Command Palette
Search for a command to run...
Stable-audio-open-small: Audio Generation Model Demo
Date
Size
1.47 GB
License
MIT
Paper URL
1. Tutorial Introduction

This tutorial uses a single-card A6000 resource. Generated prompts only support English.
2. Project Examples
3. Operation steps
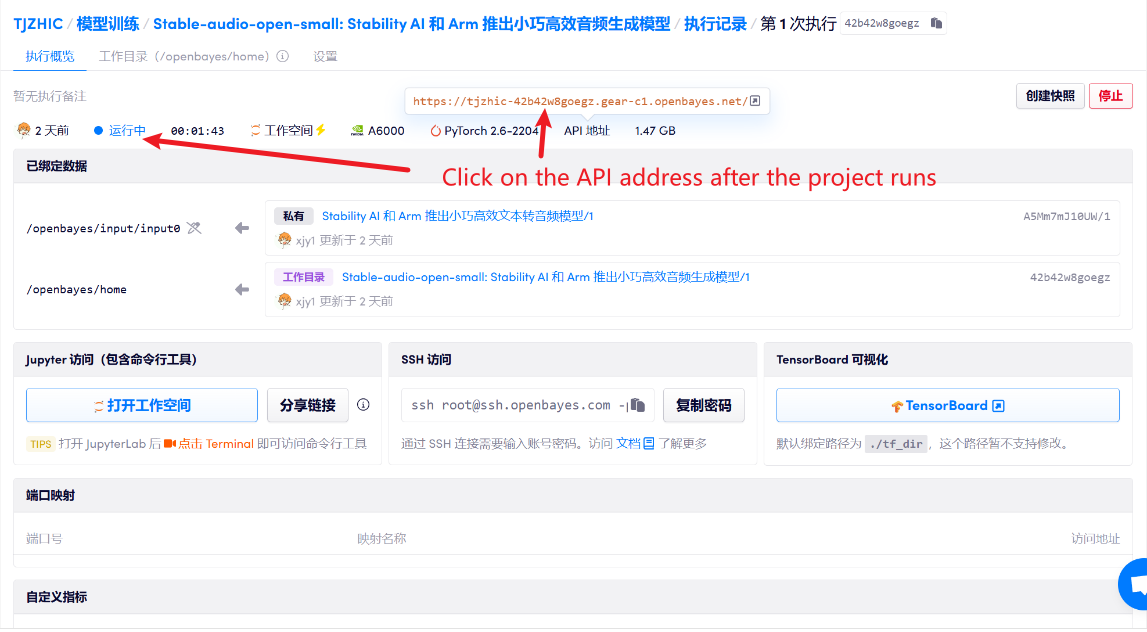
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
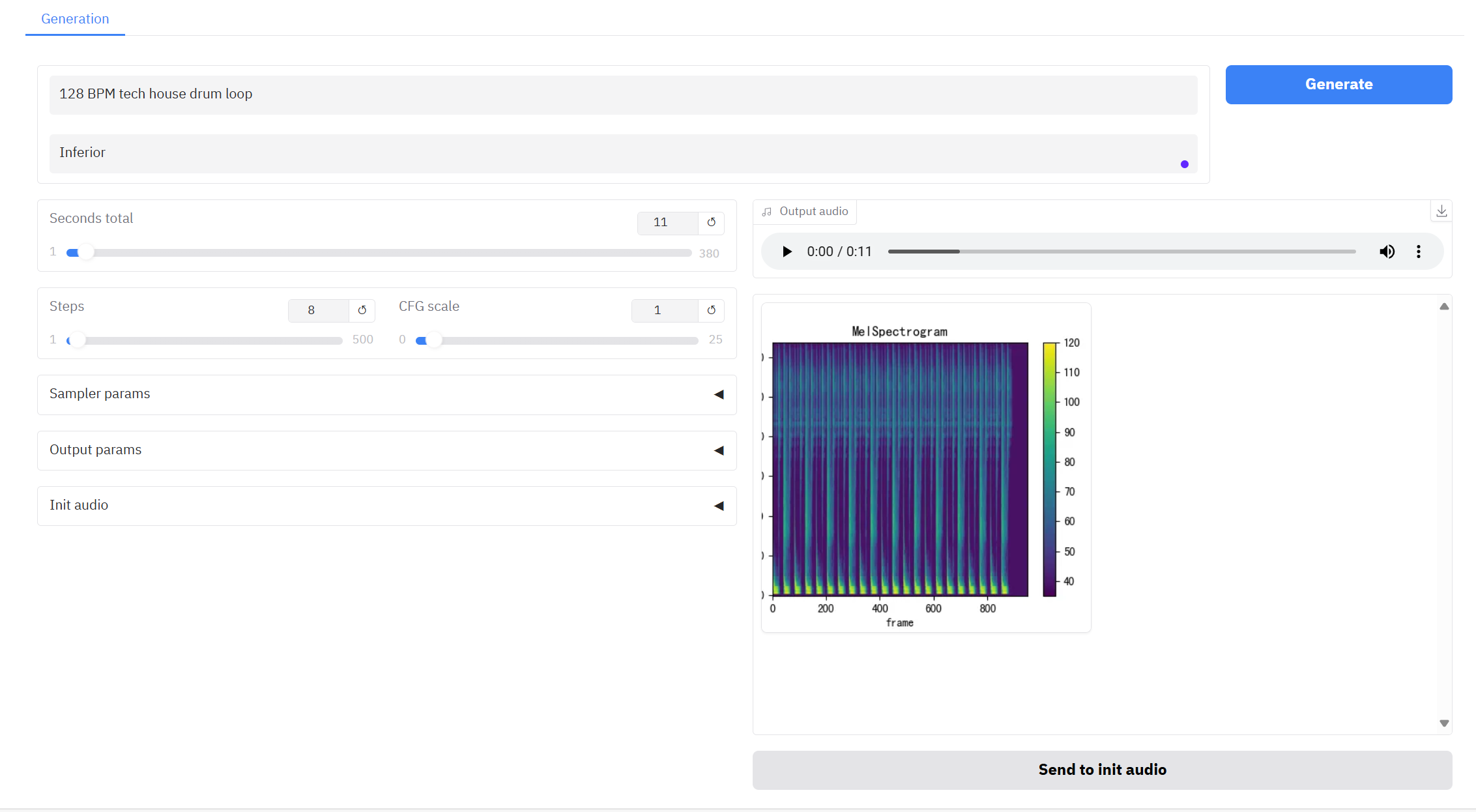
2. After entering the webpage, you can start a conversation with the model
Tips: Improper parameter settings may generate noise. When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
How to use
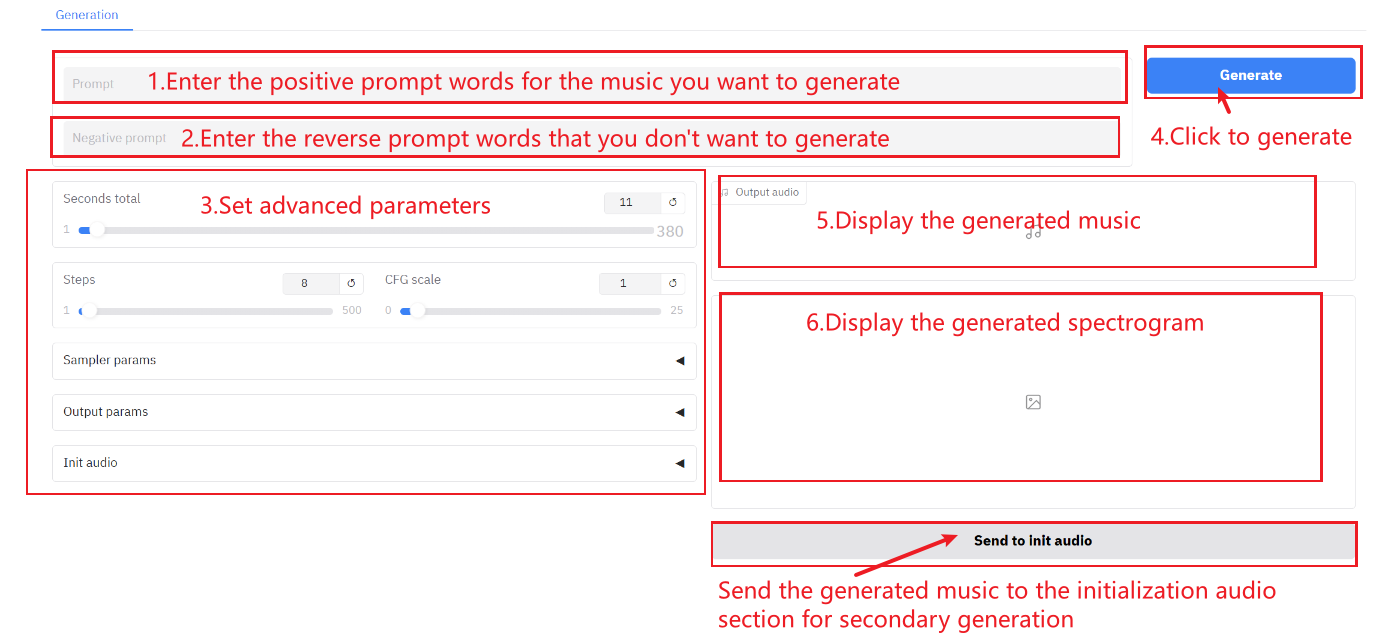
Parameter Description:
- Seconds total: The total duration of the generated audio.
- Steps: The number of iterations or steps in the inference process of the model represents the number of optimization steps the model takes to produce the result. A higher number of steps generally produces more refined results but may increase computation time.
- CFG Scale: It is used to control the influence of conditional input on the generated results in the generative model. The higher the value, the more it conforms to the text description.
Sampler params
- Seed: The random seed, which remains constant, can produce the same results repeatedly.
- CFG interval min: Set the conditional guide to the time starting point of the diffusion process.
- CFG interval max: Set the conditional guide at the time end point of the diffusion process.
- CFG rescale amount: By dynamically adjusting the condition strength, numerical overflow is prevented and generation stability under high condition strength is improved.
Output params
- File format: Select the output file format.
- File naming: Select the output file naming method.
- Spec Preview Every: Select whether to preview the spectrum graph.
- Cut to seconds total: Whether to trim to the specified duration.
- Autoplay: Whether to play automatically.
- Infinite Radio: Whether to generate in a loop.
- Auto Download: Whether to download automatically.
Init audio
- Init audio: Select the initial audio file to generate new audio.
- Init noise level: Initializes the noise level, which controls the initial randomness of the generated audio.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.