Command Palette
Search for a command to run...
Qwen2.5-Omni Opens up All Modes of Reading, Listening, Speaking and Writing
1. Tutorial Introduction
Qwen2.5-Omni is the latest end-to-end multimodal flagship model released by Alibaba Tongyi Qianwen team on March 27, 2025. It is designed for comprehensive multimodal perception and seamlessly processes various inputs including text, images, audio and video, while supporting streaming text generation and natural speech synthesis output.
Main Features
- All-round innovative architecture:A new Thinker-Talker architecture is adopted, which is an end-to-end multimodal model designed to support cross-modal understanding of text/image/audio/video, while generating text and natural speech responses in a streaming manner. The research team proposed a new position encoding technology called TMRoPE (Time-aligned Multimodal RoPE), which achieves precise synchronization of video and audio inputs through time axis alignment.
- Real-time audio and video interaction: The architecture is designed to support full real-time interaction, supporting chunked input and immediate output.
- Natural and fluent speech generation: Surpasses many existing streaming and non-streaming alternatives in terms of naturalness and stability of speech generation.
- Omni-modal performance advantage: Demonstrated superior performance when benchmarked against similarly sized unimodal models. The Qwen2.5-Omni outperformed the similarly sized Qwen2-Audio in audio capabilities and was on par with the Qwen2.5-VL-7B.
- Excellent end-to-end voice command following capability: Qwen2.5-Omni shows comparable results to text input processing in end-to-end voice command following, and excels in benchmarks such as MMLU general knowledge understanding and GSM8K mathematical reasoning.
This tutorial uses Qwen2.5-Omni as a demonstration, and the computing resources are A6000.
Support functions:
- Online multimodal dialogue
- Offline multimodal conversation
2. Operation steps
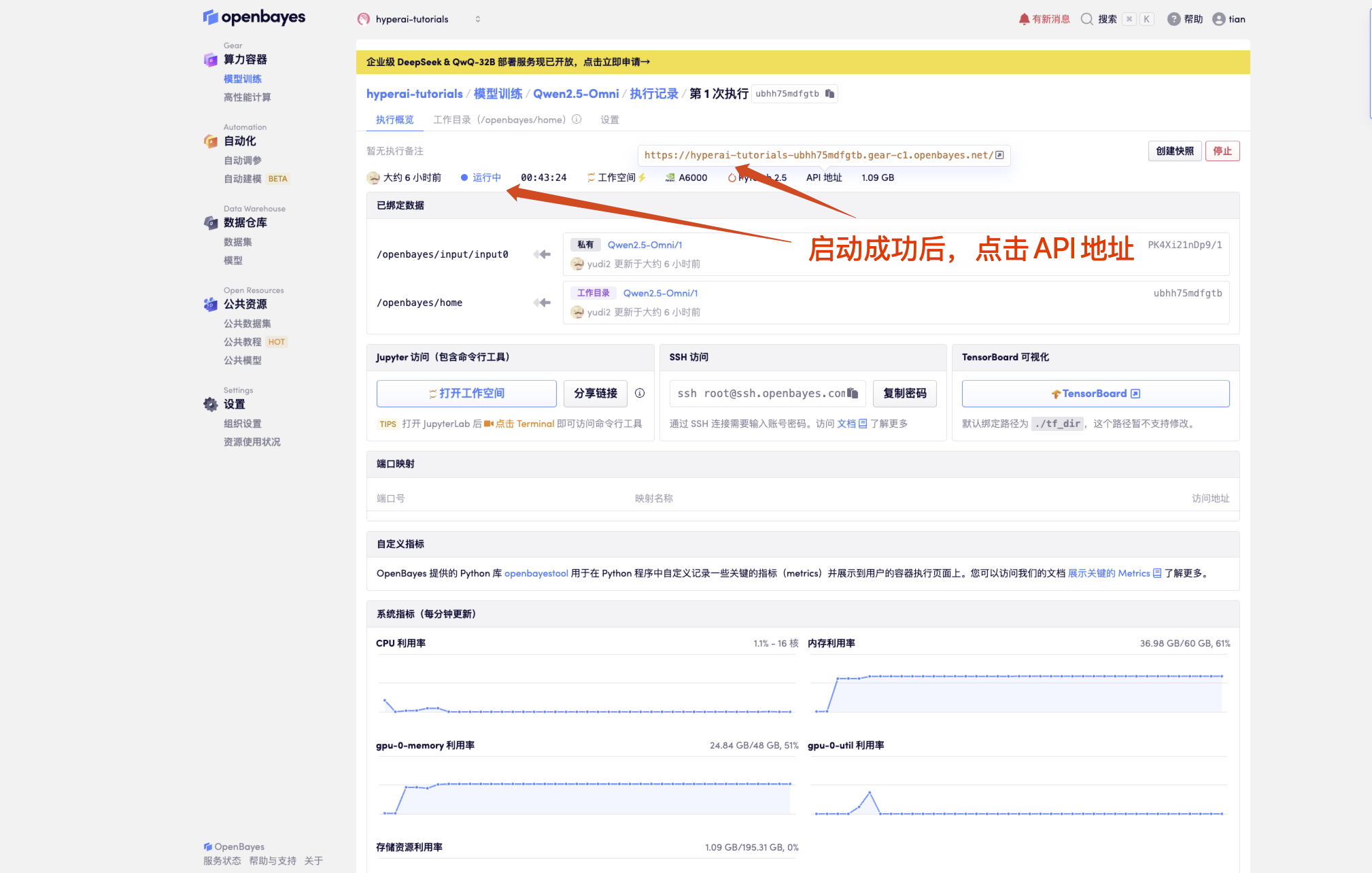
1. After starting the container, click the API address to enter the Web interface
If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. After entering the webpage, you can start a conversation with the model
When the input box is orange it means the model is responding.
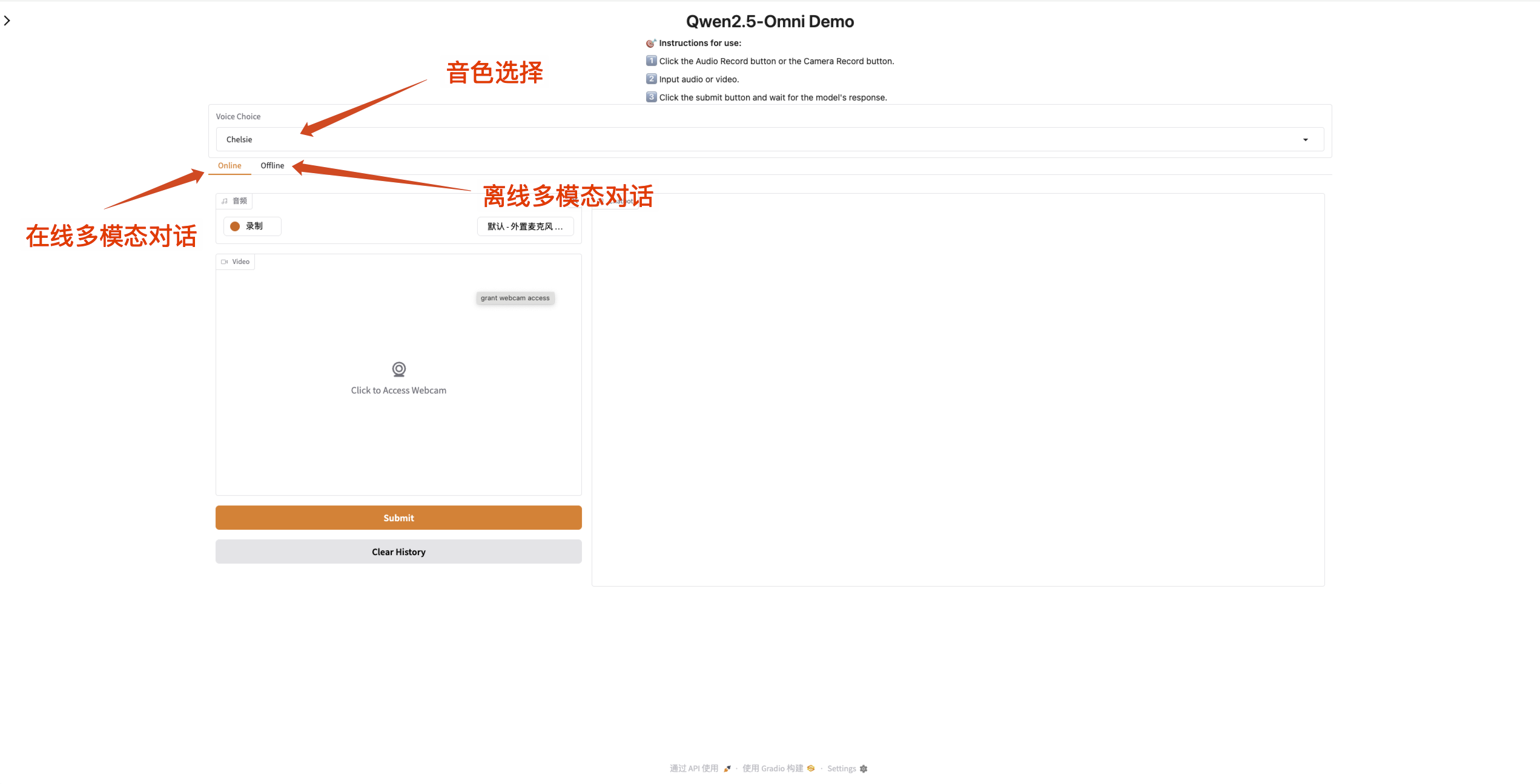
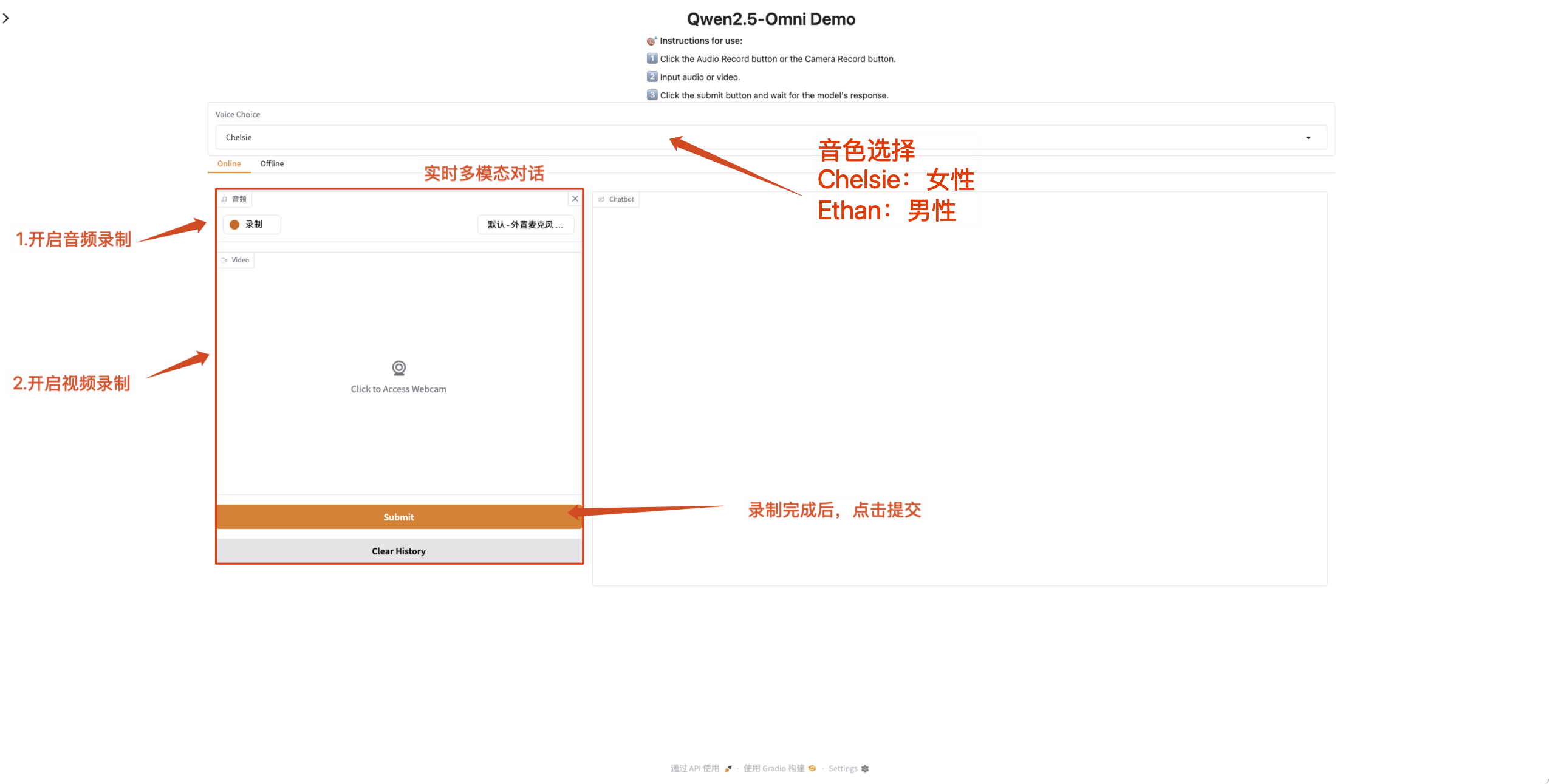
Qwen2.5-Omni supports changing the sound of the output audio. The "Qwen/Qwen2.5-Omni-7B" checkpoint supports the following two sound types:
| Tone Type | gender | describe |
|---|---|---|
| Chelsie | female | Sweet, gentle, bright, soft |
| Ethan | male | Sunshine, vitality, lightness, affinity |
- Online multimodal dialogue
Enable the microphone and camera permissions on the web page so that you can have real-time conversations with Qwen2.5-Omni after recording is completed.
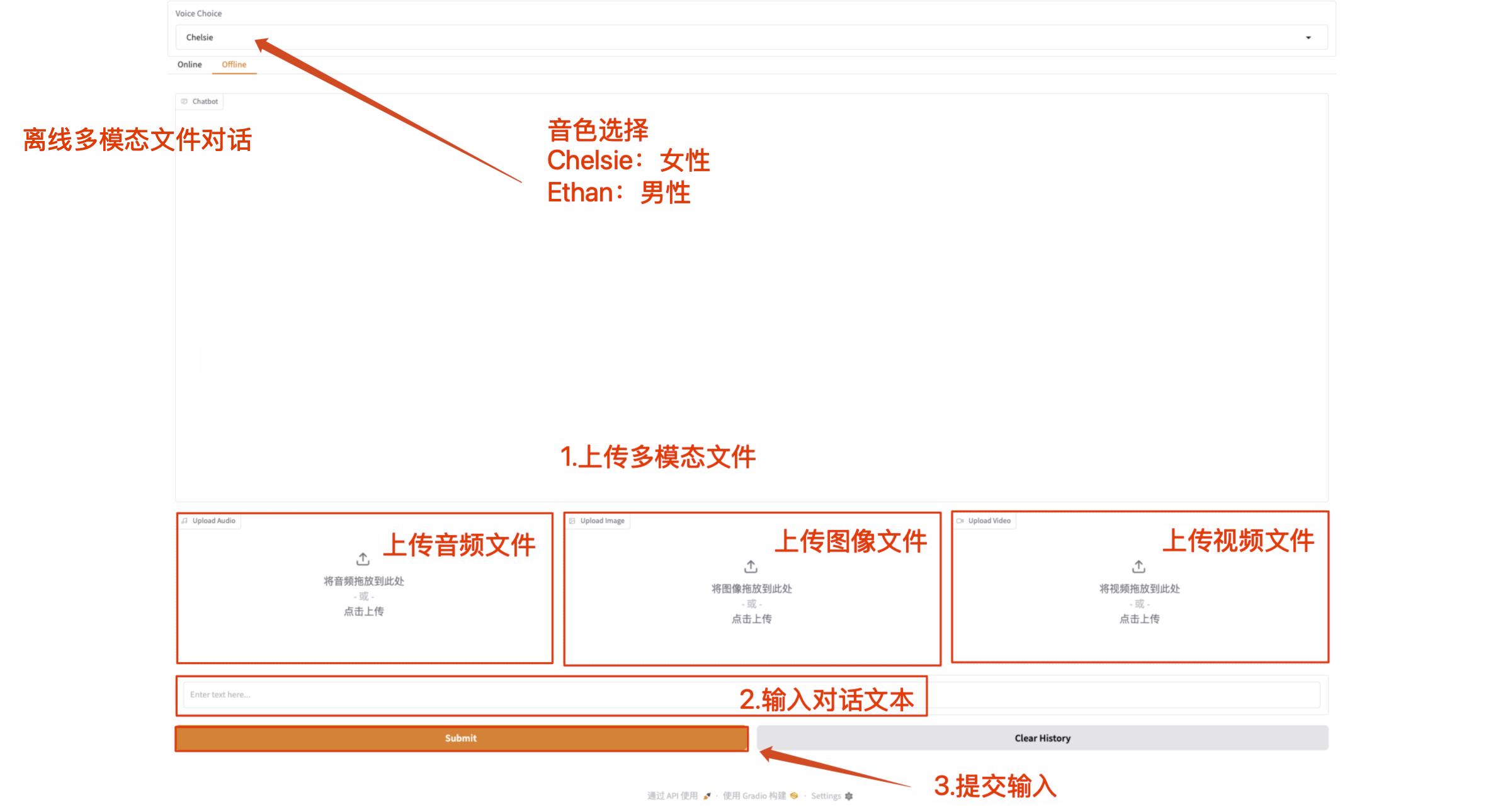
- Offline multimodal conversation
Directly upload multimodal files and communicate with Qwen2.5-Omni with text content.
Note: The video file must have sound. If there is no sound, an error message will be displayed.
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓ 
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.