Command Palette
Search for a command to run...
DiffRhythm: Generate a Complete Music Demo in 1 Minute
One-click deployment of DiffRhythm-full

1. Tutorial Introduction
DiffRhythm is an end-to-end music generation tool based on the latent diffusion model, jointly developed by the Audio Speech and Language Processing Laboratory of Northwestern Polytechnical University (ASLP@NPU) and the Chinese University of Hong Kong, Shenzhen. It can generate a complete song of up to 4 minutes and 45 seconds in a short time, including vocals and accompaniment. Users only need to provide lyrics and style hints, and DiffRhythm can automatically generate melodies and accompaniment that match the lyrics, supporting multi-language input.
DiffRhythm (Chinese: 狄韵, Dì Yùn) is the first diffusion-based song generation model capable of creating complete songs. The name combines "Diff" (referring to its diffusion architecture) and "Rhythm" (emphasizing its focus on music and songwriting). The Chinese name 狄韵 (Dì Yùn) is similar in pronunciation to "DiffRhythm", with "狄" (listening attentively) symbolizing auditory perception and "韵" (melodic charm) representing musicality.
2. Operation steps
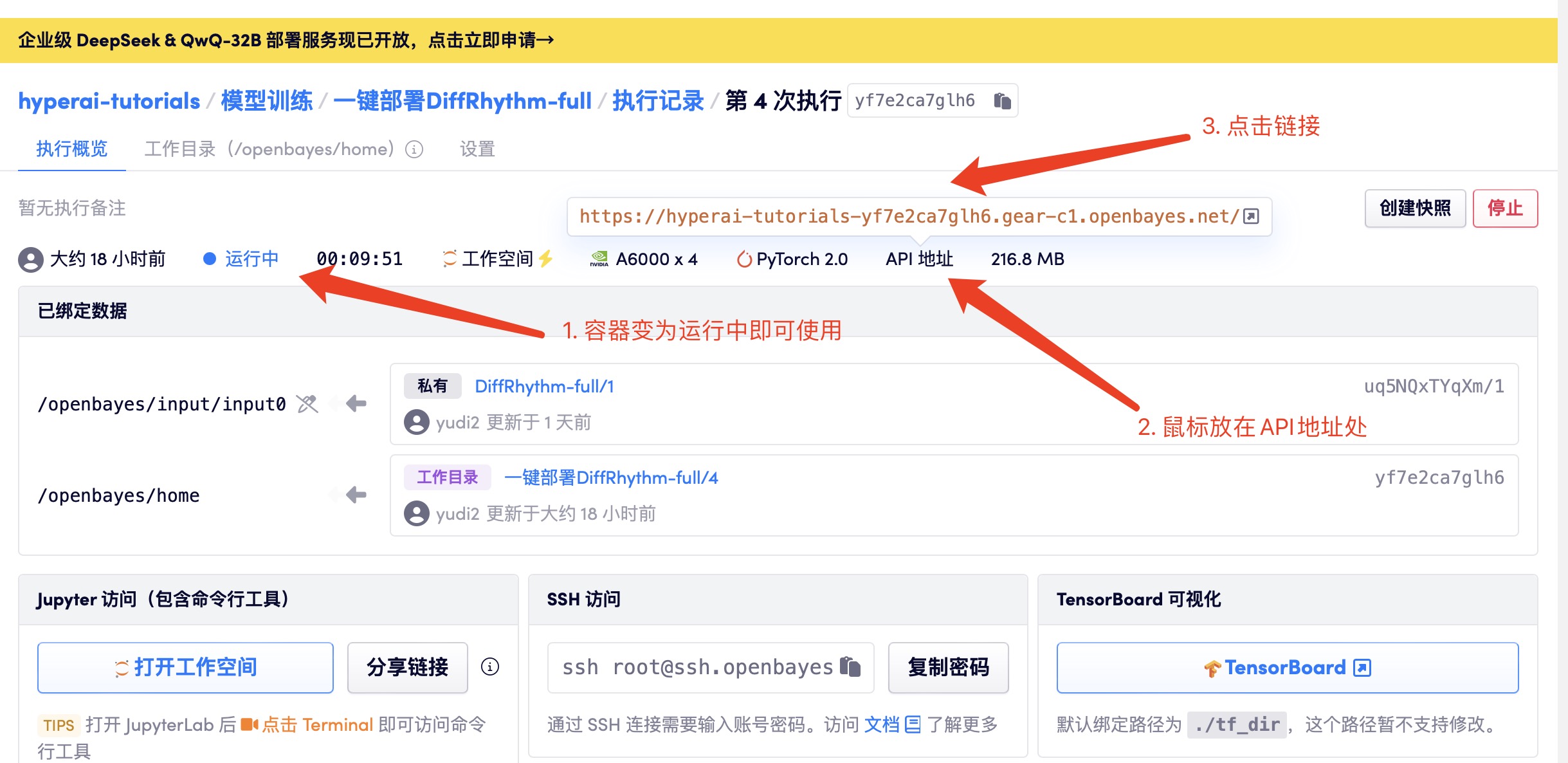
1. Start the container
After starting the container, click the API address to enter the Web interface. Due to the large model, it takes about 3 minutes to display the WebUI interface, otherwise it will display "Bad Gateway"
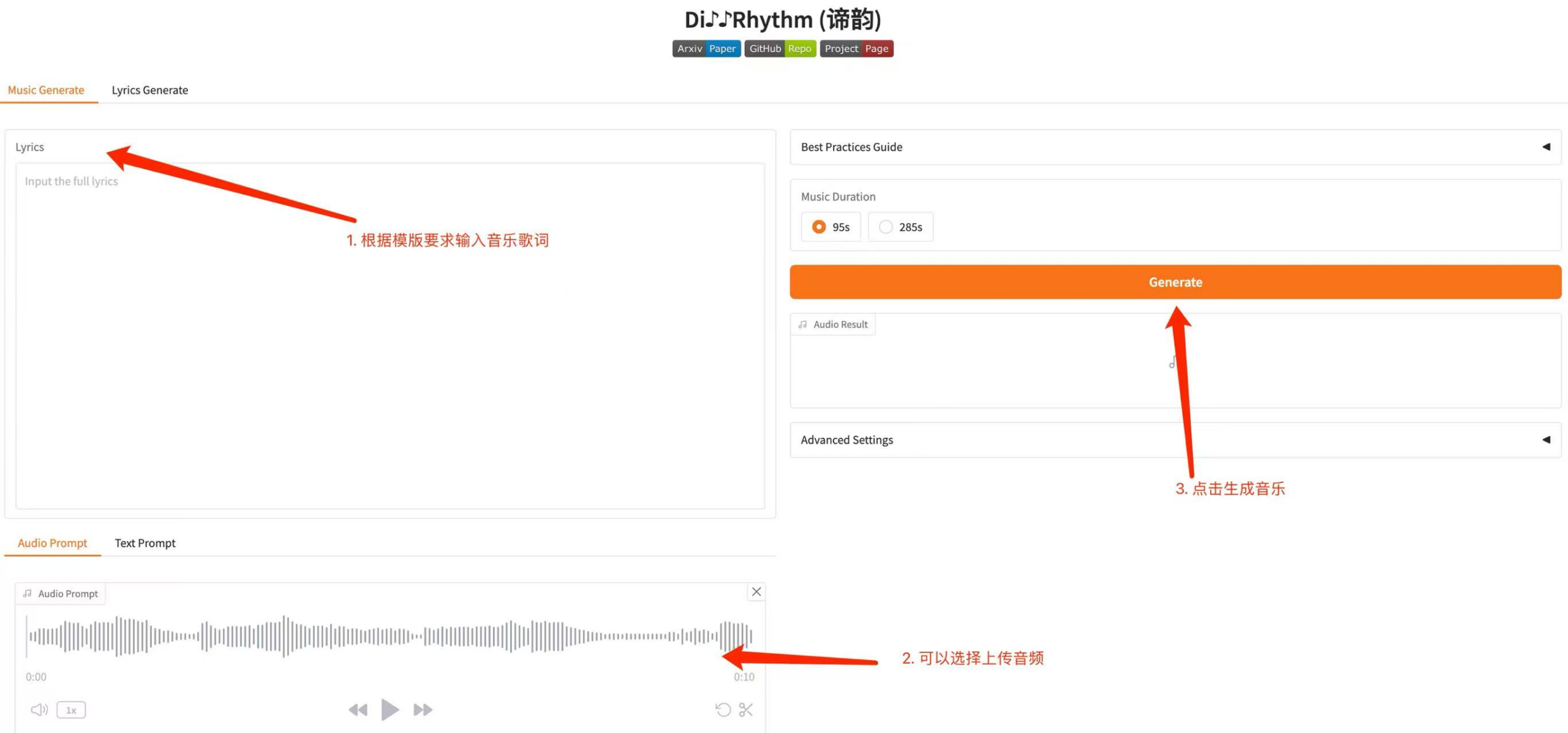
2. Music Generation
2.1 Choose to generate music based on lyrics or audio
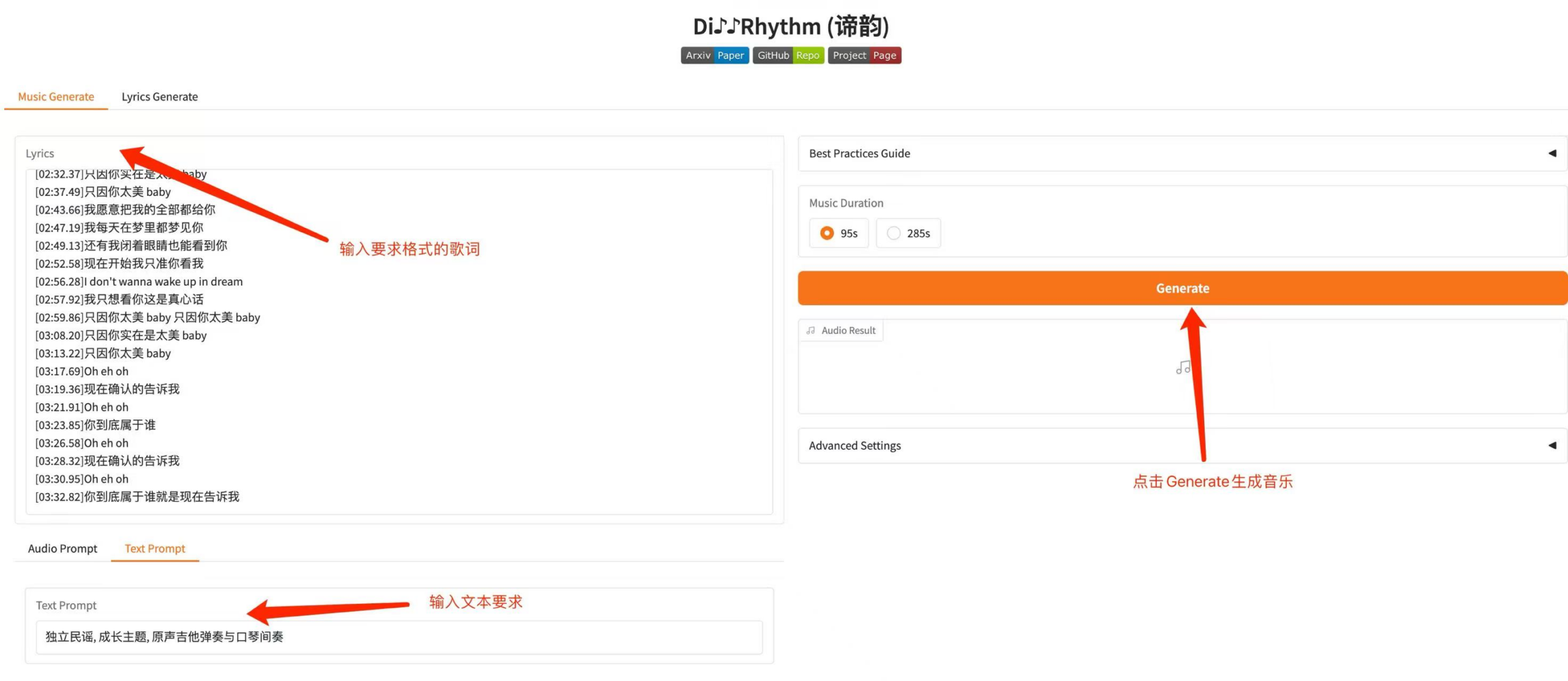
2.2 You can choose to generate music based on lyrics or text
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.