Command Palette
Search for a command to run...
InfiniteYou high-fidelity Image Generation Demo
Date
Size
912.82 MB
License
Apache 2.0
GitHub
1. Tutorial Introduction

InfiniteYou, or InfU for short, is an identity-preserving image generation framework based on Diffusion Transformers (such as FLUX) launched by ByteDance's intelligent creation team in 2025. Through advanced technology, it can maintain the consistency of the person's identity while generating images, solving the shortcomings of existing methods in identity similarity, text-image alignment, and generation quality.
As one of the earliest robust frameworks in the field to utilize Diffused Transformers (DiTs), InfU systematically solves the three core problems of existing methods: insufficient identity similarity, image-text alignment bias, and poor generation quality and aesthetic performance. Its core innovation, InfuseNet, injects identity features into the DiT-based model through residual connections, significantly improving identity fidelity while maintaining generation capabilities. A multi-stage training strategy including pre-training and supervised fine-tuning (SFT) with synthetic single-person multi-sample (SPMS) data is adopted to further optimize image-text alignment, improve generation quality, and effectively alleviate the face duplication effect. A large number of experiments have shown that InfU achieves state-of-the-art performance, surpassing existing baseline methods in all aspects. Its plug-and-play design also ensures compatibility with various existing methods, providing important technical contributions to the academic community.
This tutorial uses InfiniteYou-FLUX v1.0 as a demonstration, and the computing power resource is A6000.
The tutorial provides 2 model versions:
| InfiniteYou Version | Model version | The base model used for training | Features |
|---|---|---|---|
| InfiniteYou-FLUX v1.0 | aes_stage2 | FLUX.1-dev | The second stage model after supervised fine-tuning (SFT) has better image-text alignment and aesthetic performance |
| InfiniteYou-FLUX v1.0 | sim_stage1 | FLUX.1-dev | The first stage model before supervised fine-tuning provides higher identity feature similarity |
Effect examples

2. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 1-2 minutes and refresh the page.
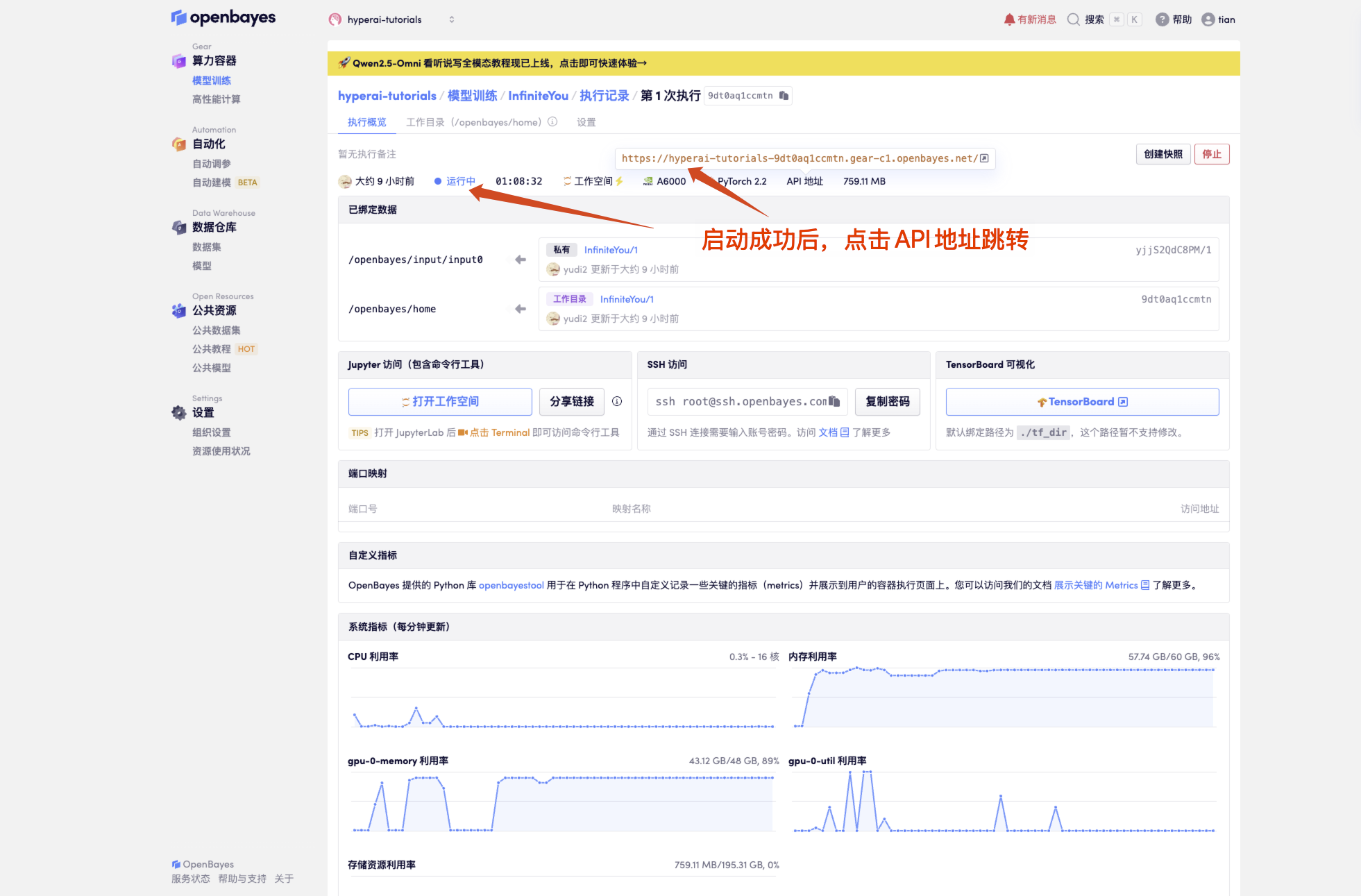
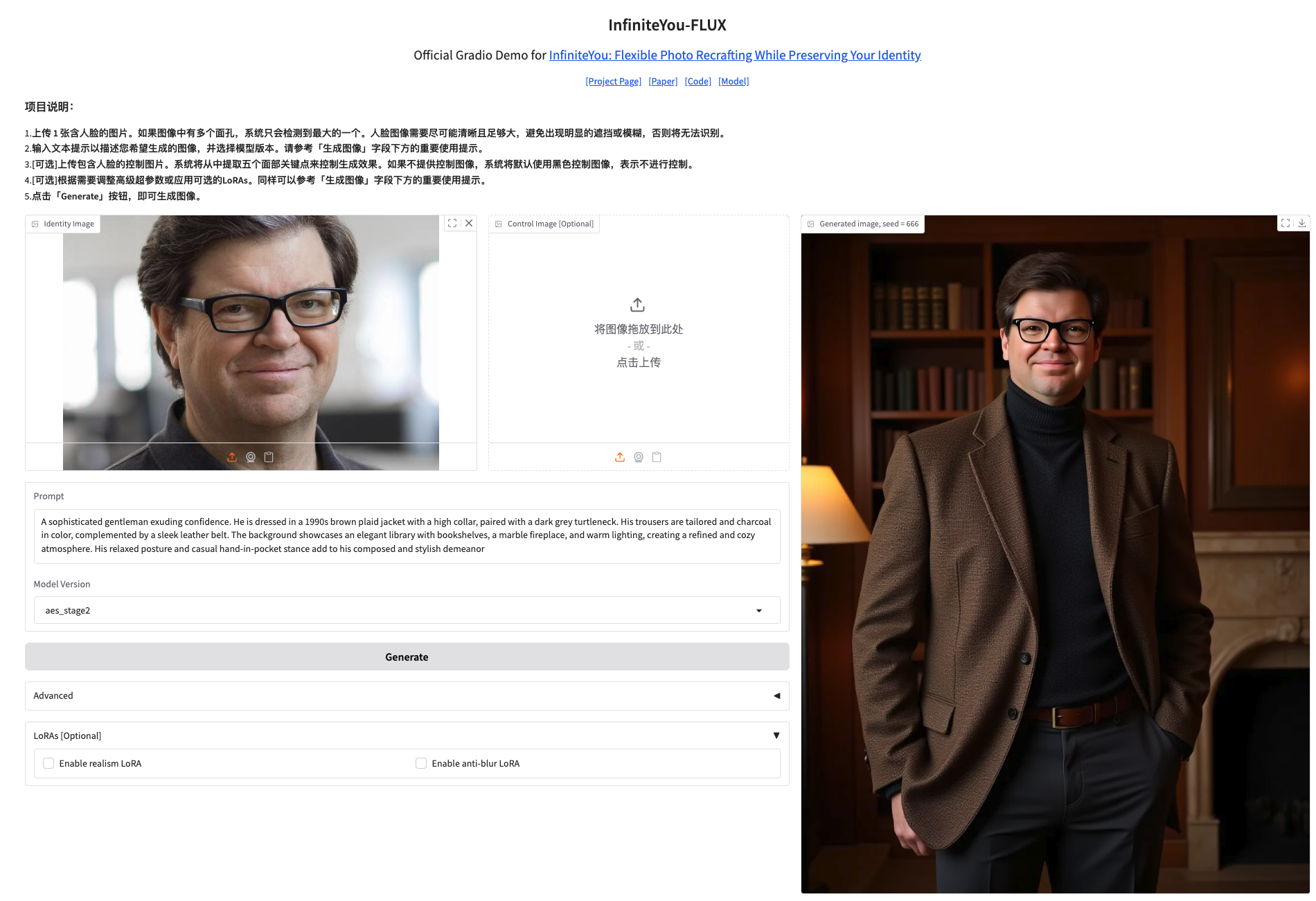
2. Once you enter the website, you can start using
❗️Important usage tips:
- Model version: Use by default
aes_stage2For better alignment and aesthetics. For higher ID similarity, trysim_stage1. - Useful Hyperparameters: Usually no more adjustment is needed. If necessary, try a slightly larger
--infusenet_guidance_start(For example0.1)(rightsim_stage1If the effect is still not satisfactory, try a slightly smaller--infusenet_conditioning_scale(For example0.9). - Optional LoRA:
realism(realistic) andanti-blur(Anti-blur). Check the corresponding box to enable. These are optional features and were not used in the paper. - Gender Tips: If the generated gender does not meet your expectations, please add specific words in the text prompt, such as "a man", "a woman", etc. This project encourages the use of inclusive and respectful language.
How to use

Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.