Command Palette
Search for a command to run...
Deploying DeepSeek R1 With Ollama and Open WebUI
1. Tutorial Introduction
DeepSeek-R1 is the first version of the language model series launched by DeepSeek in 2025, focusing on efficient and lightweight natural language processing tasks. This series of models is optimized through advanced technologies such as knowledge distillation, aiming to reduce computing resource requirements while maintaining high performance. The design of DeepSeek-R1 focuses on practical application scenarios, supports rapid deployment and integration, and is suitable for a variety of tasks, including text generation, dialogue systems, translation, and summary generation.
On the technical level, DeepSeek-R1 uses knowledge distillation technology to extract knowledge from large models to train smaller models with similar performance. At the same time, efficient distributed training and optimization algorithms further shorten training time and improve model development efficiency. These technical highlights make DeepSeek-R1 perform well in practical applications.
本教程预设 DeepSeek-R1-Distill-Qwen-1.5B 、 DeepSeek-R1-Distill-Qwen-7B 、 DeepSeek-R1-Distill-Qwen-8B 、 DeepSeek-R1-Distill-Qwen-32B 四种模型作为演示,算力资源采用「单卡 RTX4090」。
2. Operation steps
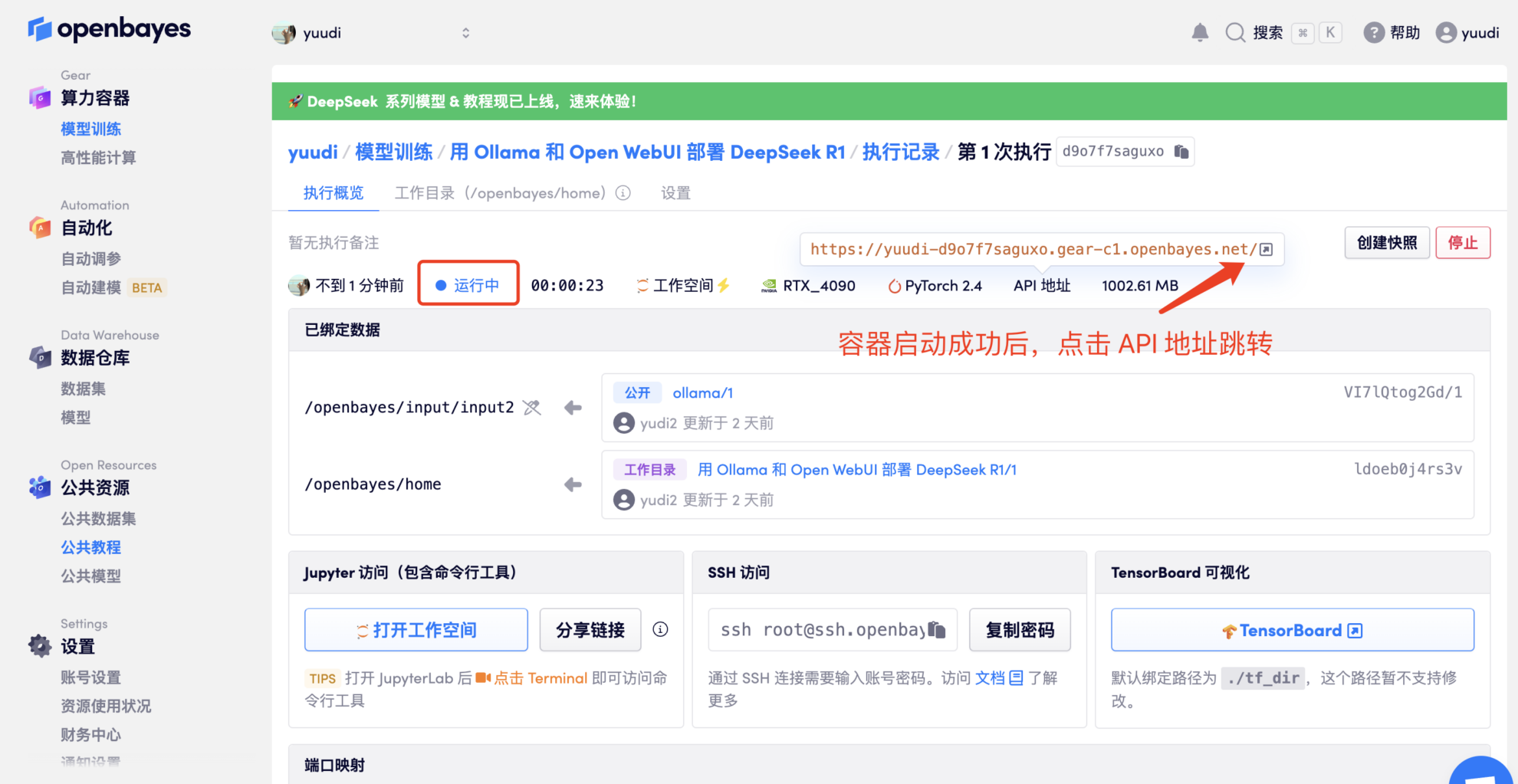
- After cloning and starting the container, click the API address to enter the web interface (if "Bad Gateway" is displayed, it means that the model is initializing. Since the model is large, please wait about 5 minutes and try again.)
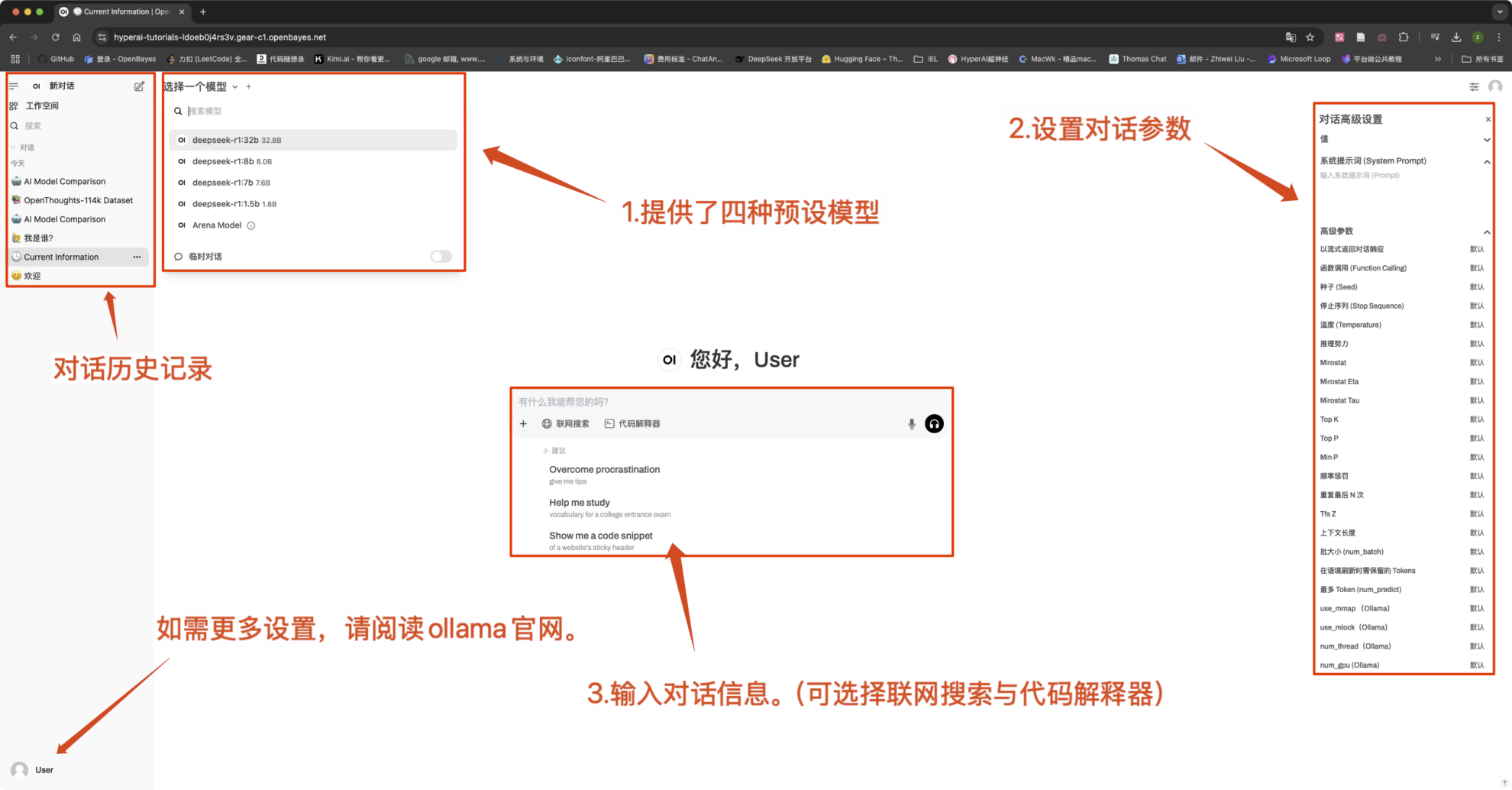
2. After entering the webpage, you can start a conversation with the model
Notice:
- This tutorial supports "online search". After this function is turned on, the reasoning speed will slow down, which is normal.
- You can switch models in the upper left corner of the interface.
Common conversation settings
1. Temperature
- Controls the randomness of the output, generally in the range of 0.0-2.0 between.
- Low value (such as 0.1): More certain, biased towards common words.
- High value (such as 1.5): More random, potentially more creative but erratic content.
2. Top-k Sampling
- Only from The k with the highest probability Sampling in words, excluding low-probability words.
- k is small (e.g. 10): More certainty, less randomness.
- k is large (e.g. 50): More diversity, more innovation.
3. Top-p Sampling (Nucleus Sampling, Top-p Sampling)
- chooseThe word set with cumulative probability reaching p, the k value is not fixed.
- Low value (such as 0.3): More certainty, less randomness.
- High value (such as 0.9): More diversity, improved fluency.
4. Repetition Penalty
- Controls text repetition, usually in 1.0-2.0 between.
- High value (such as 1.5): Reduce repetition and improve readability.
- Low value (such as 1.0): No penalty, may cause the model to repeat words and sentences.
5. Max Tokens (maximum generation length)
- Restriction ModelMaximum number of tokens generated, to avoid excessively long output.
- Typical range:50-4096(Depends on the specific model).
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.