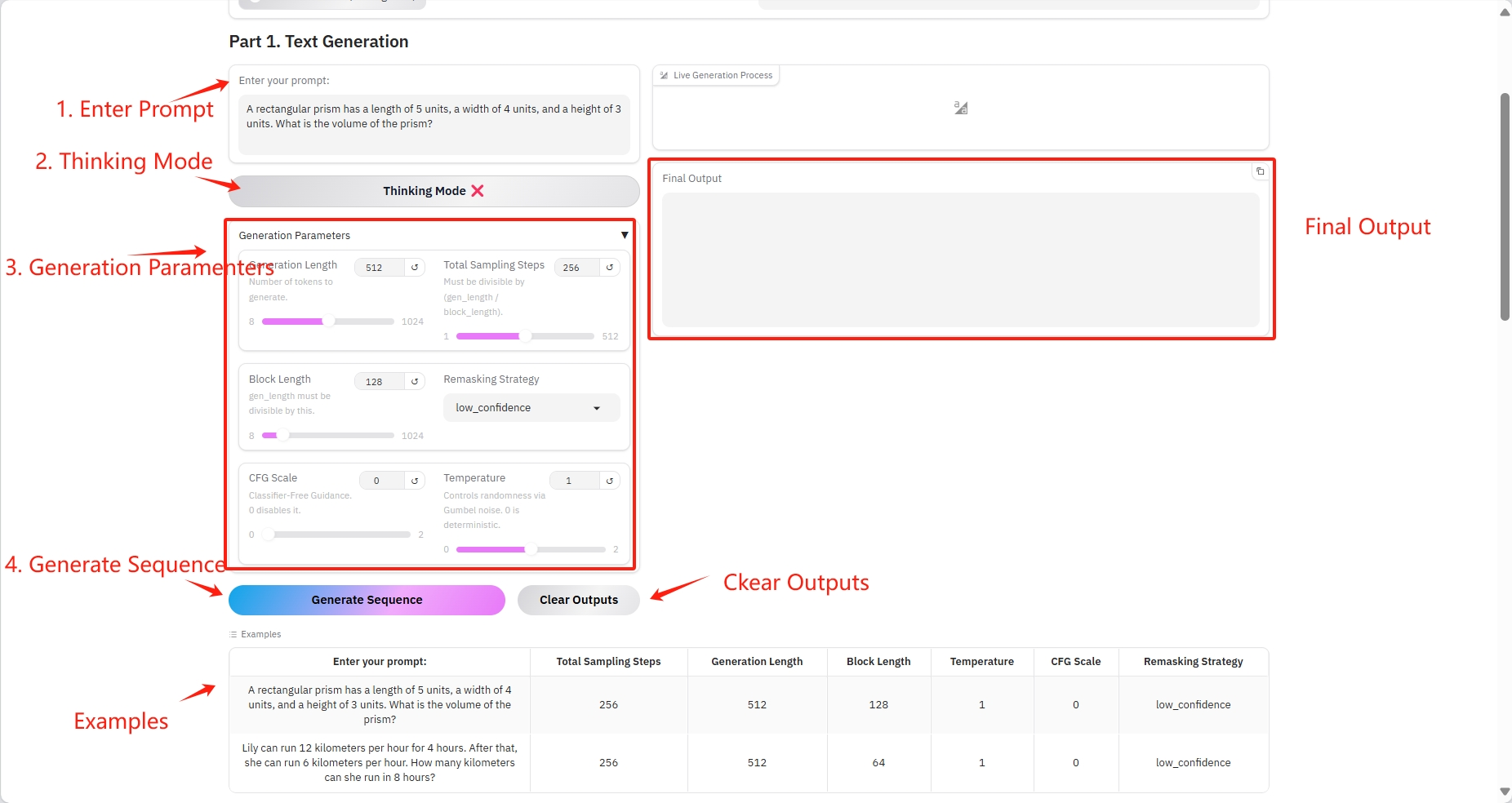
1. Text Generation
Specific parameters:
- Prompt: You can enter text here.
- Generation Length: The number of generated tokens.
- Total Sampling Steps: Must be divisible by (gen_length / block_length).
- Block Length: gen_length must be divisible by this number.
- Remasking Strategy: Remasking strategy.
- CFG Scale: No classifier guide. 0 disables it.
- Temperature: Controls randomness via Gumbel noise. 0 is deterministic.
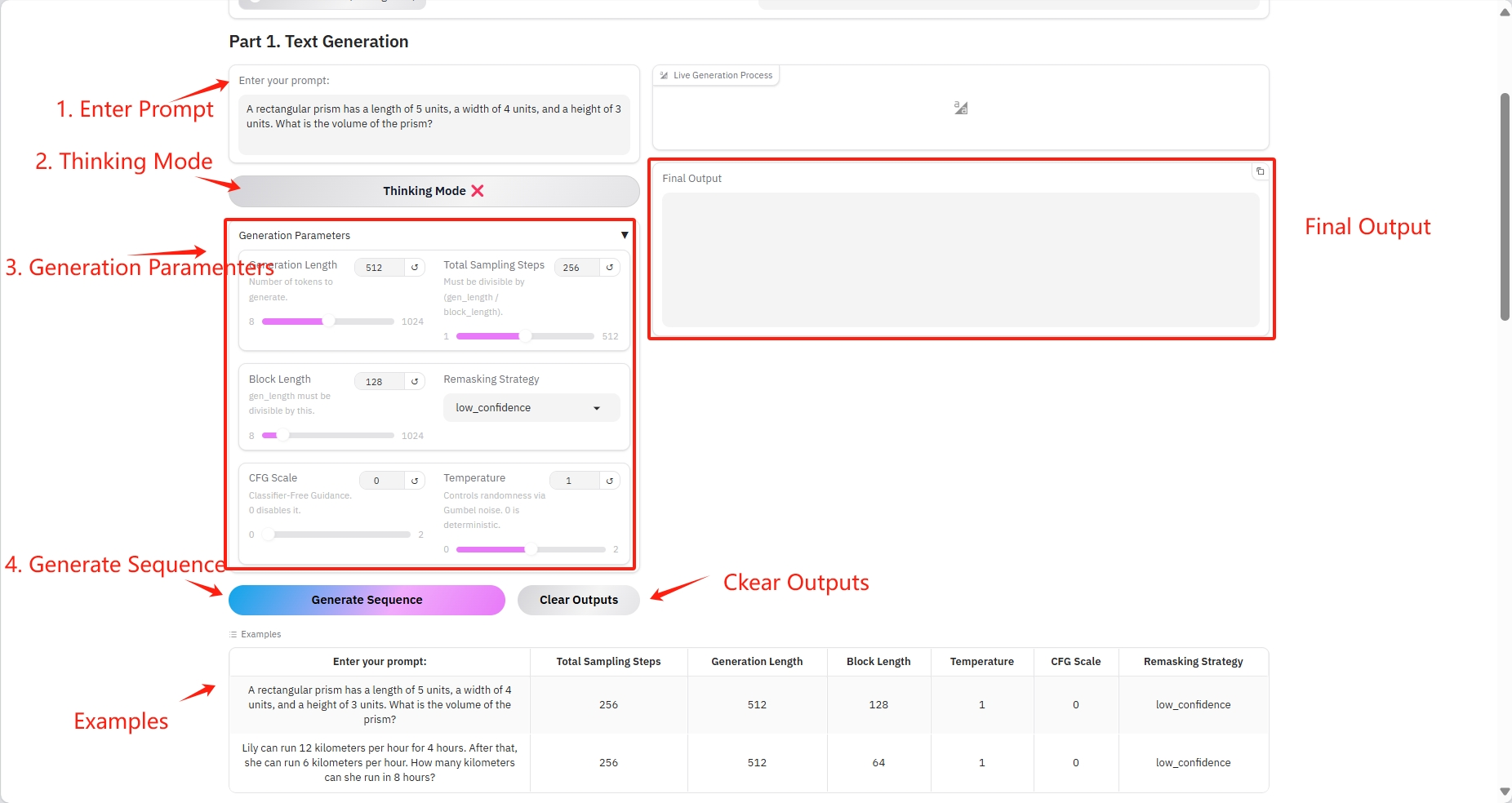
Result Output
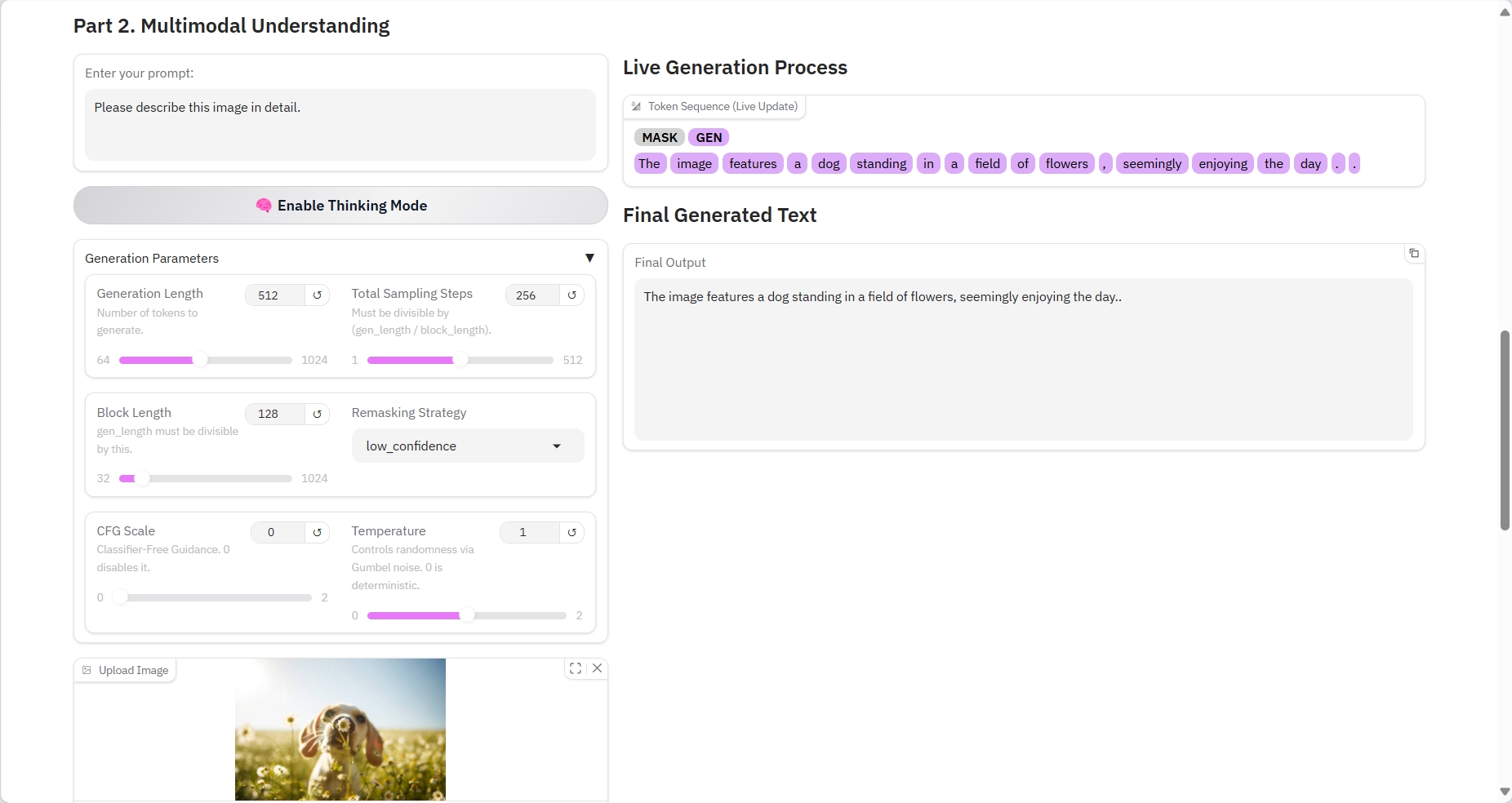
2. Multimodal Understanding
Specific parameters:
- Prompt: You can enter text here.
- Generation Length: The number of generated tokens.
- Total Sampling Steps: Must be divisible by (gen_length / block_length).
- Block Length: gen_length must be divisible by this number.
- Remasking Strategy: Remasking strategy.
- CFG Scale: No classifier guide. 0 disables it.
- Temperature: Controls randomness via Gumbel noise. 0 is deterministic.
- Image: picture.
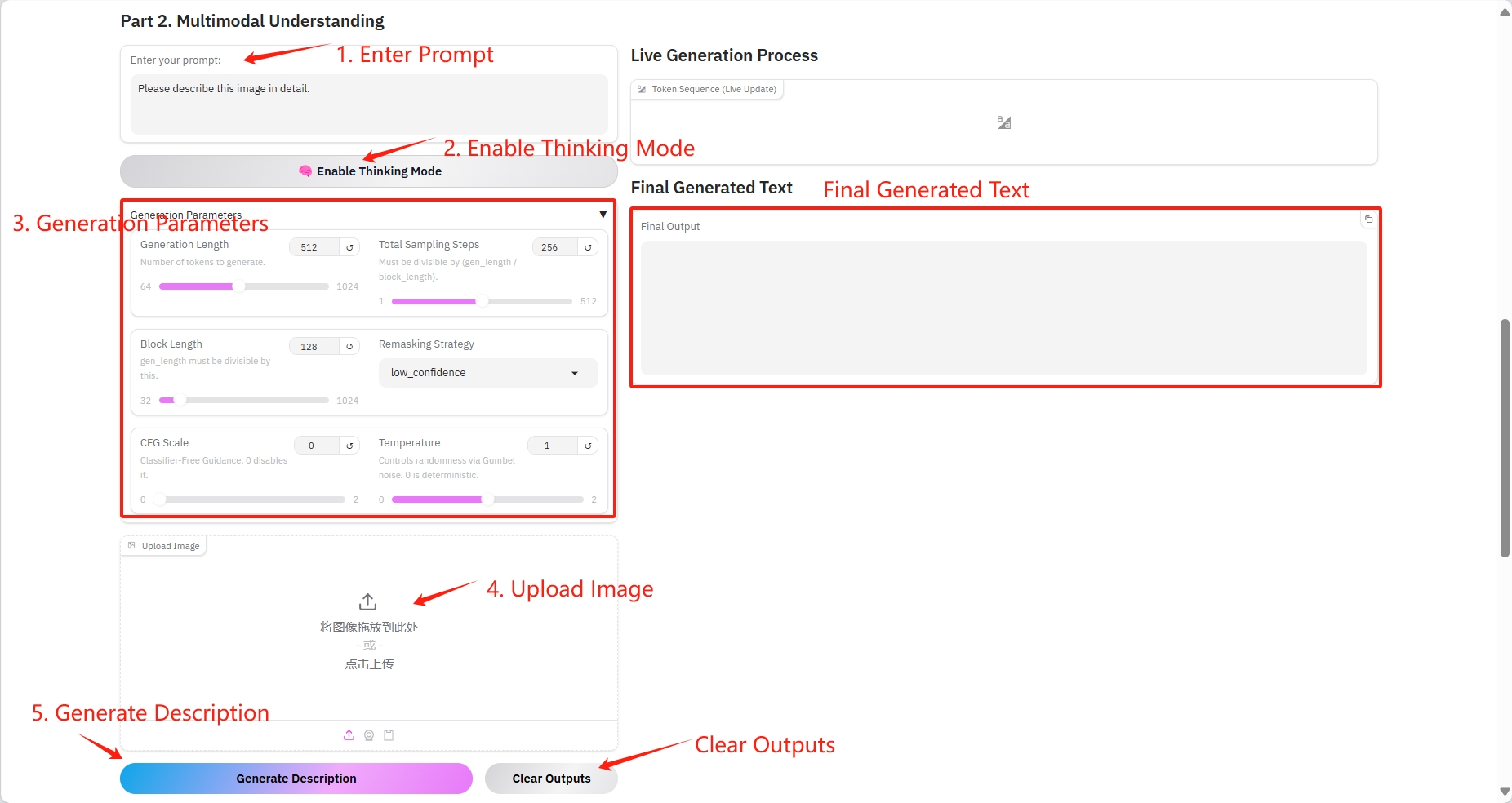
Result Output
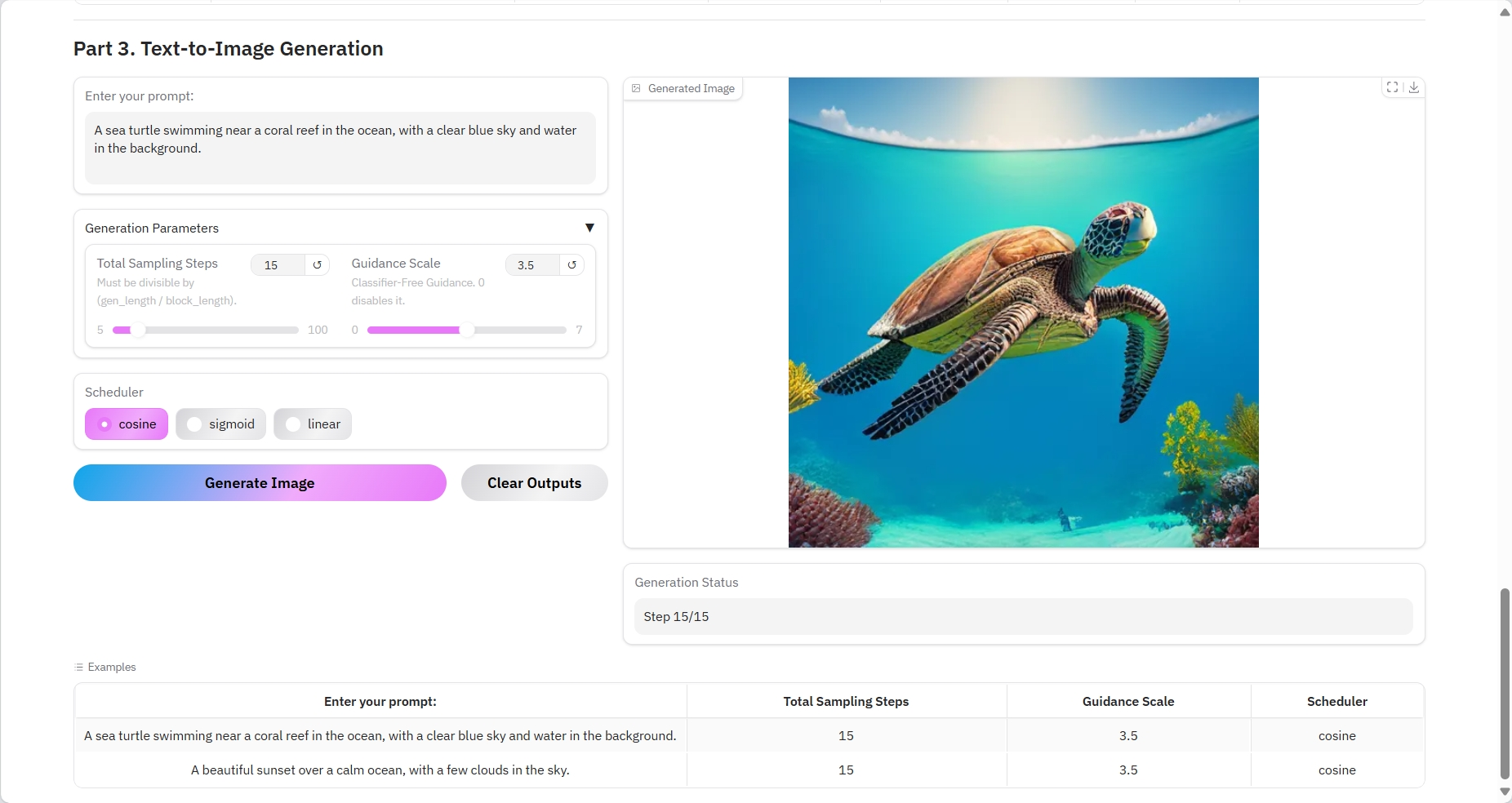
3. Text-to-Image Generation
Specific parameters:
- Prompt: You can enter text here.
- Total Sampling Steps: Must be divisible by (gen_length / block_length).
- Guidance Scale: No classifier guidance. 0 disables it.
- Scheduler:
- cosine: Cosine similarity calculates the similarity of sentence pairs and optimizes the embedding vectors.
- sigmoid: multi-label classification.
- Linear: The linear layer maps the image patch embedding vector to a higher dimension for attention calculation.
Result Output
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
Thanks to Github user SuperYang Deployment of this tutorial. The reference information of this project is as follows:
@article{yang2025mmada,
title={MMaDA: Multimodal Large Diffusion Language Models},
author={Yang, Ling and Tian, Ye and Li, Bowen and Zhang, Xinchen and Shen, Ke and Tong, Yunhai and Wang, Mengdi},
journal={arXiv preprint arXiv:2505.15809},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.