Command Palette
Search for a command to run...
ComfyUI LanPaint Image Restoration Workflow Tutorial
Date
Size
634.09 MB
License
GPL
GitHub
Paper URL
1. Tutorial Introduction

LanPaint is an open-source image local inpainting tool released in March 2025. It employs an innovative inference method that adapts to various stable diffusion models (including custom models) without additional training, achieving high-quality image inpainting. Compared to traditional methods, LanPaint offers a more lightweight solution, significantly reducing the demand for training data and computational resources. Related research papers are available. Lanpaint: Training-Free Diffusion Inpainting with Exact and Fast Conditional Inference .
This tutorial uses resources for a single RTX 4090 card.
This project provides 8 sample workflows, using the following model files in total:
- animagineXL40_v40pt.safetensors
- fux1-dev-fp8.safetensors
- juggernautXL_juggXlByRundiffusion.safetensors
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- flux_vae.safetensors
- hidream-i1-full-Q6_K.gguf
- t5-v1_1-xxl-encoder-Q4_K_S.gguf
- Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf
2. Project Examples
All examples use random seed 0 to generate batches of 4 images to allow for fair comparison.
HiDream Example: InPaint (LanPaint K Sampler, 5 Thinking Steps)
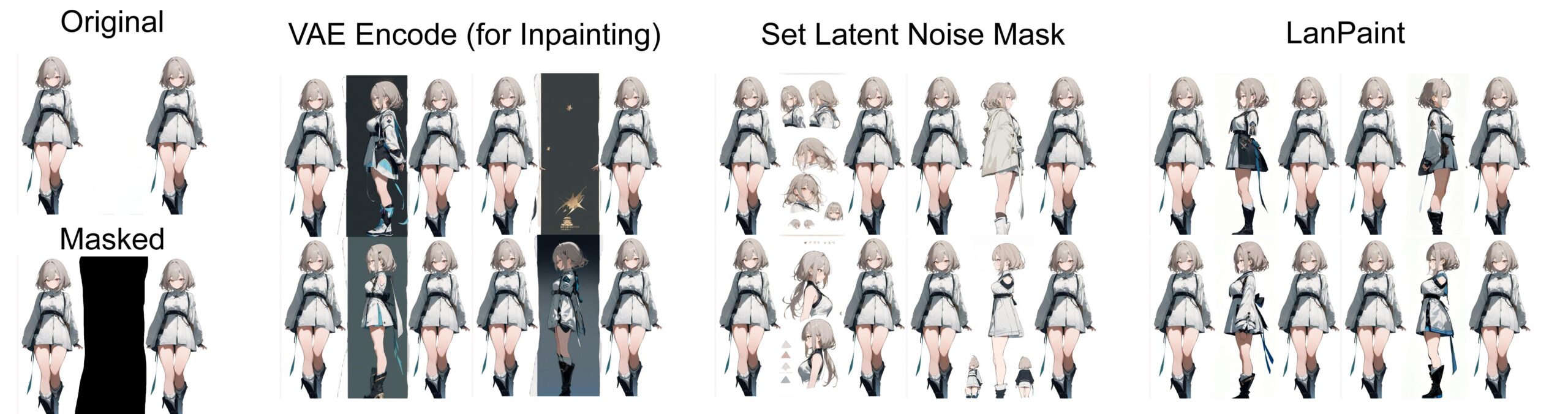
Character consistency (side view generation) (LanPaint K Sampler, 5 thinking steps)

Flux Model in Paint (LanPaint K Sampler, 5 Steps of Thinking)

3. Function List
- 🎨Zero training fix: Works out of the box with any SD model (with or without ControlNet) and Flux model! Even custom models you trained yourself.
- 🛠️Simple integration: Same workflow as the standard ComfyUI KSampler.
- 🎯 True blank generation: No need to set the default denoising to 0.7 used in traditional methods (keeping 30% original pixels in the mask): 100% New content is created without overwriting existing content.
- 🌈 More than just inpaint: You can even use this as an easy way to generate consistent characters.
4. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. Functional Demonstration
How to use
1. 导入工作流
This project has 8 built-in sample workflows.
Workflow download address:Sample Workflow Download
2. 本教程 Demo 已将工作流搭建好,仅需修改「CLIP Text Encode(Prompt)」,
并分别在「Original Image」和「Mask Image for inpainting」节点处上传对应的图片,
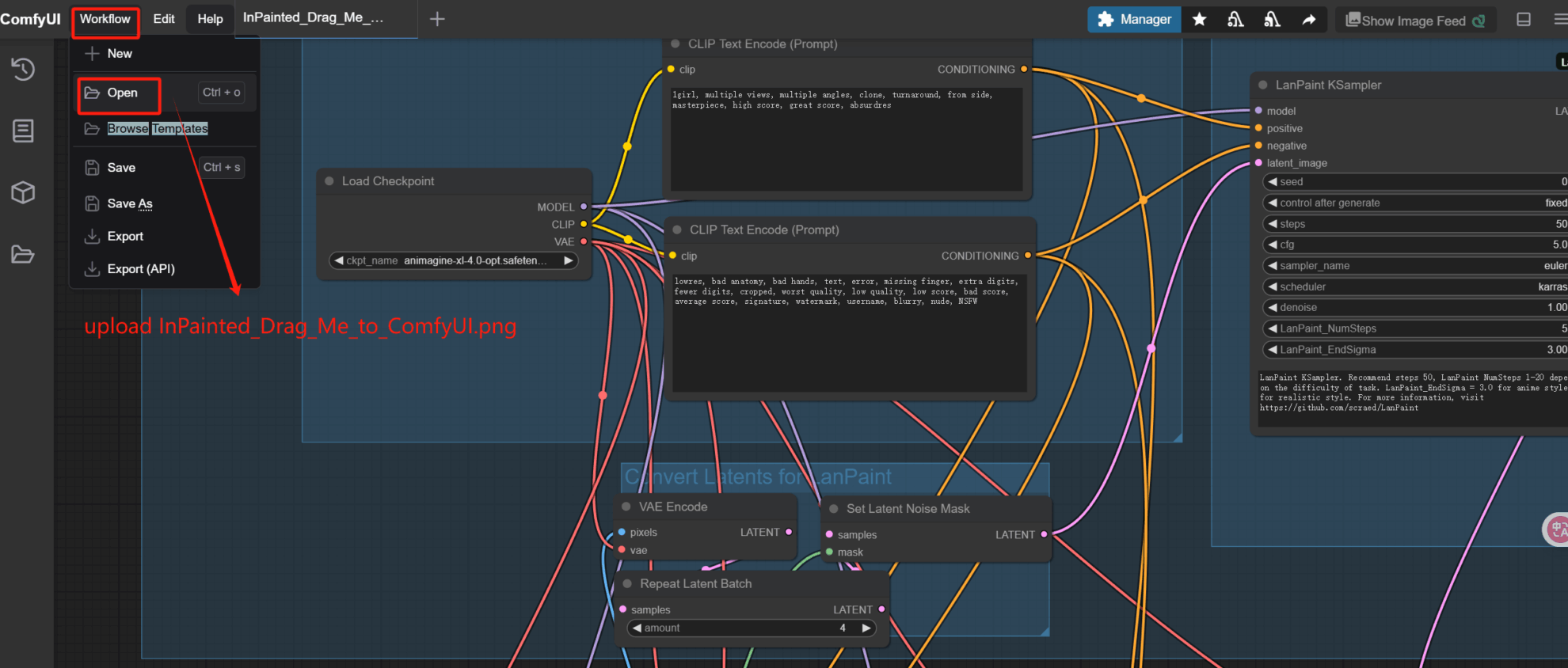
即可点击「run」来运行。The following steps take example 6 as an example. For the first clone, you need to manually open the workflow in the folder to load it. Open InPainted_Drag_Me_to_ComfyUI.png into ComfyUI and load the workflow.
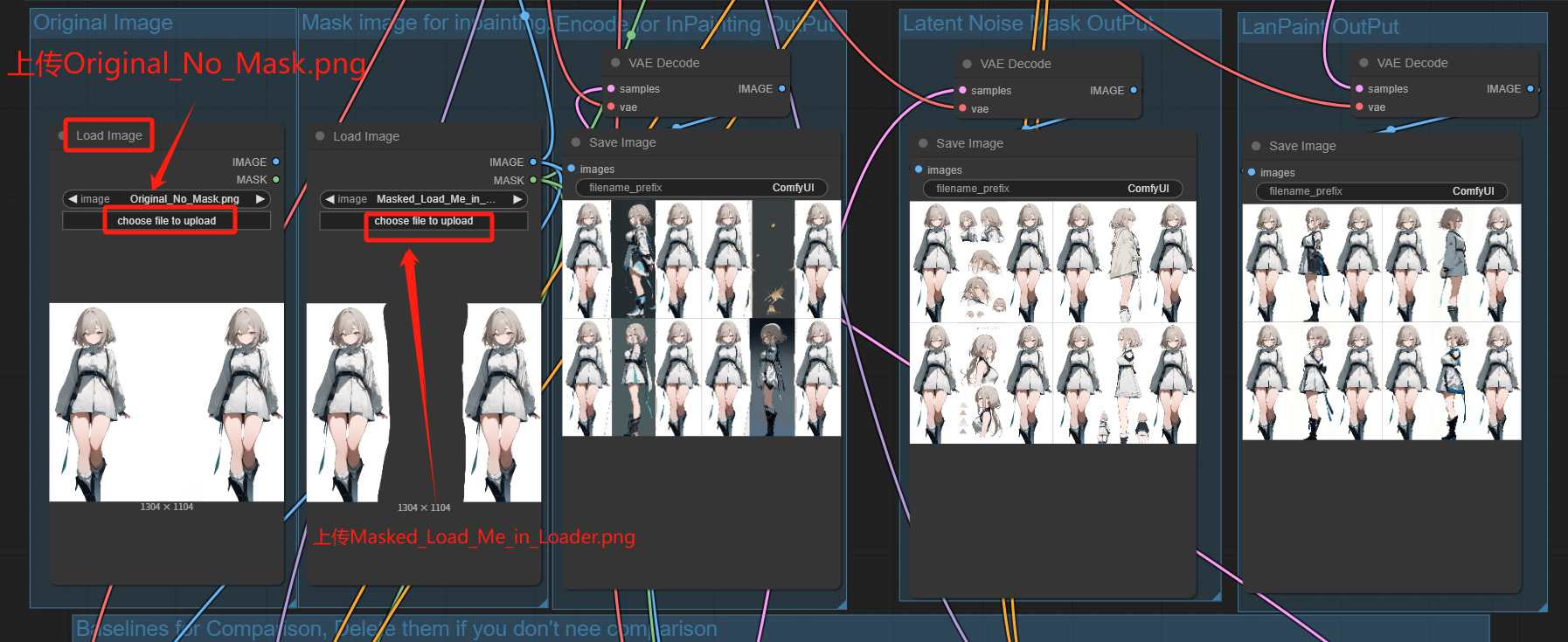
3. 将 Original_No_Mask.png 上传到 Load image 组(最左侧)中的 Original Image 节点(左一)。
4. 将 Masked_Load_Me_in_Loader.png 上传到 Mask image for inpainting 组中的 Load image 节点(左二)。
5. 本教程已添加了 8 个样例工作流所需的模型文件并且每个工作流会自行选择模型,您可以跳过此步骤,执行下一步(注意:若使用非样例工作流,请根据需求自行选择或下载模型)。
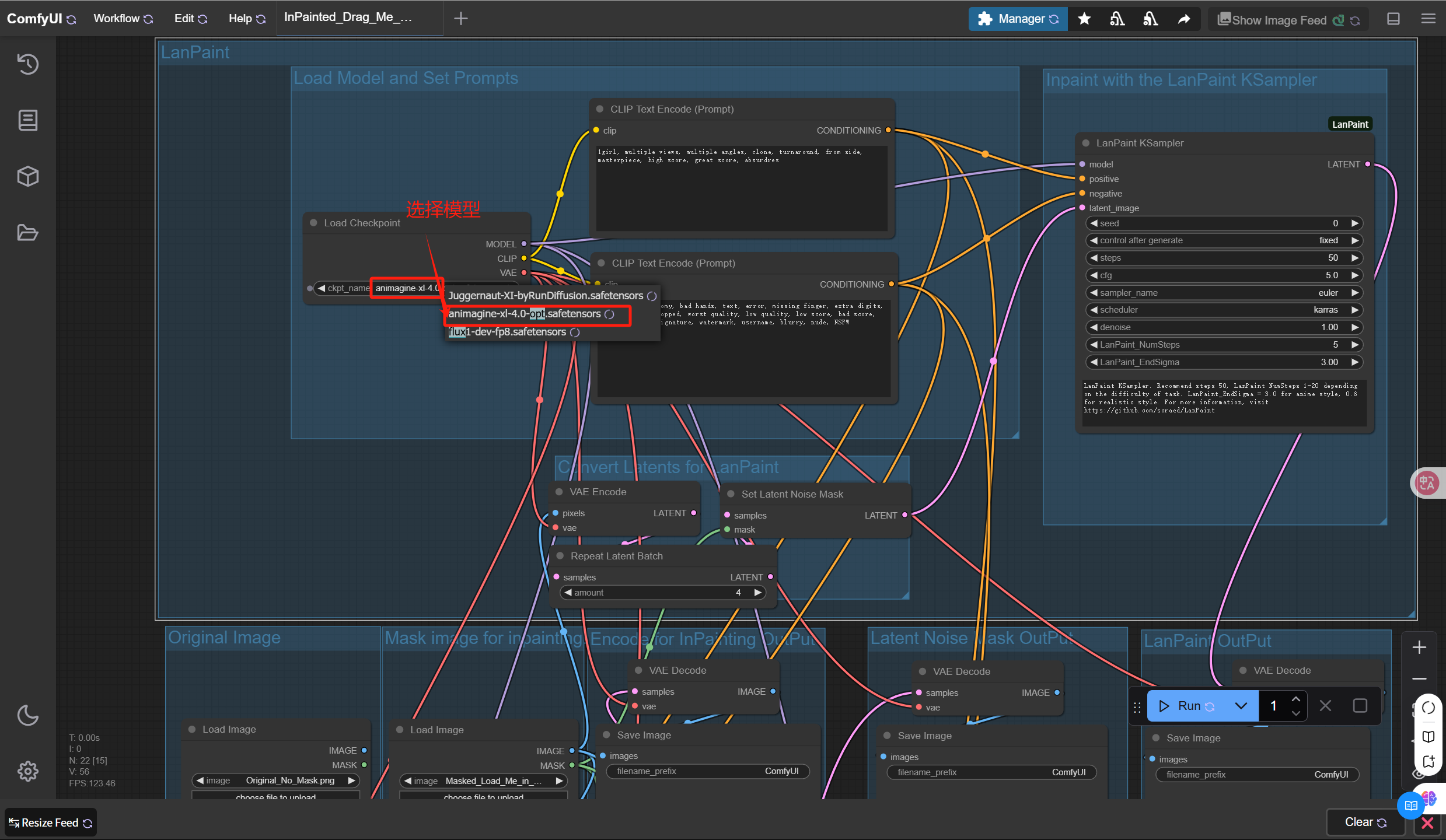
6. 设置基本采样器的参数,项目已设置好默认参数,若您无需修改参数,可以跳过此步骤,执行下一步。

Simplified interface, default settings are recommended:
- Steps: 50+ is recommended.
- LanPaint NumSteps: Number of steps to think before denoising. 5 is recommended for most tasks.
- LanPaint EndSigma: Noise levels below this level will disable thinking. Recommended setting is 0.6 for realistic style (tested on Juggernaut-xl) and 3.0 for anime style (tested on Animagine XL 4.0).
LanPaint KSampler (Advanced)
| parameter | scope | describe |
|---|---|---|
Steps | 0-100 | The total number of diffusion sampling steps. The higher the number of steps, the better the repair effect. It is recommended to set it to 50. |
LanPaint_NumSteps | 0-20 | The number of inference iterations (“deepness of thinking”) for each denoising step. Easy tasks: 1-2. Hard tasks: 5-10 |
LanPaint_Lambda | 0.1-50 | Content alignment strength (the higher the stricter). 8.0 is recommended |
LanPaint_StepSize | 0.1-1.0 | The recommended step size for each thinking step is 0.5. |
LanPaint_EndSigma | 0.0-20.0 | Noise level below which reflection is disabled. 0.3 – 3 is recommended. Higher values are faster but may hurt quality. Lower values are more reflective but may blur the output. |
LanPaint_cfg_BIG | -20-20 | CFG ratio used when aligning masked and non-masked regions (positive values tend to ignore cues, negative values enhance cues). When cues are not important, 8 is recommended for seamless restoration (e.g. limbs, faces). When cues are important, such as character consistency (i.e. multi-view), -0.5 is recommended |
7. 点击「Run」按钮,生成结果图像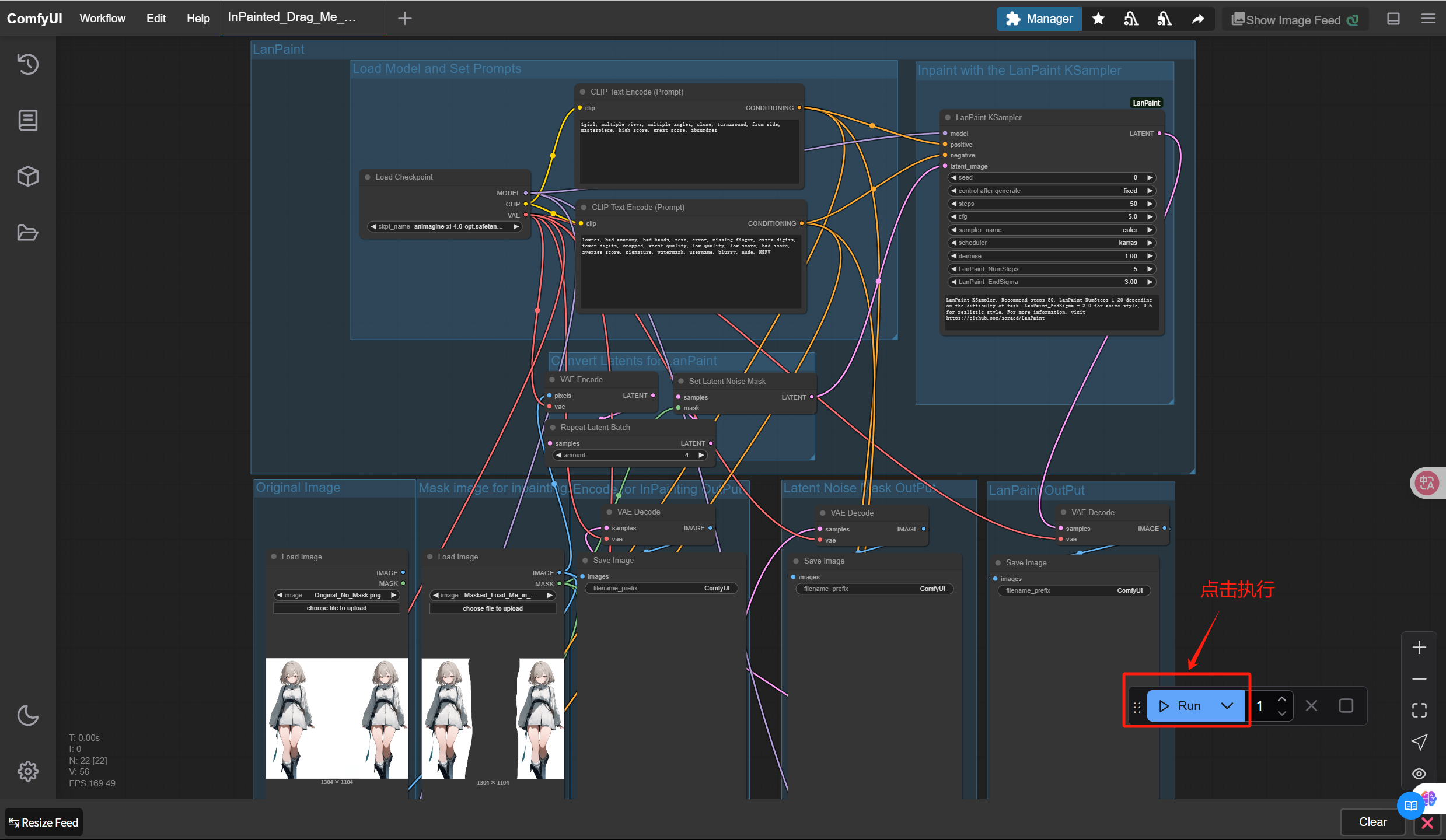
8. 您将通过 3 种方法获得最终的图像- VAE Inpainting Coding(middle)
- Setting the potential noise mask(Second from right)
- LanPaint (far right)

5. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@misc{zheng2025lanpainttrainingfreediffusioninpainting,
title={Lanpaint: Training-Free Diffusion Inpainting with Exact and Fast Conditional Inference},
author={Candi Zheng and Yuan Lan and Yang Wang},
year={2025},
eprint={2502.03491},
archivePrefix={arXiv},
primaryClass={eess.IV},
url={https://arxiv.org/abs/2502.03491},
}
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.