The computing resources used in this tutorial are a single A6000 card.
Kimi-Audio-7B-Instruct is an open-source audio foundation model released by KimiTeam on April 28, 2025. The model can handle various audio processing tasks within a single, unified framework. Related research papers include... Kimi-Audio Technical Report The main functions include:
General purpose capabilities: handles a variety of tasks such as automatic speech recognition (ASR), audio question answering (AQA), automatic audio captioning (AAC), speech emotion recognition (SER), sound event/scene classification (SEC/ASC), and end-to-end voice dialogue.
Industry-leading performance: Achieves SOTA levels in multiple audio benchmarks.
Large-scale pre-training: Pre-training on over 13 million hours of various audio data (speech, music, sound) and text data to enable powerful audio reasoning and language understanding.
Innovative architecture: Using hybrid audio input (continuous acoustic vector + discrete semantic tags) and LLM core with parallel processing capabilities, text and audio tags can be generated simultaneously.
Efficient Inference: Chunked streaming demultiplexer with stream matching for low-latency audio generation.
Open Source: Release code and model checkpoints for pre-training and instruction fine-tuning, and release a comprehensive evaluation toolkit to promote community research and development.
2. Operation steps
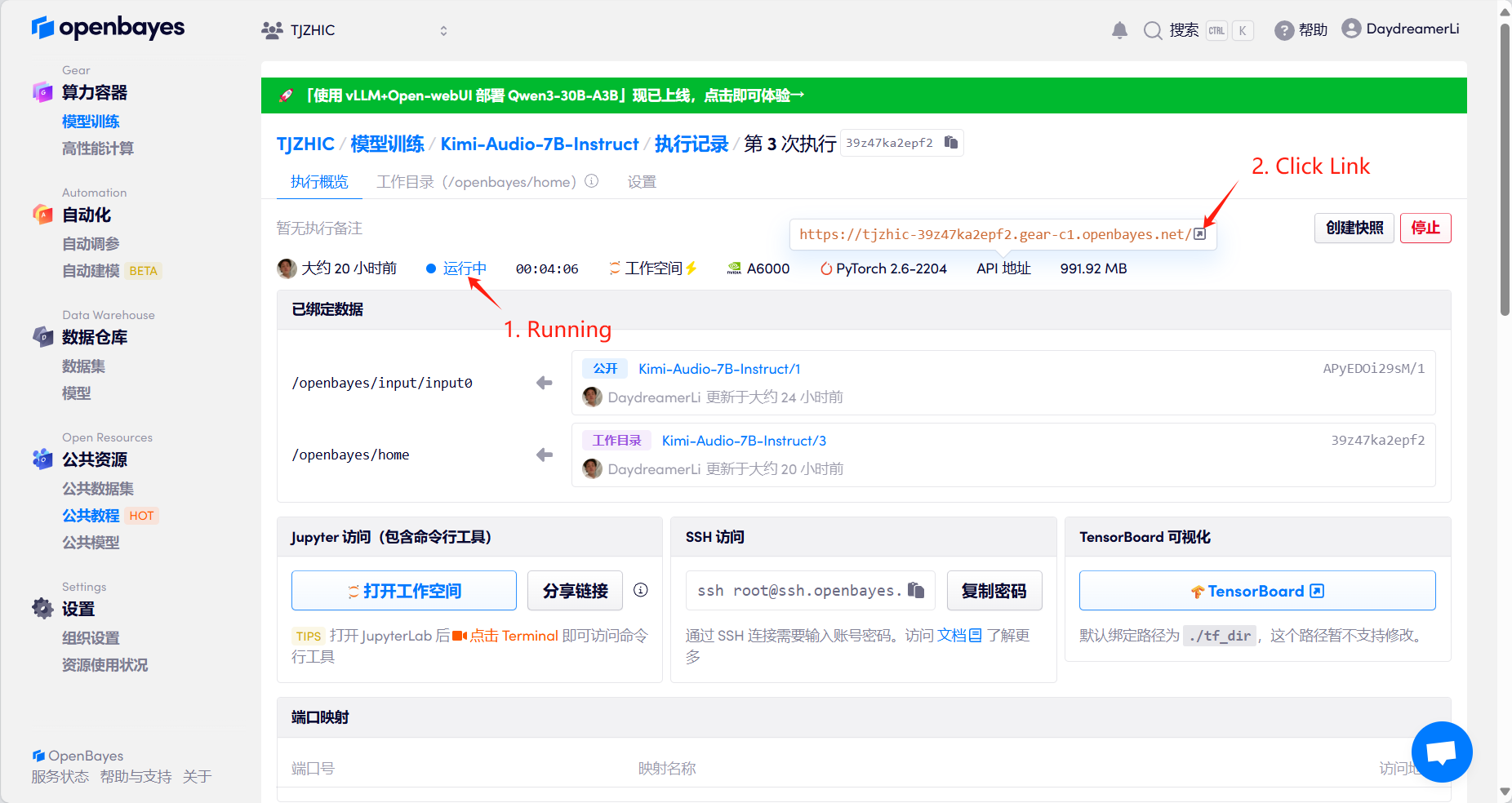
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 3-5 minutes and refresh the page.
2. Usage Examples
Usage Guidelines
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
This tutorial provides two module tests: Voice transcription and Voice conversation.
The functions of each module are as follows:
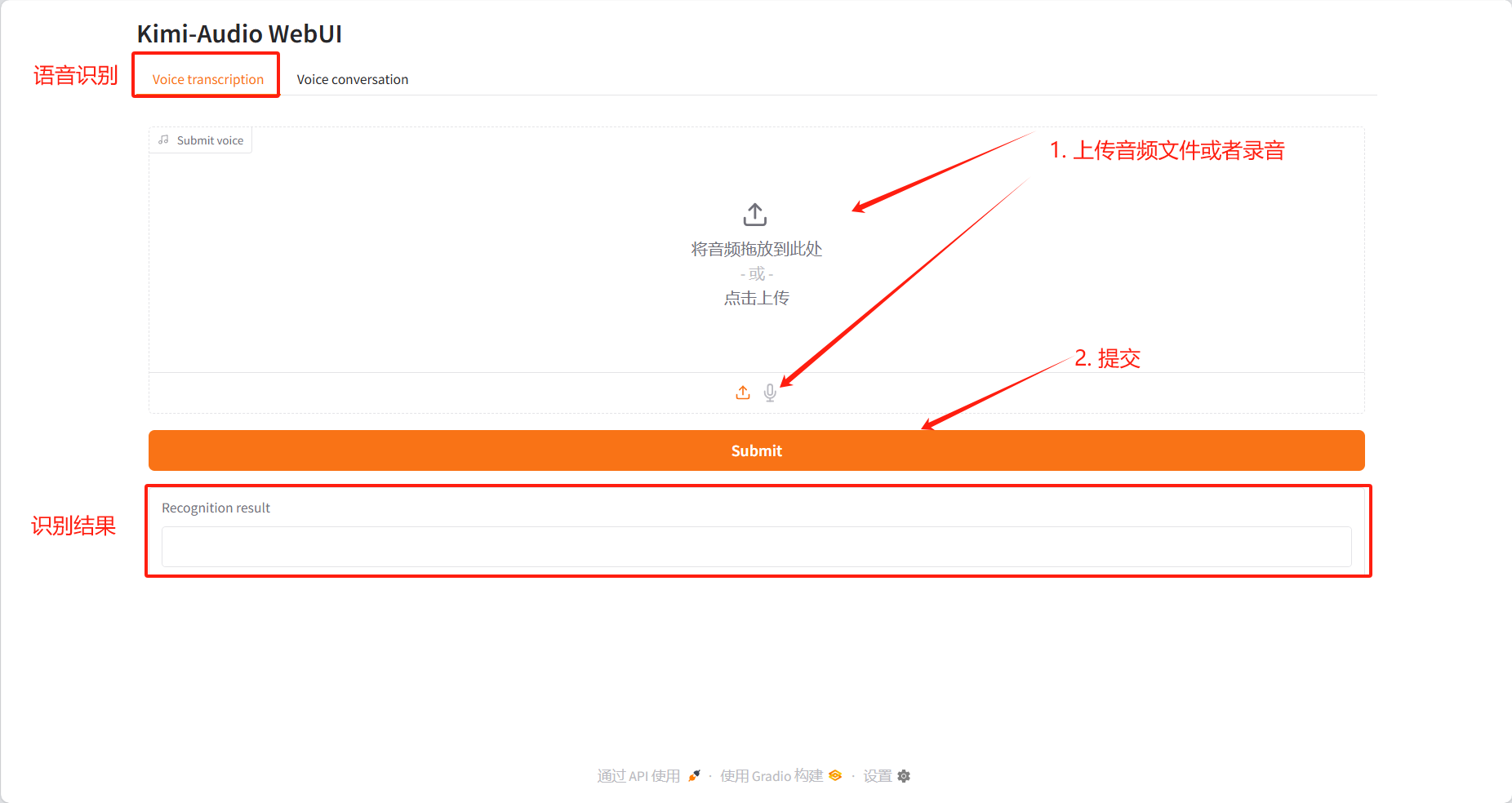
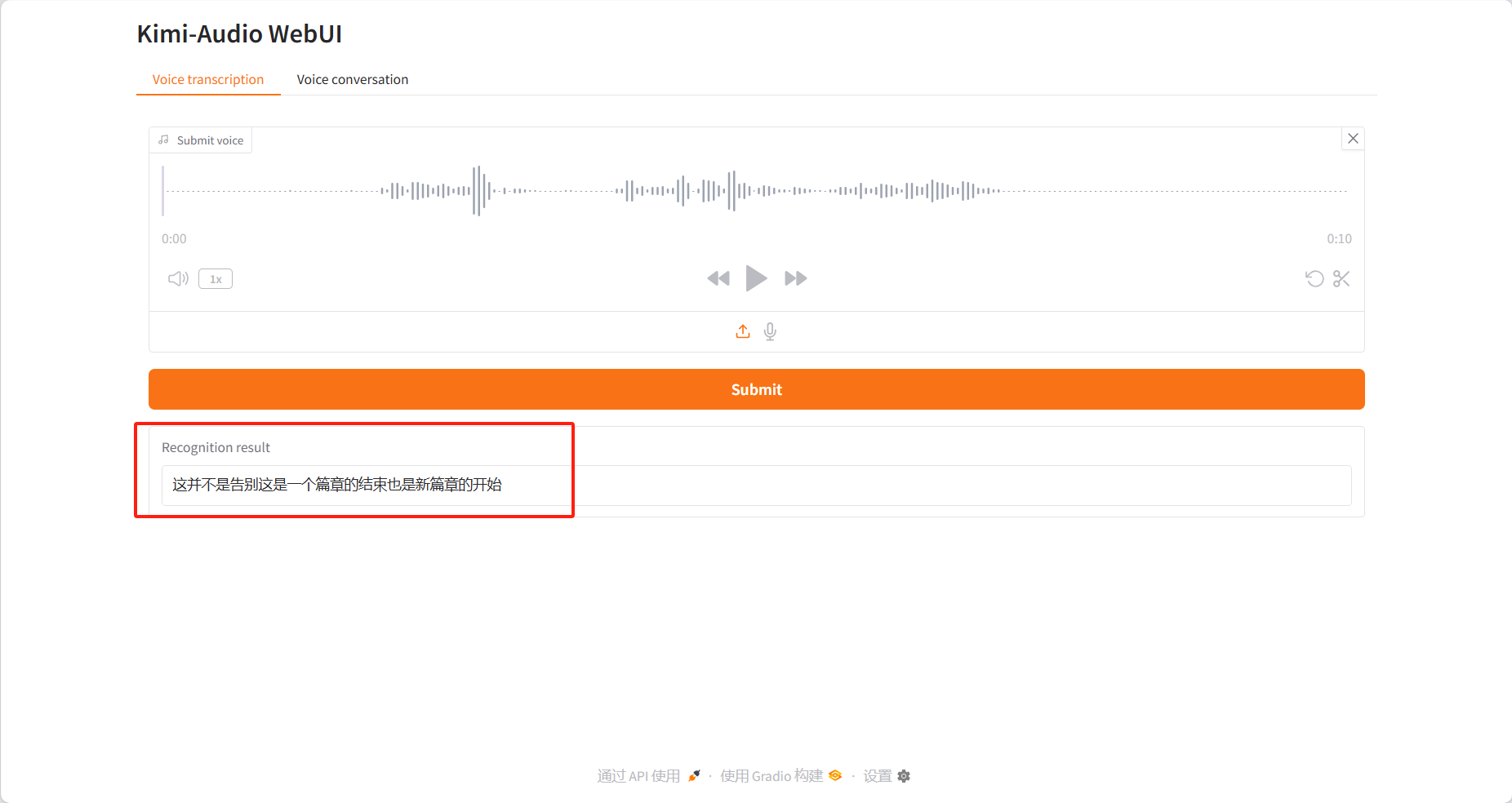
Voice transcription
Identification results
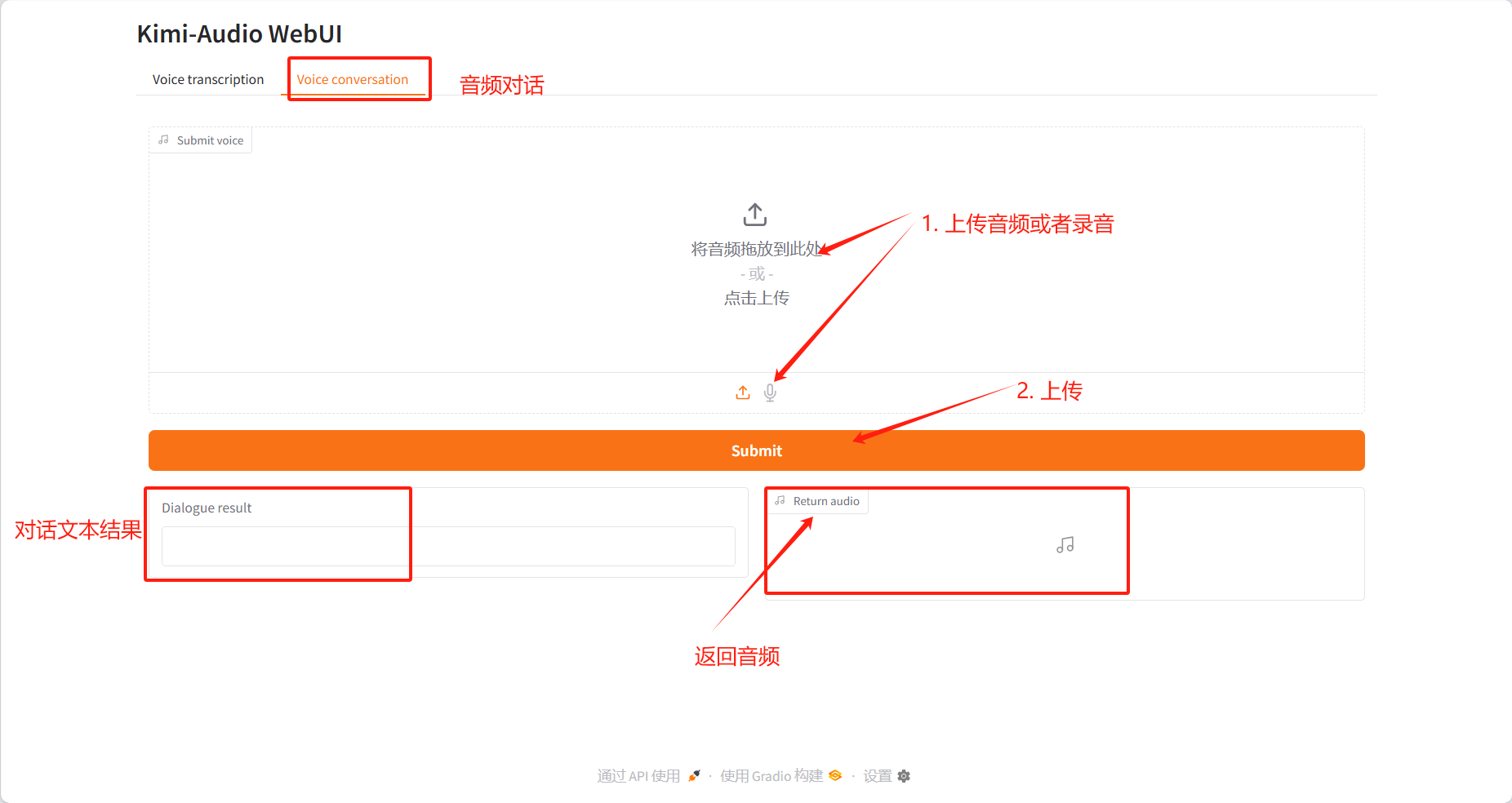
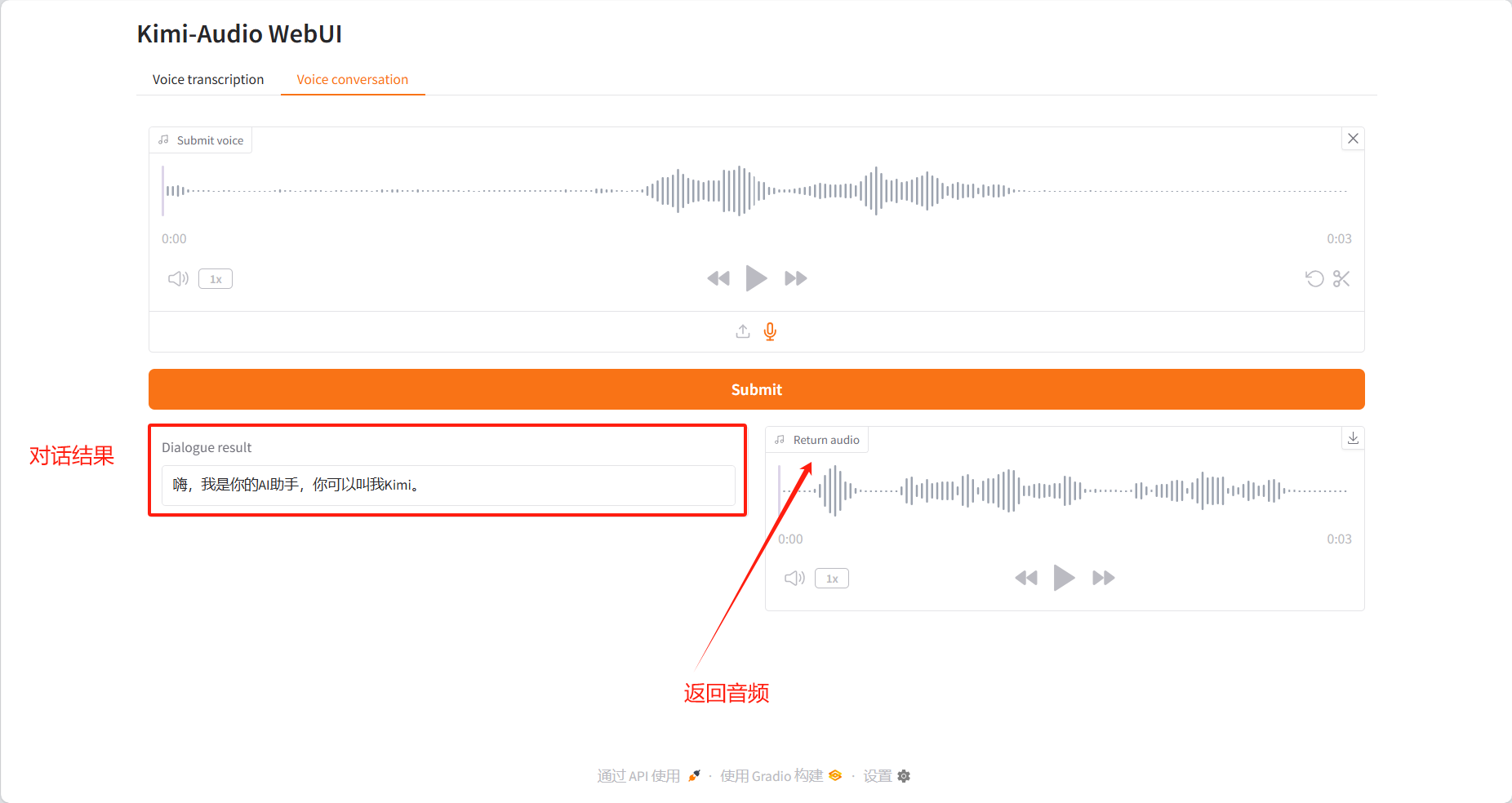
Voice conversation
Dialogue Results
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
Thanks to Github user SuperYang Deployment of this tutorial. The reference information of this project is as follows:
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
The computing resources used in this tutorial are a single A6000 card.
Kimi-Audio-7B-Instruct is an open-source audio foundation model released by KimiTeam on April 28, 2025. The model can handle various audio processing tasks within a single, unified framework. Related research papers include... Kimi-Audio Technical Report The main functions include:
General purpose capabilities: handles a variety of tasks such as automatic speech recognition (ASR), audio question answering (AQA), automatic audio captioning (AAC), speech emotion recognition (SER), sound event/scene classification (SEC/ASC), and end-to-end voice dialogue.
Industry-leading performance: Achieves SOTA levels in multiple audio benchmarks.
Large-scale pre-training: Pre-training on over 13 million hours of various audio data (speech, music, sound) and text data to enable powerful audio reasoning and language understanding.
Innovative architecture: Using hybrid audio input (continuous acoustic vector + discrete semantic tags) and LLM core with parallel processing capabilities, text and audio tags can be generated simultaneously.
Efficient Inference: Chunked streaming demultiplexer with stream matching for low-latency audio generation.
Open Source: Release code and model checkpoints for pre-training and instruction fine-tuning, and release a comprehensive evaluation toolkit to promote community research and development.
2. Operation steps
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 3-5 minutes and refresh the page.
2. Usage Examples
Usage Guidelines
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
This tutorial provides two module tests: Voice transcription and Voice conversation.
The functions of each module are as follows:
Voice transcription
Identification results
Voice conversation
Dialogue Results
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
Thanks to Github user SuperYang Deployment of this tutorial. The reference information of this project is as follows:
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.