This tutorial uses a single-card A6000 as the resource. Currently, AI interaction only supports Chinese and English.
2. Project Examples
3. Operation steps
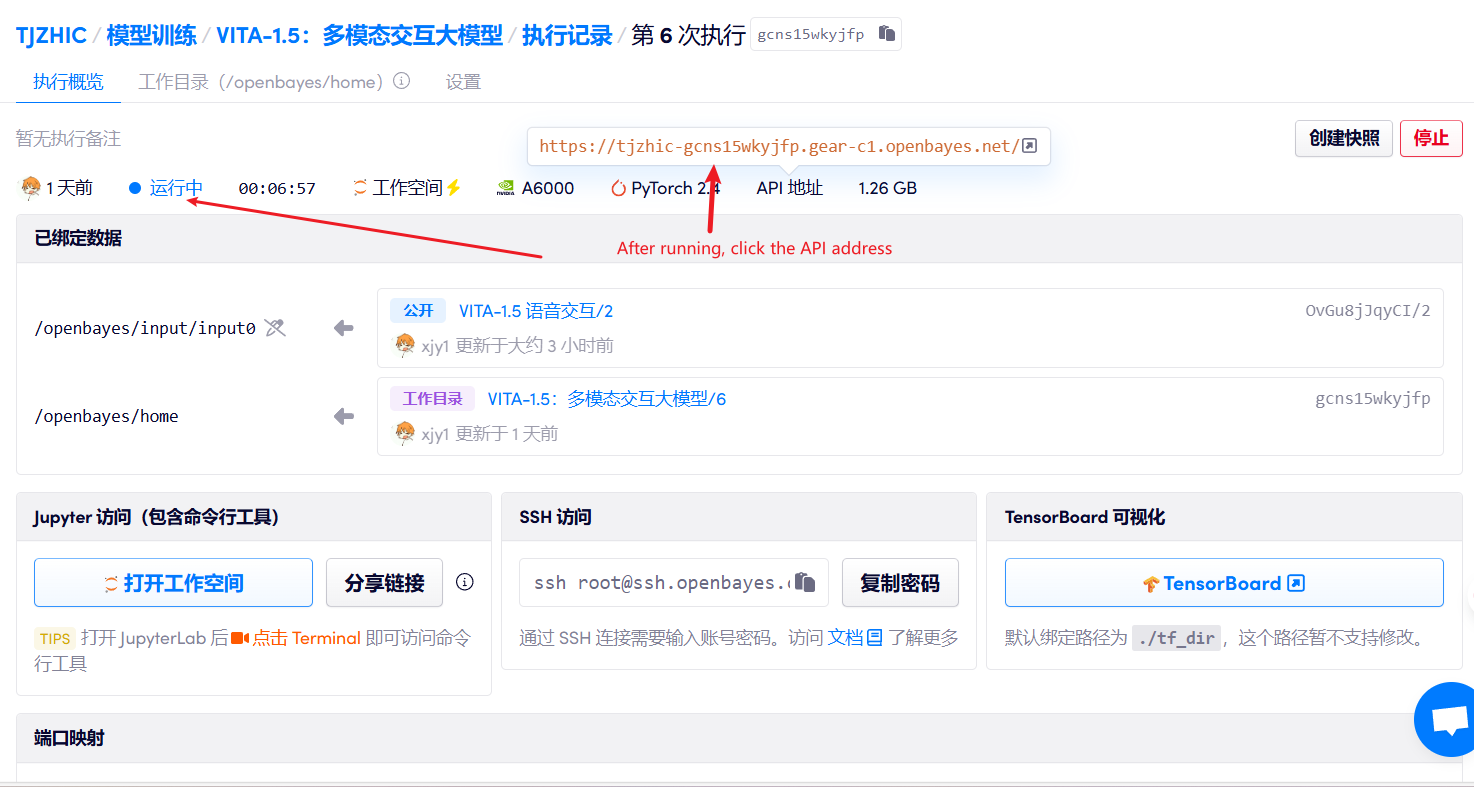
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
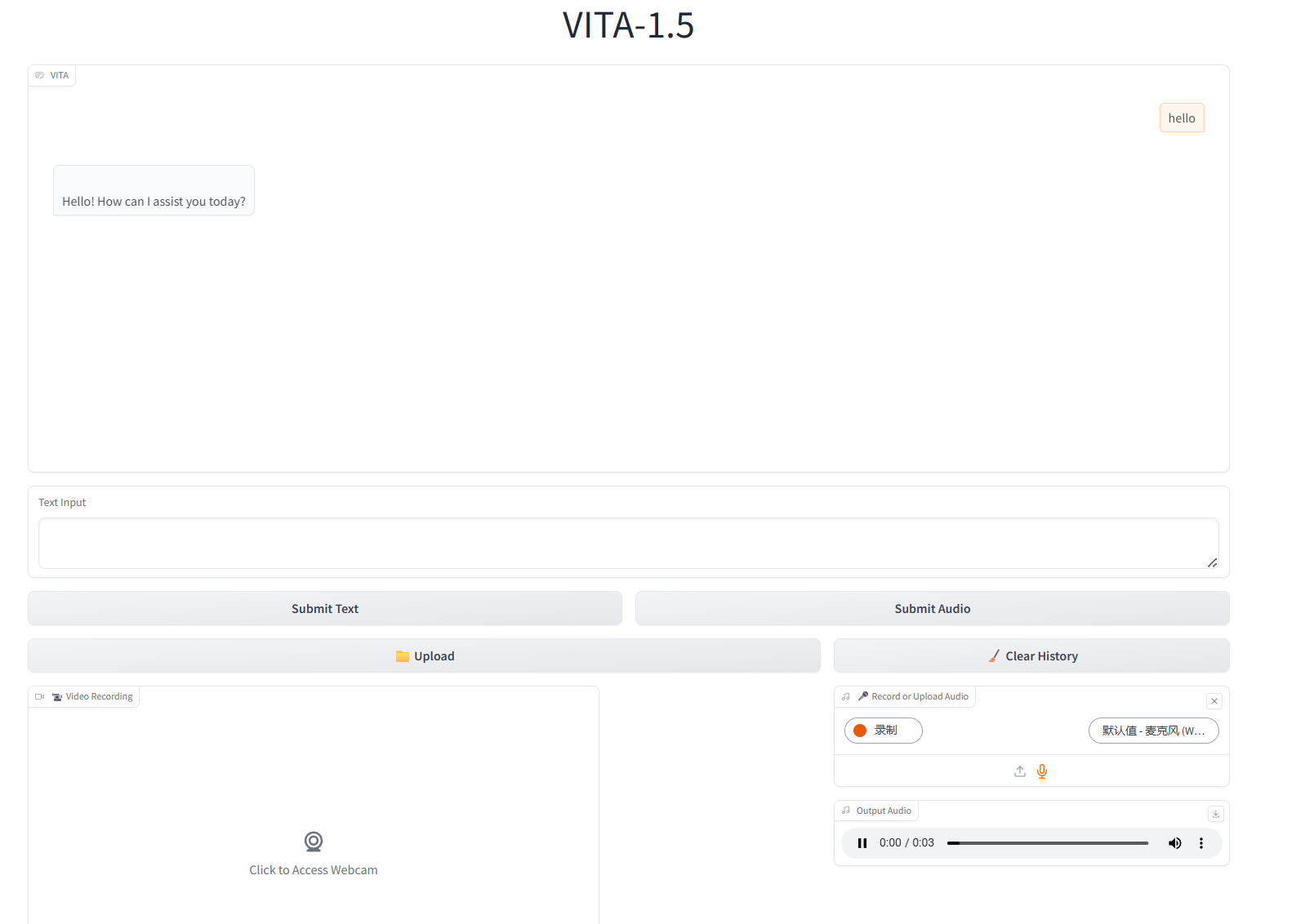
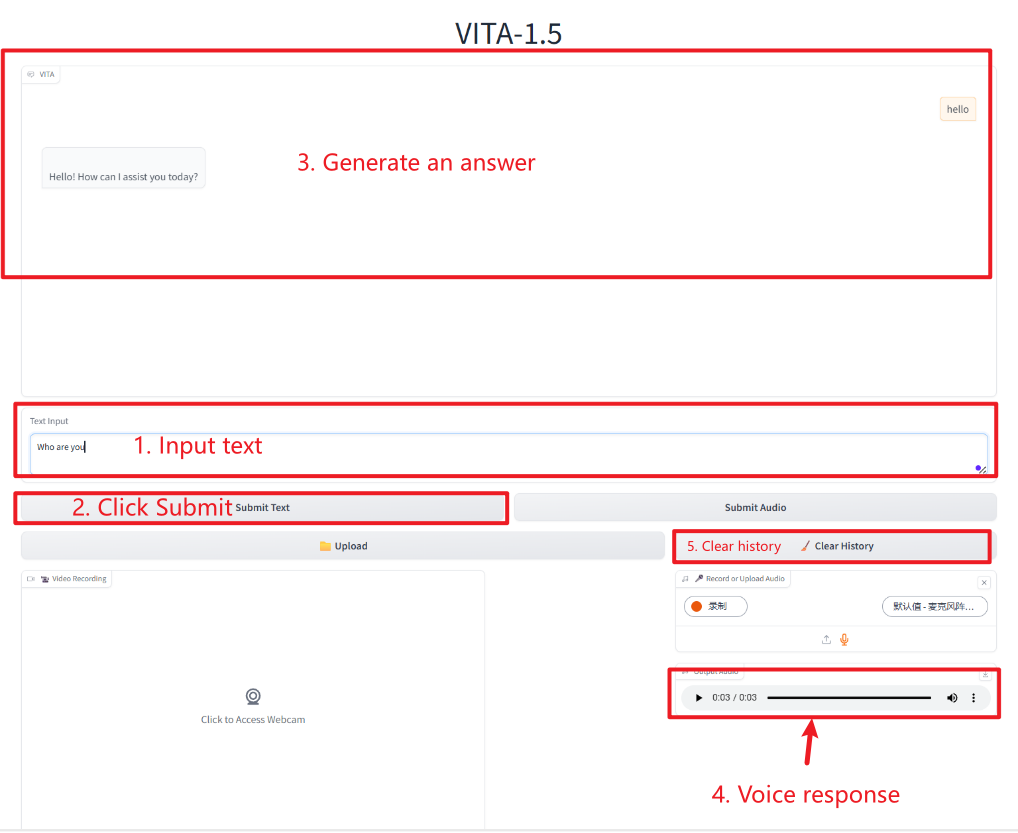
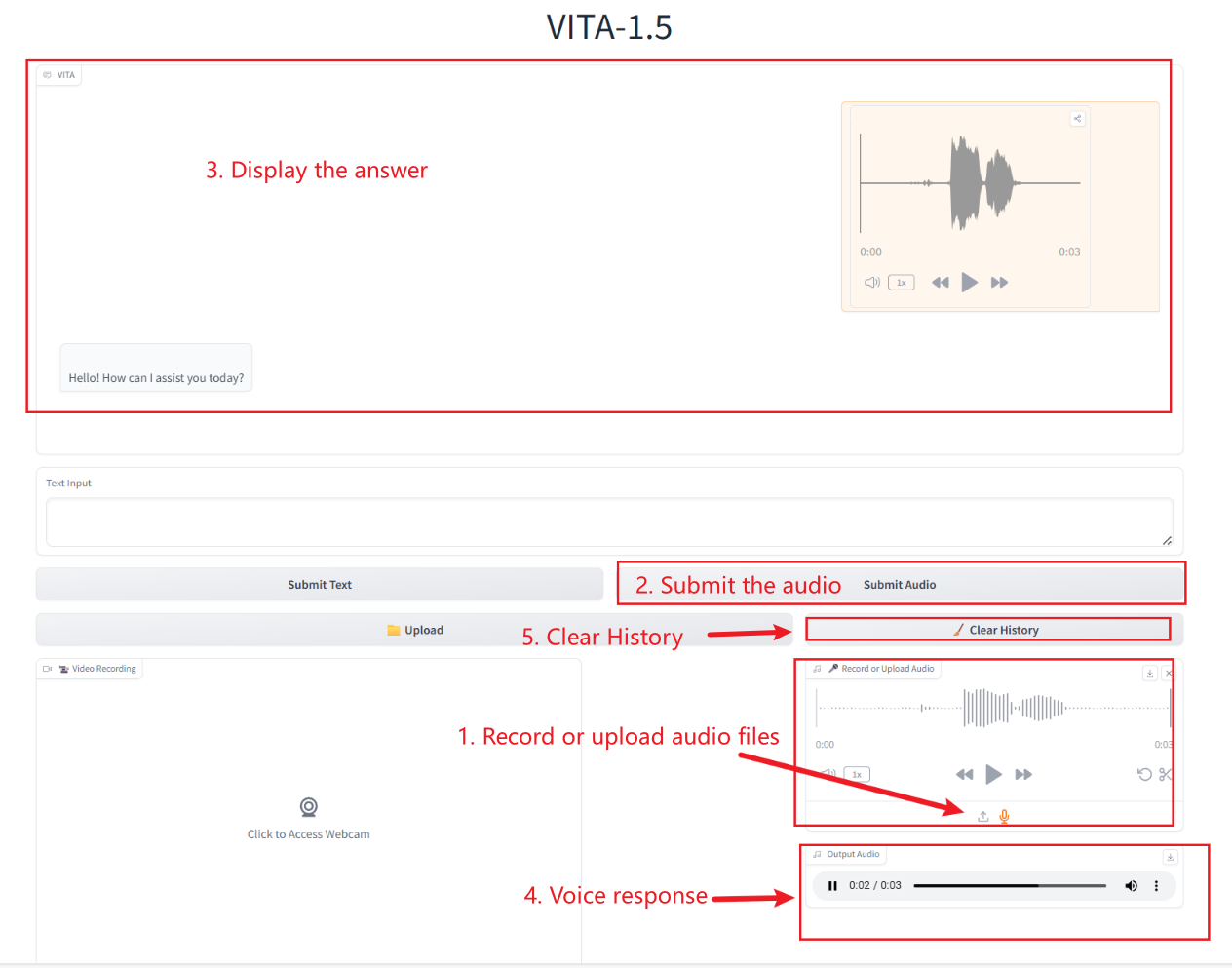
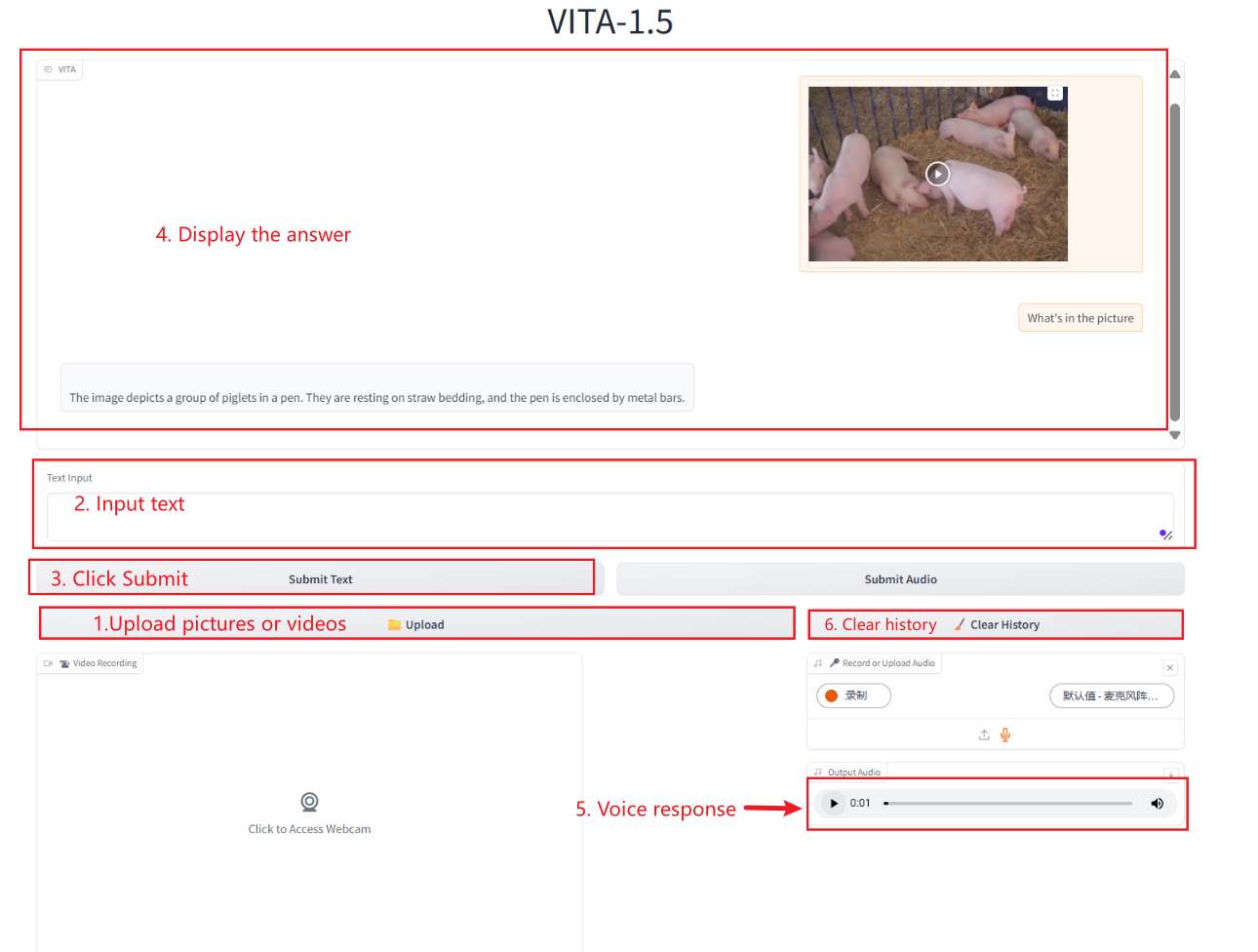
2. After entering the webpage, you can start a conversation with the model
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
How to use
This textbook has multiple AI interaction methods: text, audio, video, and pictures.
Text Interaction
Audio Interaction
Image/Video Interaction
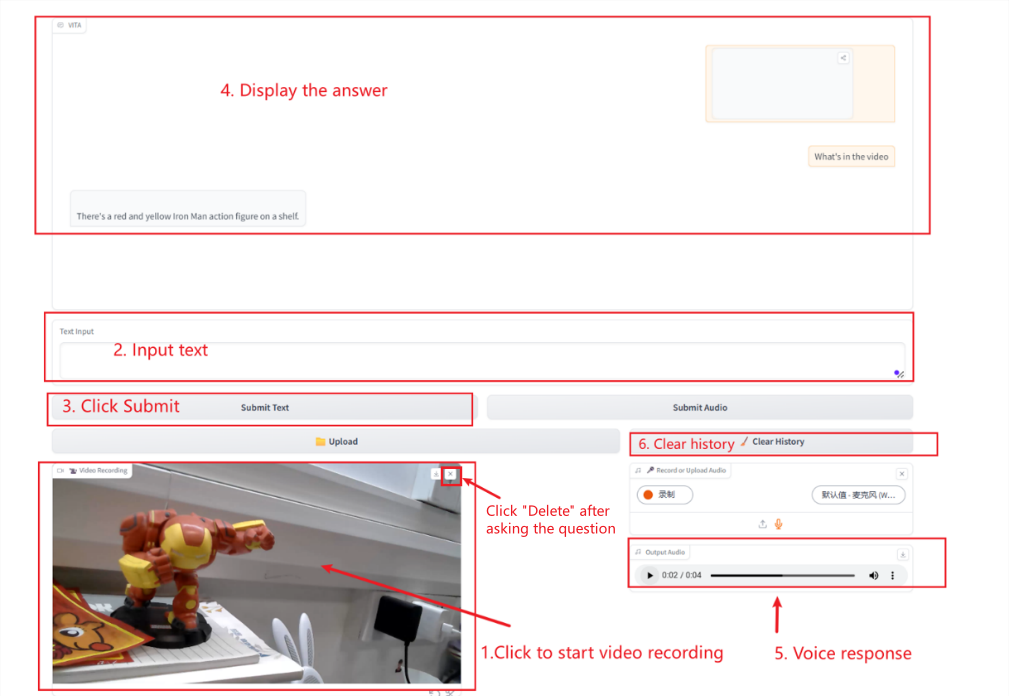
Video Interaction
Note:
When using a camera to record a video, the video needs to be deleted immediately after the question is completed.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
This tutorial uses a single-card A6000 as the resource. Currently, AI interaction only supports Chinese and English.
2. Project Examples
3. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. After entering the webpage, you can start a conversation with the model
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
How to use
This textbook has multiple AI interaction methods: text, audio, video, and pictures.
Text Interaction
Audio Interaction
Image/Video Interaction
Video Interaction
Note:
When using a camera to record a video, the video needs to be deleted immediately after the question is completed.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.