The Qwen3 project was released by Alibaba’s Qwen team in 2025. The relevant technical report is Qwen3: Think Deeper, Act Faster .
Qwen3 is the latest generation of large-scale language models in the Qwen series, providing comprehensive dense models and mixture of experts (MoE) models. Based on rich training experience, Qwen3 has made breakthrough progress in reasoning, instruction following, agent capabilities, and multi-language support. The application scenarios of Qwen3 are very wide. It supports text, image, audio, and video processing, and can meet the needs of multimodal content creation and cross-modal tasks. In enterprise-level applications, Qwen3's agent capabilities and multi-language support enable it to be competent for complex tasks such as medical diagnosis, legal document analysis, and customer service automation. In addition, small models such as Qwen3-0.6B are suitable for deployment on end-side devices such as mobile phones, further expanding its application scenarios.
The latest version Qwen3 has the following features:
Full size dense and mixed expert models: 0.6B, 1.7B, 4B, 8B, 14B, 32B and 30B-A3B, 235B-A22B
Supports seamless switching between thinking mode (for complex logical reasoning, mathematics, and coding) and non-thinking mode (for efficient general conversations), ensuring optimal performance in various scenarios.
Significantly enhanced reasoning capabilities, surpassing the previous QwQ (in thinking mode) and Qwen2.5 instruction model (in non-thinking mode) in mathematics, code generation, and common sense logic reasoning.
Superior alignment with human preferences, excels in creative writing, role-playing, multi-turn conversations, and command following, providing a more natural, engaging, and immersive conversational experience.
Excels in intelligent agent capabilities, can accurately integrate external tools in both thinking and non-thinking modes, and leads in open source models in complex agent-based tasks.
It supports more than 100 languages and dialects, and has powerful multi-language understanding, reasoning, command following and generation capabilities.
2. Operation steps
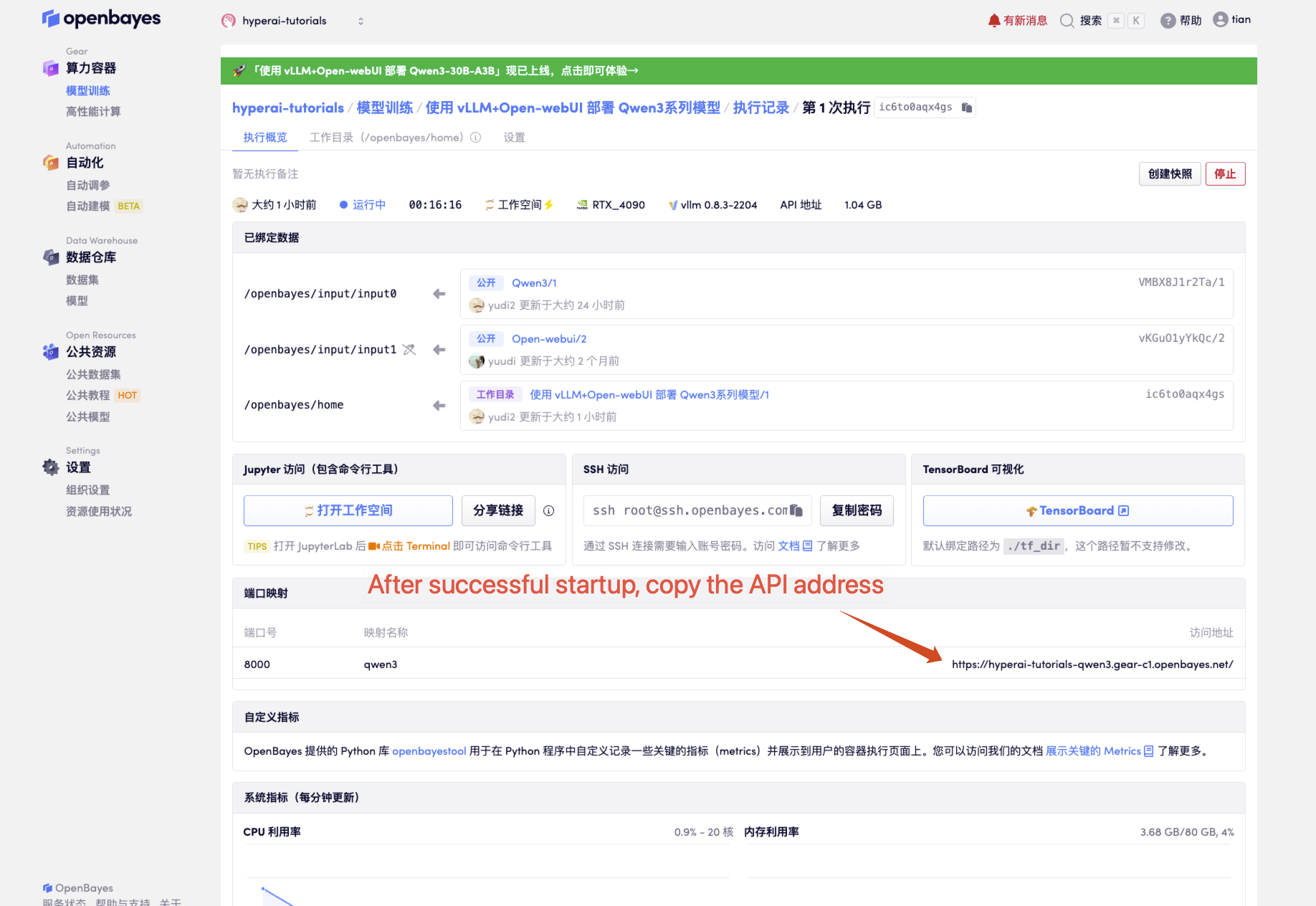
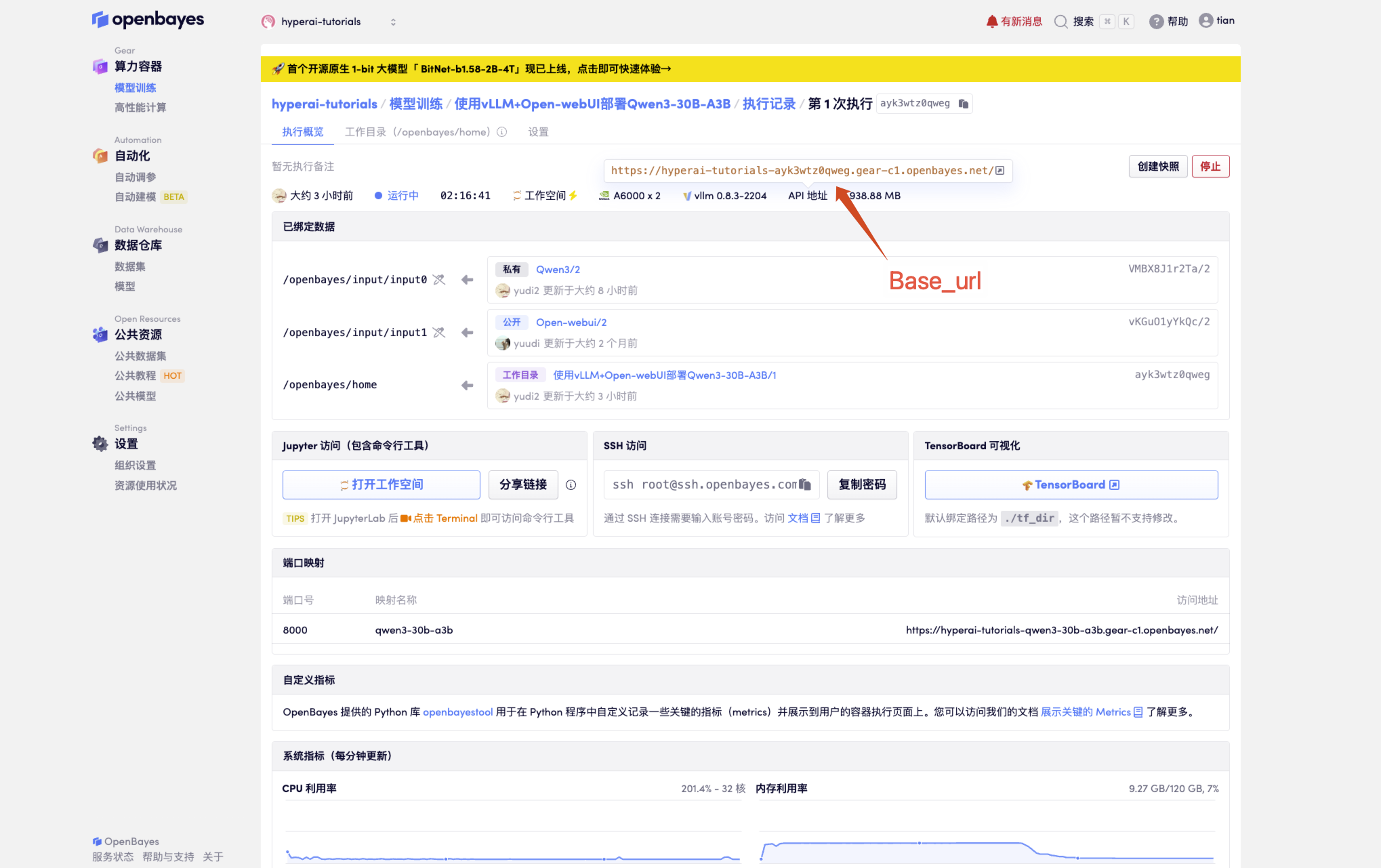
1. After starting the container, click the API address to enter the Web interface
If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 1-2 minutes and refresh the page.
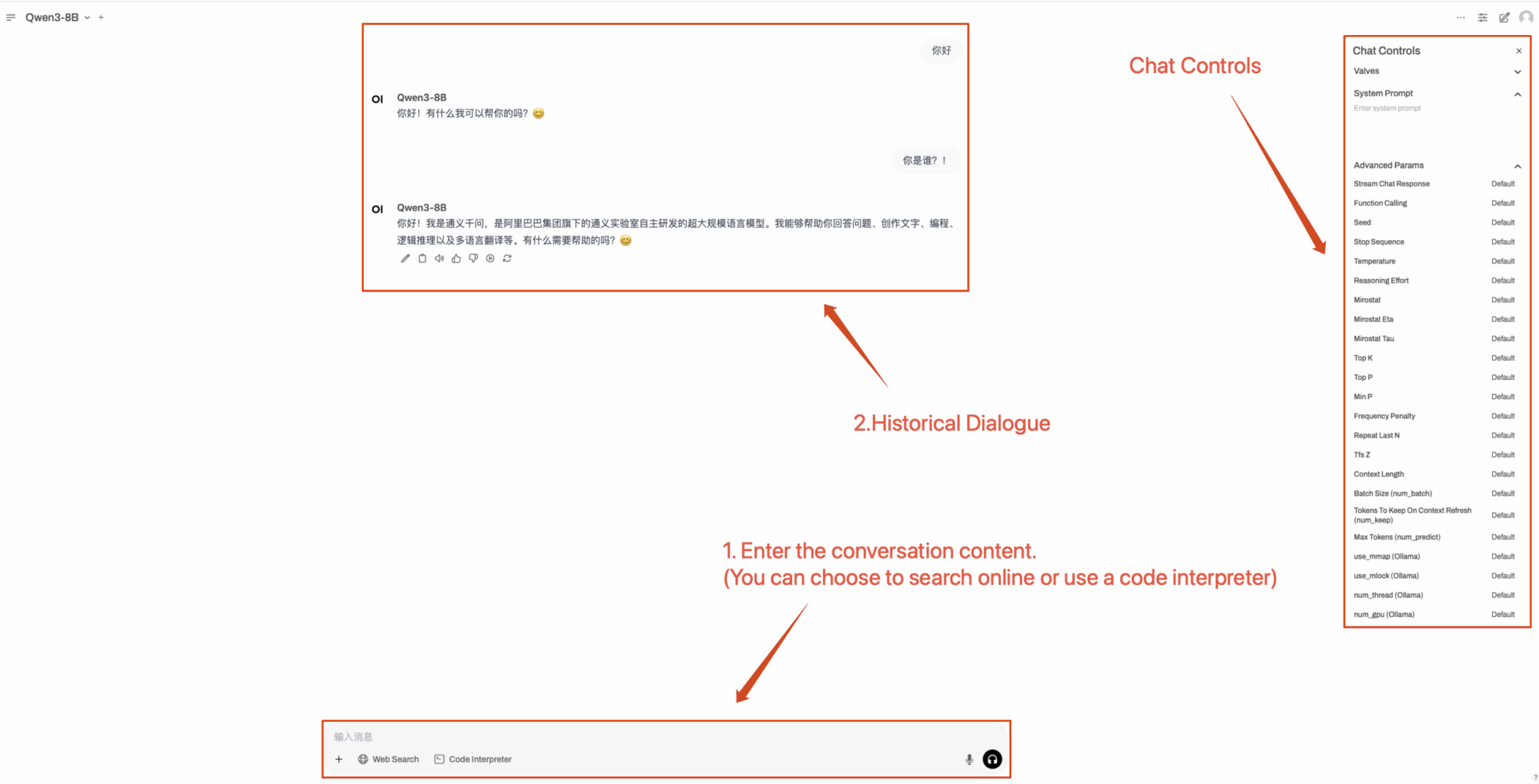
2. After entering the webpage, you can start a conversation with the model
How to use
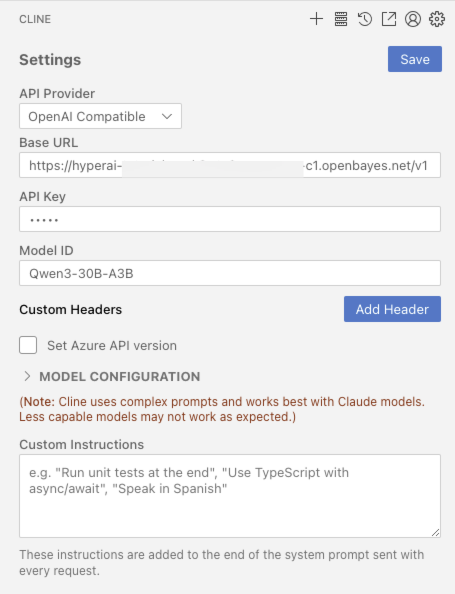
3. OpenAI API Call Guide
The following is an optimized description of the API call method, with a clearer structure and added practical details:
/input0/Qwen3-4B → Replace with your target model path (such as Qwen3-1.7B).
--served-model-name → Change to the corresponding model name (such as Qwen3-1.7B).
Once you're done, your new model is ready to use! 🚀
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
The Qwen3 project was released by Alibaba’s Qwen team in 2025. The relevant technical report is Qwen3: Think Deeper, Act Faster .
Qwen3 is the latest generation of large-scale language models in the Qwen series, providing comprehensive dense models and mixture of experts (MoE) models. Based on rich training experience, Qwen3 has made breakthrough progress in reasoning, instruction following, agent capabilities, and multi-language support. The application scenarios of Qwen3 are very wide. It supports text, image, audio, and video processing, and can meet the needs of multimodal content creation and cross-modal tasks. In enterprise-level applications, Qwen3's agent capabilities and multi-language support enable it to be competent for complex tasks such as medical diagnosis, legal document analysis, and customer service automation. In addition, small models such as Qwen3-0.6B are suitable for deployment on end-side devices such as mobile phones, further expanding its application scenarios.
The latest version Qwen3 has the following features:
Full size dense and mixed expert models: 0.6B, 1.7B, 4B, 8B, 14B, 32B and 30B-A3B, 235B-A22B
Supports seamless switching between thinking mode (for complex logical reasoning, mathematics, and coding) and non-thinking mode (for efficient general conversations), ensuring optimal performance in various scenarios.
Significantly enhanced reasoning capabilities, surpassing the previous QwQ (in thinking mode) and Qwen2.5 instruction model (in non-thinking mode) in mathematics, code generation, and common sense logic reasoning.
Superior alignment with human preferences, excels in creative writing, role-playing, multi-turn conversations, and command following, providing a more natural, engaging, and immersive conversational experience.
Excels in intelligent agent capabilities, can accurately integrate external tools in both thinking and non-thinking modes, and leads in open source models in complex agent-based tasks.
It supports more than 100 languages and dialects, and has powerful multi-language understanding, reasoning, command following and generation capabilities.
2. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. After entering the webpage, you can start a conversation with the model
How to use
3. OpenAI API Call Guide
The following is an optimized description of the API call method, with a clearer structure and added practical details:
/input0/Qwen3-4B → Replace with your target model path (such as Qwen3-1.7B).
--served-model-name → Change to the corresponding model name (such as Qwen3-1.7B).
Once you're done, your new model is ready to use! 🚀
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.