Command Palette
Search for a command to run...
Chatterbox TTS: Speech Synthesis Demo
1. Tutorial Introduction

One of Chatterbox's core features is zero-sample voice cloning, which can generate highly realistic personalized voices with only 5 seconds of reference audio without the need for a complex training process. In addition, it supports emotional exaggeration control, allowing users to adjust the emotional intensity, speaking speed, and intonation of the voice to make the voice more expressive. Chatterbox's ultra-low latency real-time synthesis capability, with a latency as low as less than 200 milliseconds, makes it suitable for interactive applications such as virtual assistants and real-time dubbing. To ensure the security and traceability of content, Resemble AI's Perth neural watermarking technology is embedded in the audio generated by Chatterbox to prevent abuse.
The main innovations are as follows:
- Emotional exaggeration control: By adjusting the parameters (such as exaggeration = 0.7 + cfg = 0.3), you can achieve a speech style from bland to dramatic.
- Real-time synthesis capability: inference delay < 200 ms, suitable for real-time interactive scenarios
The computing resources of this tutorial use a single RTX 4090 card. The prompt words of this model only support English.
2. Operation steps
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
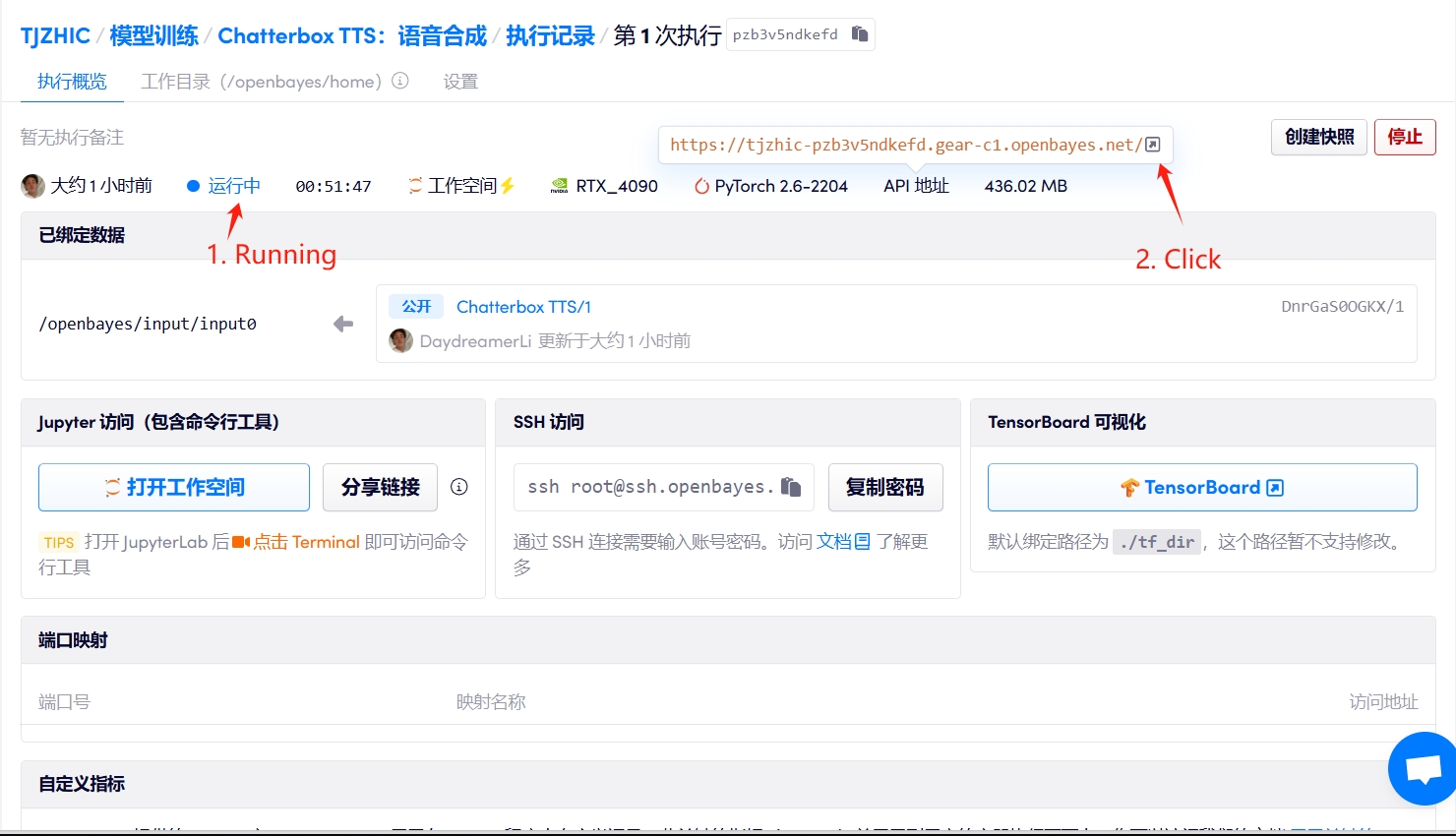
2. Usage steps
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
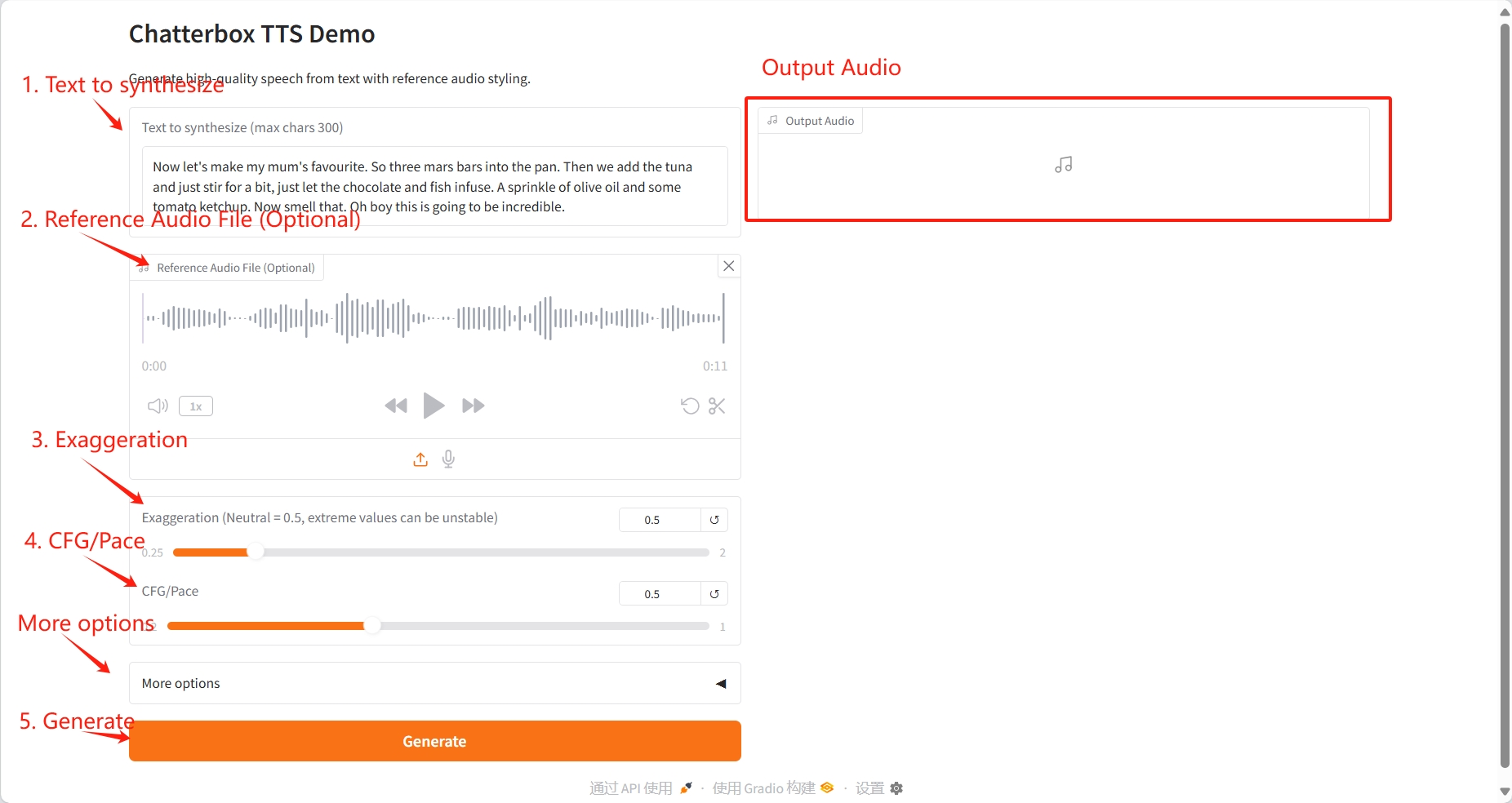
1. Text Generation
Specific parameters:
- Text to synthesize: Enter the text to be converted into speech. The maximum length is 300 characters (text that is too long will be automatically truncated).
- Reference Audio File (Optional): Provides a reference audio file to allow the system to mimic the speaker's voice style, intonation, and rhythm.
- Exaggeration (Neutral = 0.5): Controls the exaggeration of emotional expression and voice tone.
- CFG/Pace: Controls the rhythm and speed of speech.
- Random seed (0 for random): Set the random seed.
- Temperature: Controls the randomness and diversity of speech expressions.
result 
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.