This tutorial uses resources for a single RTX 4090 card.
👉 This project provides a model of:
MegaTTS 3: A TTS system with an innovative sparsely aligned guided "latent diffuse transformer" algorithm that achieves state-of-the-art zero-sample TTS voice quality and supports highly flexible control of accent strength. The input timbre can be cloned and used to generate specific audio content as required.
2. Operation steps
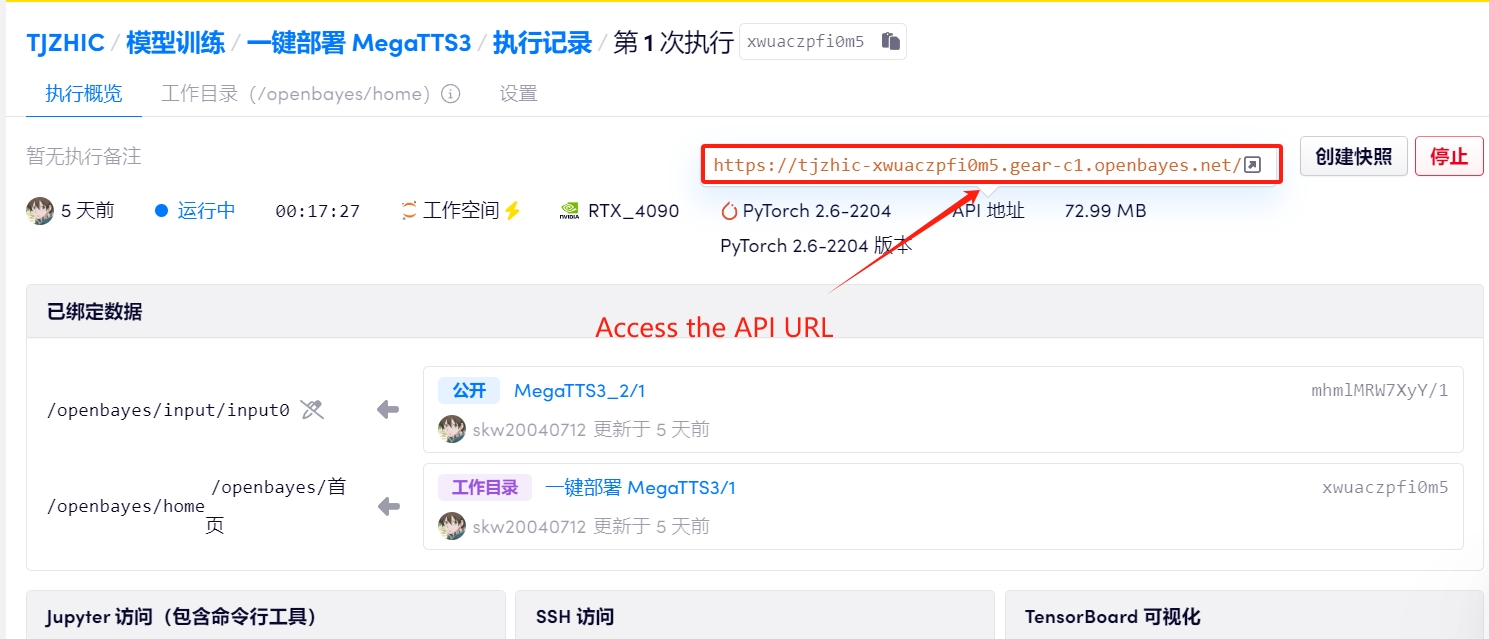
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. Once you enter the web page, you can use MegaTTS 3
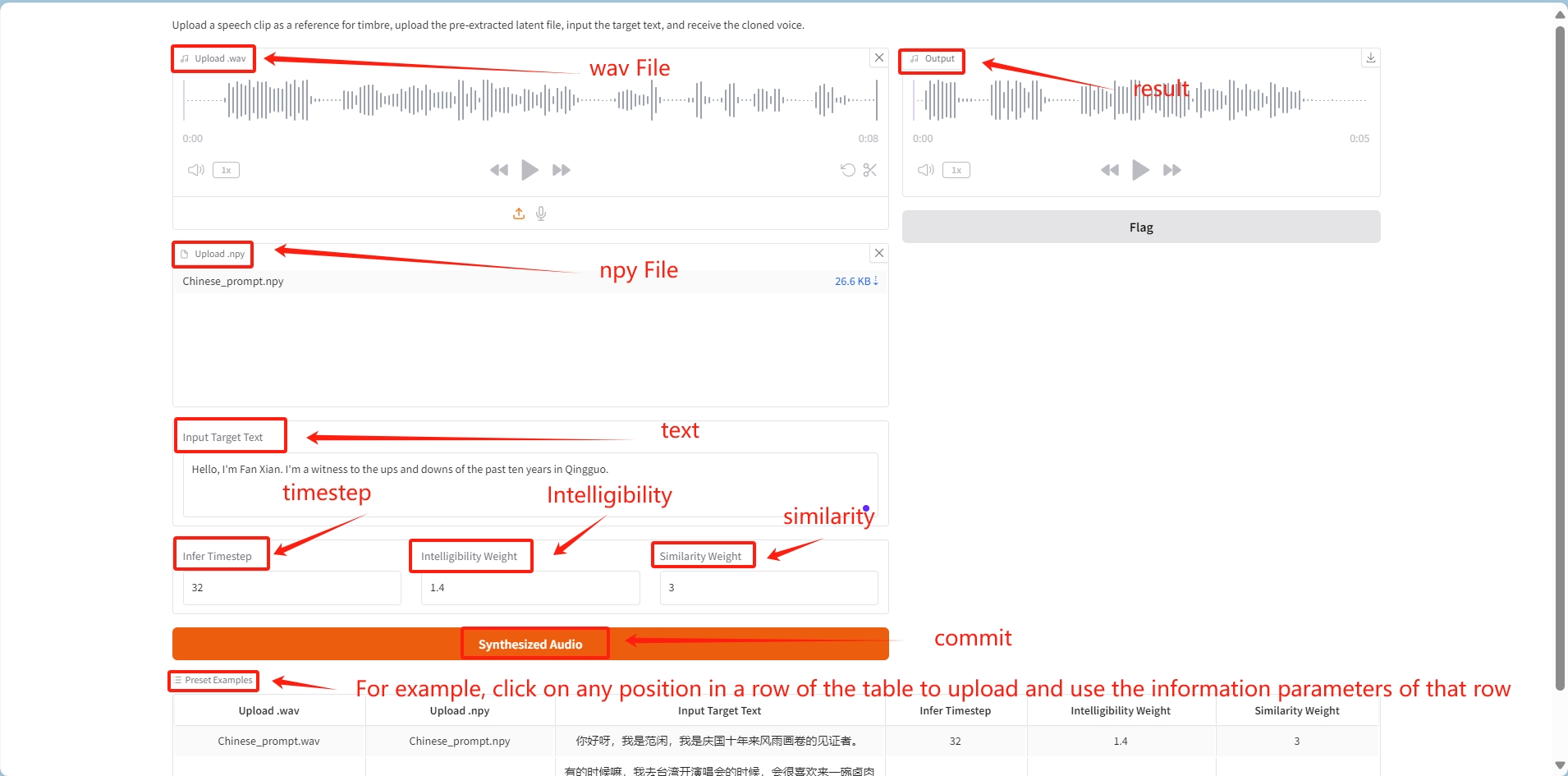
How to use
① Upload the wav audio file and the corresponding generated npy file separately;
② Enter the specified text in input_text;
③ After submitting, the timbre in the audio file will be cloned to generate the audio corresponding to the text in input_text.
❗️Parameter description:
infer timestep: Affects the time step of the model generating sound, usually controlling the number of time steps in the generation process. A smaller timestep may make the sound smoother because the model has more time steps to refine the sound features.
Intelligibility Weight: Adjusts the clarity and intelligibility of the sound. A higher weight makes the sound clearer, suitable for scenes that need to convey information accurately, but may sacrifice some naturalness.
Similarity Weight: Controls the similarity between the generated sound and the original sound. A higher weight makes the sound closer to the original sound, which is suitable for scenarios where the target voice needs to be faithfully reproduced.
Get sample file
Go to the website https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlrThere are three subfolders (librispeech_testclean_40, official_test_case, user_batch_1-3) containing all currently available timbres. After entering the folder, listen to and download the wav file and npy file.
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
Thanks to Github user kjasdk For the production of this tutorial, the project reference information is as follows:
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
This tutorial uses resources for a single RTX 4090 card.
👉 This project provides a model of:
MegaTTS 3: A TTS system with an innovative sparsely aligned guided "latent diffuse transformer" algorithm that achieves state-of-the-art zero-sample TTS voice quality and supports highly flexible control of accent strength. The input timbre can be cloned and used to generate specific audio content as required.
2. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. Once you enter the web page, you can use MegaTTS 3
How to use
① Upload the wav audio file and the corresponding generated npy file separately;
② Enter the specified text in input_text;
③ After submitting, the timbre in the audio file will be cloned to generate the audio corresponding to the text in input_text.
❗️Parameter description:
infer timestep: Affects the time step of the model generating sound, usually controlling the number of time steps in the generation process. A smaller timestep may make the sound smoother because the model has more time steps to refine the sound features.
Intelligibility Weight: Adjusts the clarity and intelligibility of the sound. A higher weight makes the sound clearer, suitable for scenes that need to convey information accurately, but may sacrifice some naturalness.
Similarity Weight: Controls the similarity between the generated sound and the original sound. A higher weight makes the sound closer to the original sound, which is suitable for scenarios where the target voice needs to be faithfully reproduced.
Get sample file
Go to the website https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlrThere are three subfolders (librispeech_testclean_40, official_test_case, user_batch_1-3) containing all currently available timbres. After entering the folder, listen to and download the wav file and npy file.
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
Thanks to Github user kjasdk For the production of this tutorial, the project reference information is as follows:
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.