BAGEL-7B-MoT is an open-source multimodal foundational model released by ByteDance's Seed team on May 22, 2025. It aims to unify the understanding and generation tasks of multimodal data such as text, images, and videos. BAGEL demonstrates comprehensive capabilities in multimodal understanding and generation, complex reasoning and editing, world modeling and navigation, and other multimodal tasks. Its main functions include visual understanding, text-to-image generation, and image editing. Related research papers are available. Emerging Properties in Unified Multimodal Pretraining .
This tutorial uses dual-card A6000 computing resources and provides Image Generation, Image Generation with Think, Image Editing, Image Edit with Think, and Image Understanding for testing.
2. Effect display
3. Operation steps
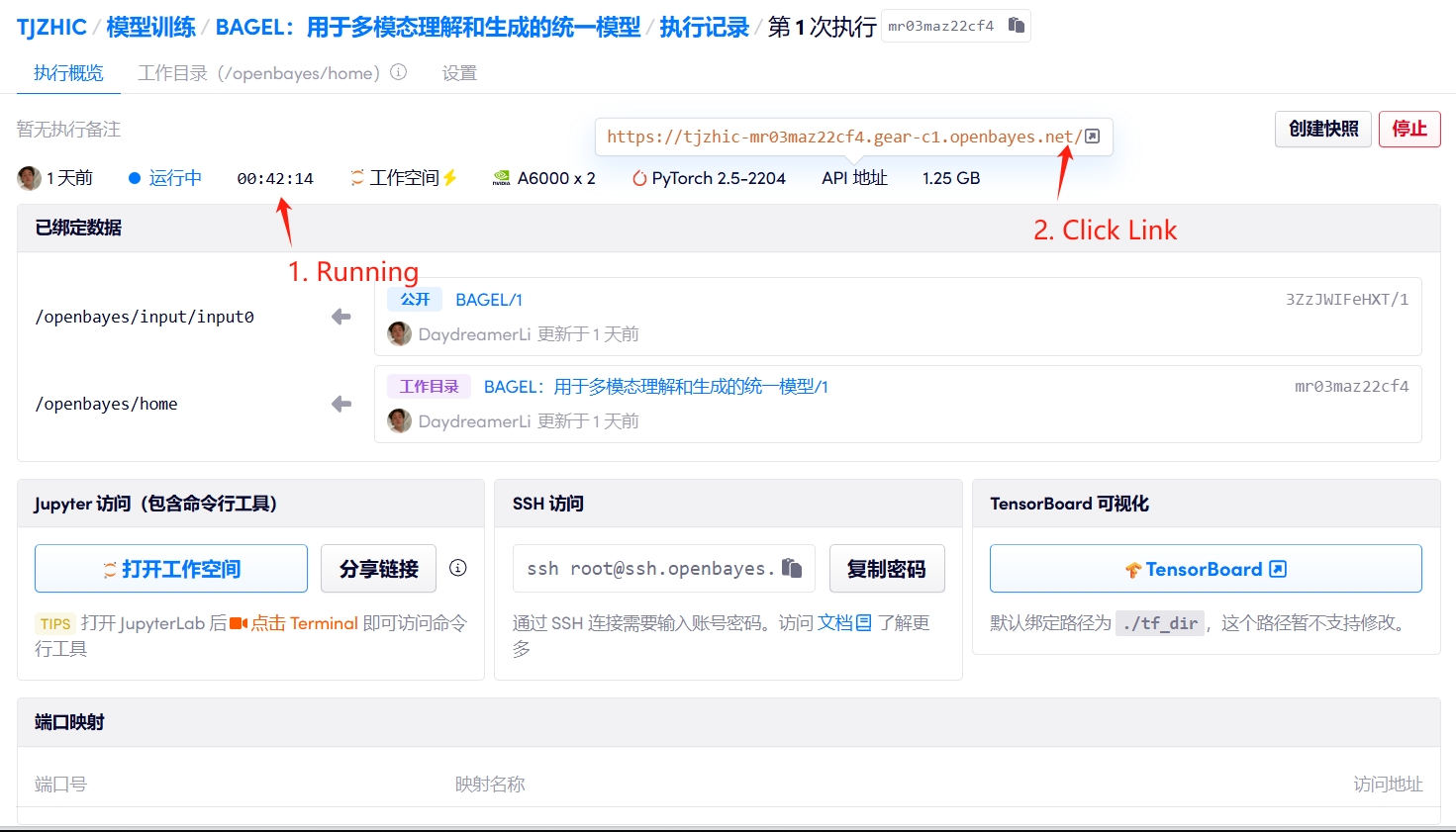
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
2. Usage Examples
2.1 Image Generation
Specific parameters:
Prompt: You can enter text to describe the content of the image here, and the model will generate an image based on this text.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Generation Steps: More steps equals better quality but slower speed.
Timestep Shift: Controls the generation process.
result
2.2 Image Generation with Thinking
Specific parameters:
Creative Prompt: You can enter text to describe the content of the image here, and the model will generate an image based on this text.
Max Thinking Tokens: Control the depth of reasoning.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Generation Steps: More steps equals better quality but slower speed.
Timestep Shift: Controls the generation process.
result
2.3 Image Editing
Specific parameters:
Upload Image: Upload the image that needs to be edited.
Edit Instruction: Edit instruction.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Editing Steps: More steps equals better quality but slower speed.
Edit Progression: Control the generation process.
Image Fidelity: Image fidelity, higher means more of the original image is preserved.
result
2.4 Image Editing with Think
Specific parameters:
Upload Image: Upload the image that needs to be edited.
Edit Instruction: Edit instruction.
Reasoning Depth: Reasoning depth.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Processing Steps: More steps equals better quality but slower speed.
Edit Progression: Control the generation process.
Original Preservation: Image fidelity, higher means more original is preserved.
result
2.5 Image Understanding
Specific parameters:
Upload Image: Upload the image that needs to be edited.
Your Question:Your question.
result
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@article{deng2025bagel,
title = {Emerging Properties in Unified Multimodal Pretraining},
author = {Deng, Chaorui and Zhu, Deyao and Li, Kunchang and Gou, Chenhui and Li, Feng and Wang, Zeyu and Zhong, Shu and Yu, Weihao and Nie, Xiaonan and Song, Ziang and Shi, Guang and Fan, Haoqi},
journal = {arXiv preprint arXiv:2505.14683},
year = {2025}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
BAGEL-7B-MoT is an open-source multimodal foundational model released by ByteDance's Seed team on May 22, 2025. It aims to unify the understanding and generation tasks of multimodal data such as text, images, and videos. BAGEL demonstrates comprehensive capabilities in multimodal understanding and generation, complex reasoning and editing, world modeling and navigation, and other multimodal tasks. Its main functions include visual understanding, text-to-image generation, and image editing. Related research papers are available. Emerging Properties in Unified Multimodal Pretraining .
This tutorial uses dual-card A6000 computing resources and provides Image Generation, Image Generation with Think, Image Editing, Image Edit with Think, and Image Understanding for testing.
2. Effect display
3. Operation steps
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
2. Usage Examples
2.1 Image Generation
Specific parameters:
Prompt: You can enter text to describe the content of the image here, and the model will generate an image based on this text.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Generation Steps: More steps equals better quality but slower speed.
Timestep Shift: Controls the generation process.
result
2.2 Image Generation with Thinking
Specific parameters:
Creative Prompt: You can enter text to describe the content of the image here, and the model will generate an image based on this text.
Max Thinking Tokens: Control the depth of reasoning.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Generation Steps: More steps equals better quality but slower speed.
Timestep Shift: Controls the generation process.
result
2.3 Image Editing
Specific parameters:
Upload Image: Upload the image that needs to be edited.
Edit Instruction: Edit instruction.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Editing Steps: More steps equals better quality but slower speed.
Edit Progression: Control the generation process.
Image Fidelity: Image fidelity, higher means more of the original image is preserved.
result
2.4 Image Editing with Think
Specific parameters:
Upload Image: Upload the image that needs to be edited.
Edit Instruction: Edit instruction.
Reasoning Depth: Reasoning depth.
Text Guidance Scale: Controls how much influence the prompt has on the output. Higher values have a greater impact.
Processing Steps: More steps equals better quality but slower speed.
Edit Progression: Control the generation process.
Original Preservation: Image fidelity, higher means more original is preserved.
result
2.5 Image Understanding
Specific parameters:
Upload Image: Upload the image that needs to be edited.
Your Question:Your question.
result
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@article{deng2025bagel,
title = {Emerging Properties in Unified Multimodal Pretraining},
author = {Deng, Chaorui and Zhu, Deyao and Li, Kunchang and Gou, Chenhui and Li, Feng and Wang, Zeyu and Zhong, Shu and Yu, Weihao and Nie, Xiaonan and Song, Ziang and Shi, Guang and Fan, Haoqi},
journal = {arXiv preprint arXiv:2505.14683},
year = {2025}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.