R1-OneVision is a large-scale multimodal reasoning model released by a team from Zhejiang University in February 2025. Based on Qwen2.5-VL and fine-tuned on the R1-OneVision dataset, this model excels at handling complex visual reasoning tasks, seamlessly integrating visual and textual data. It performs exceptionally well in mathematics, science, deep image understanding, and logical reasoning, and can serve as a powerful AI assistant to solve various problems. Related research papers are available. R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization .
This tutorial uses R1-Onevision-7B as a demonstration, and the computing resource uses RTX 4090.
2. Operation steps
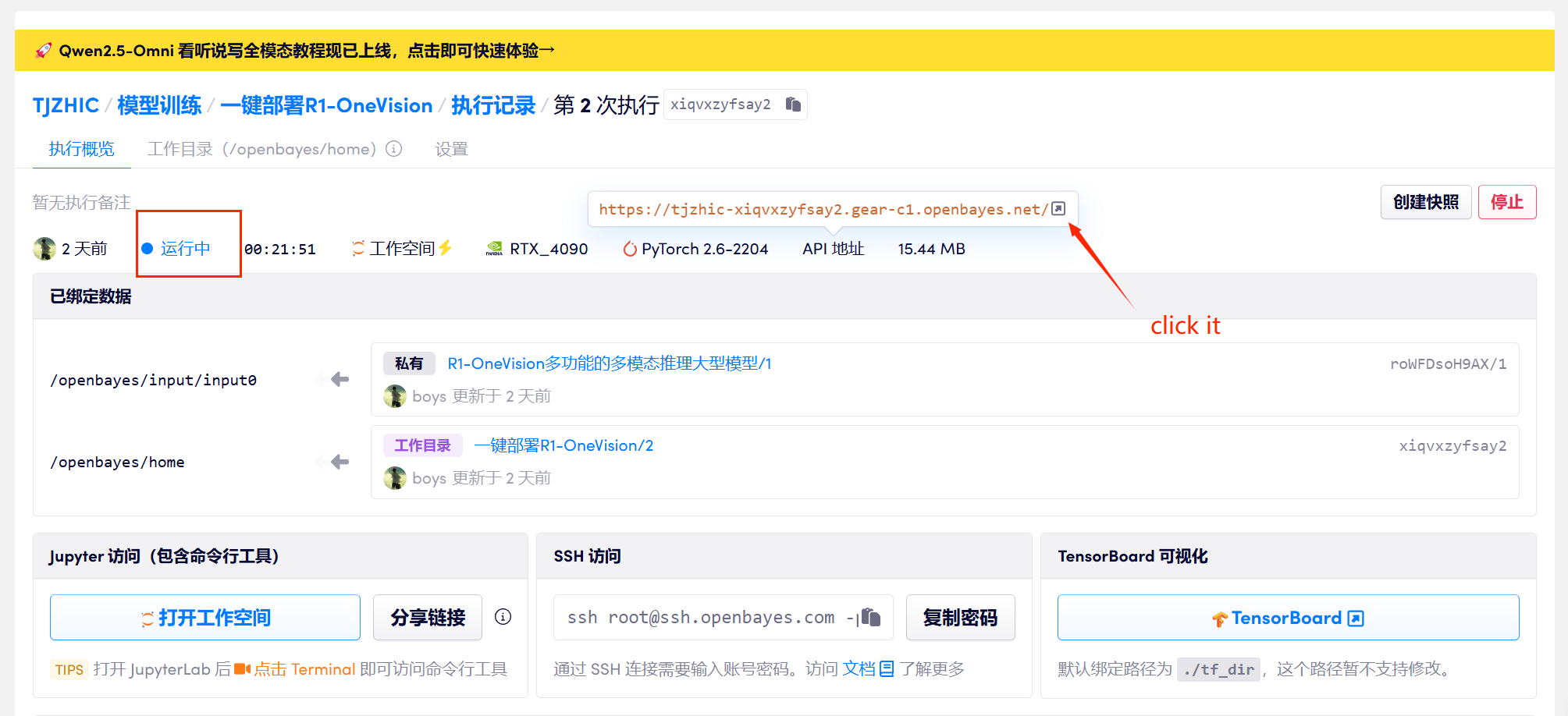
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Please wait for about 1-2 minutes and refresh the page.
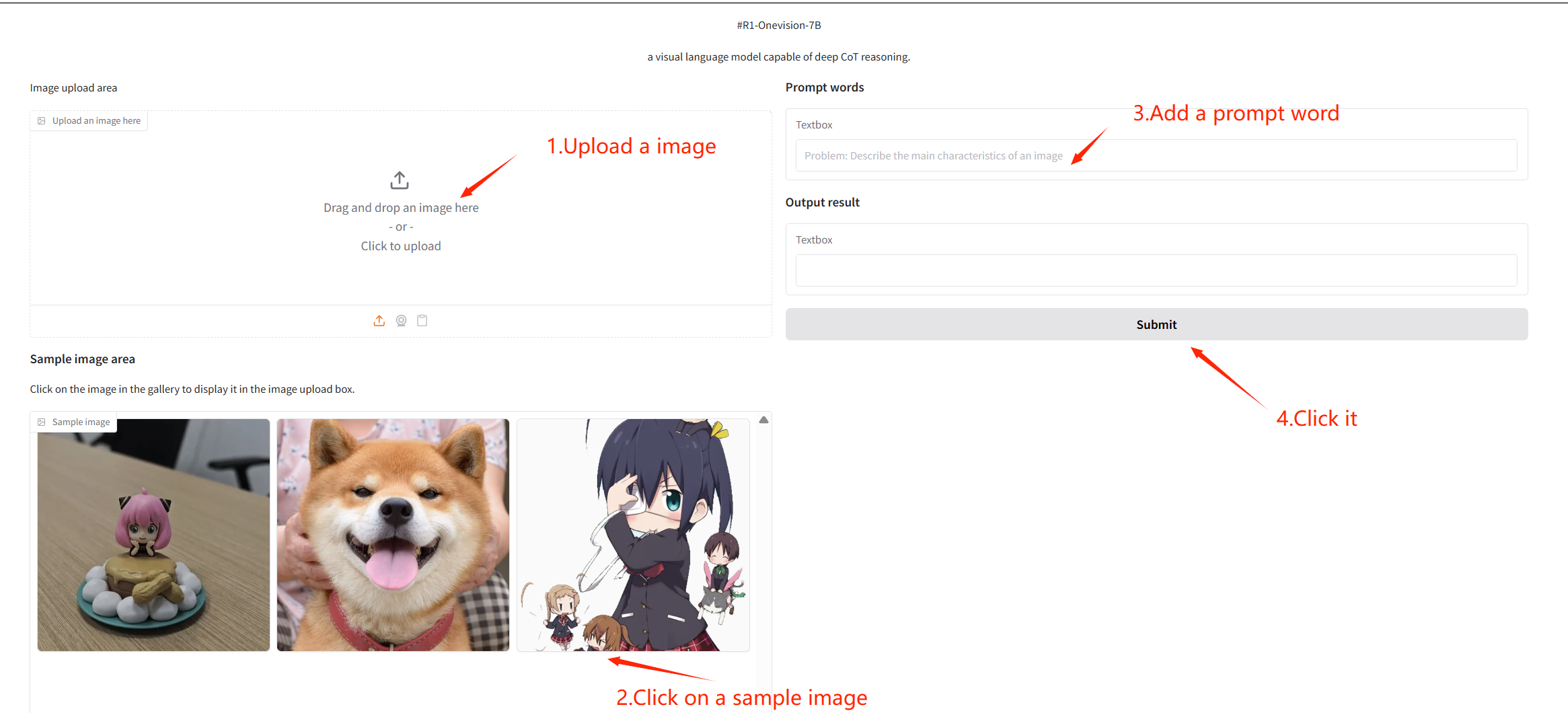
2. Functional Demonstration
Citation Information
Thanks to GitHub user boyswu For the production of this tutorial, the project reference information is as follows:
@article{yang2025r1onevision,
title={R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization},
author={Yi Yang and Xiaoxuan He and Hongkun Pan and Xiyan Jiang and Yan Deng and Xingtao Yang and Haoyu Lu and Dacheng Yin and Fengyun Rao and Minfeng Zhu and Bo Zhang and Wei Chen},
journal={arXiv preprint arXiv:2503.10615},
year={2025},
}
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
R1-OneVision is a large-scale multimodal reasoning model released by a team from Zhejiang University in February 2025. Based on Qwen2.5-VL and fine-tuned on the R1-OneVision dataset, this model excels at handling complex visual reasoning tasks, seamlessly integrating visual and textual data. It performs exceptionally well in mathematics, science, deep image understanding, and logical reasoning, and can serve as a powerful AI assistant to solve various problems. Related research papers are available. R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization .
This tutorial uses R1-Onevision-7B as a demonstration, and the computing resource uses RTX 4090.
2. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Please wait for about 1-2 minutes and refresh the page.
2. Functional Demonstration
Citation Information
Thanks to GitHub user boyswu For the production of this tutorial, the project reference information is as follows:
@article{yang2025r1onevision,
title={R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization},
author={Yi Yang and Xiaoxuan He and Hongkun Pan and Xiyan Jiang and Yan Deng and Xingtao Yang and Haoyu Lu and Dacheng Yin and Fengyun Rao and Minfeng Zhu and Bo Zhang and Wei Chen},
journal={arXiv preprint arXiv:2503.10615},
year={2025},
}
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.