Command Palette
Search for a command to run...
Ebook2Audiobook eBook to Audiobook

1. Tutorial Introduction
Ebook2Audiobook is a tool that was open sourced in 2024 and is designed to convert eBooks into audiobooks. The project uses advanced text-to-speech (TTS) technology to automatically convert the text content in eBooks into speech, generating audiobooks that users can listen to. Ebook2Audiobook supports multiple eBook formats, such as EPUB, PDF, MOBI, etc., and can retain chapter structure and metadata, making the generated audiobooks easier to navigate and understand.
Project Features:
- 📖 Convert eBooks to text format using Calibre.
- 📚Split eBooks into chapters to organize audio.
- 🎙️High-quality text-to-speech using Coqui XTTSv2 and Fairseq.
- 🗣️Optional voice cloning, use your own voice files.
- 🌍Supports 1107 languages (English by default)
New v2.0 Web GUI interface effects

2. Operation steps
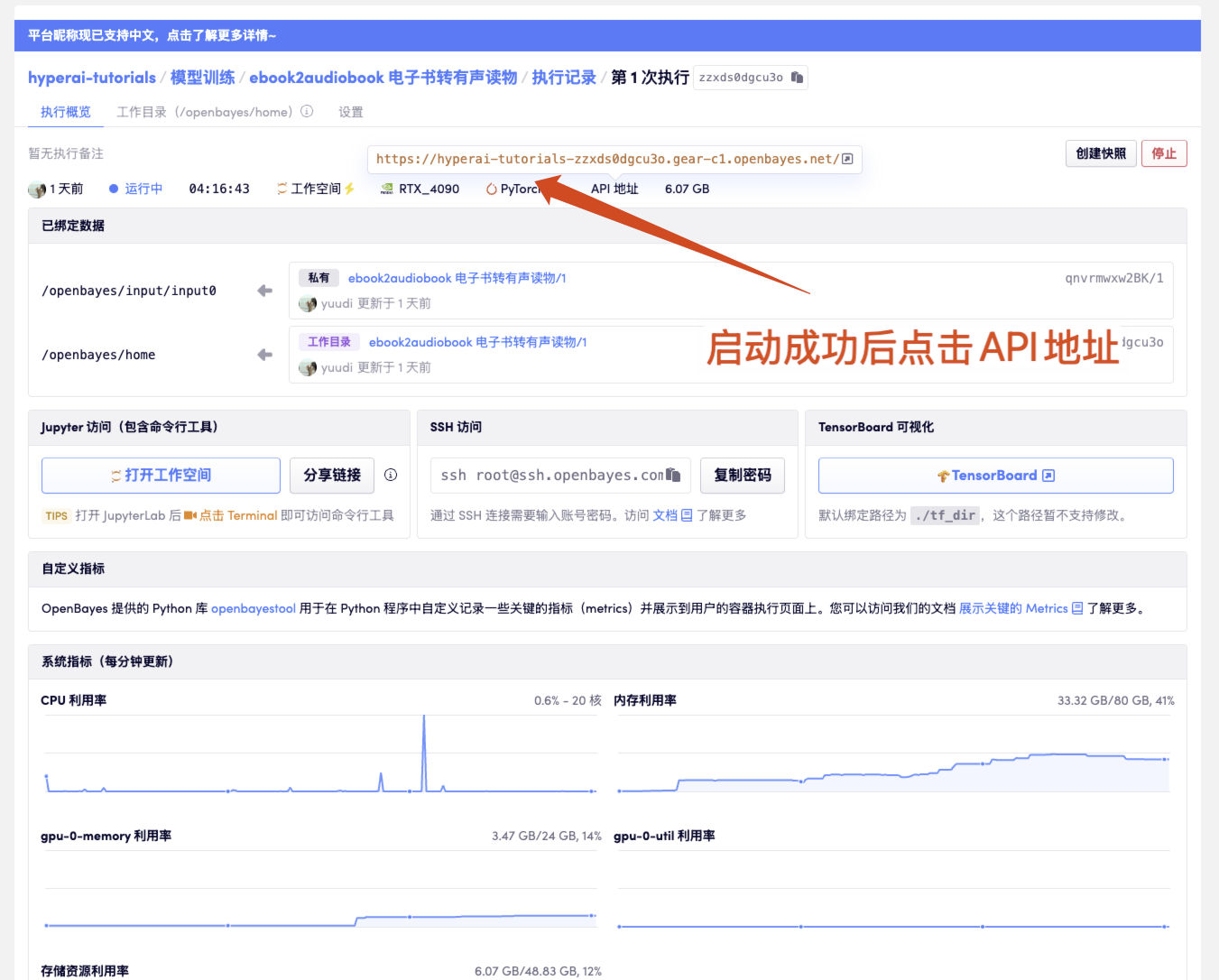
1. Start the container
Then click the API address to enter the Web interface
2. Process Demonstration
Please note:
- This project has a "model loading process", which takes about 3-4 minutes;
- After the progress bar is generated, if the online audio cannot be displayed, please refresh the webpage or download it to your local computer for viewing;
- When using a txt file, only the first line will be read;
- Be sure to note that the language of the e-book must be consistent with the selected language, otherwise a "non-human language" will be generated;
- In this project, Fine Tuned Models only caches the std model.
Required:
- E-book document
- Select language

Figure 1 Main process
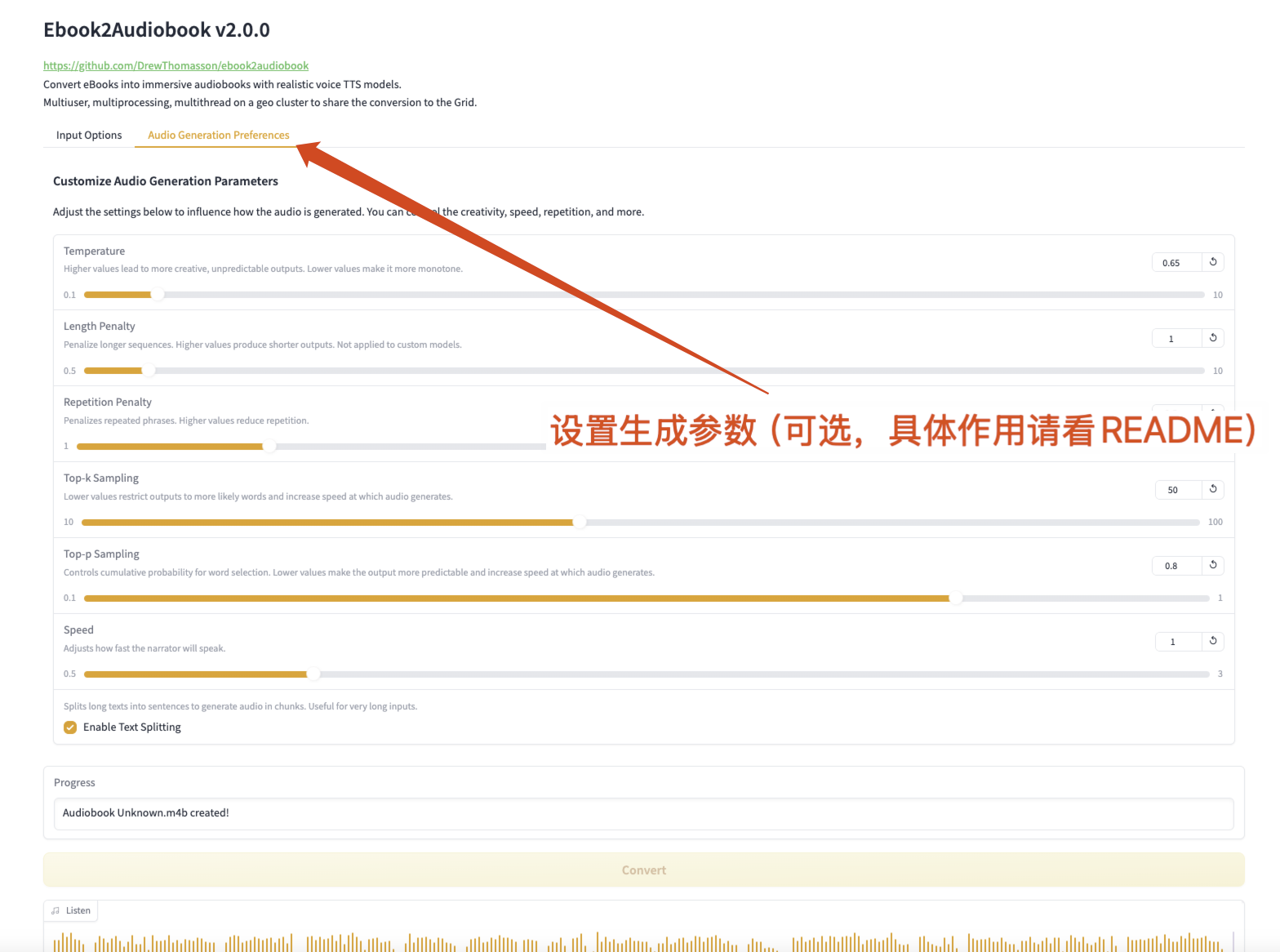
Figure 2 Generating parameter parameters
Generate Parameters
- Temperature: 0.65
- Higher values produce more creative and unpredictable output, lower values make the output more monotonous.
- Length Penalty: Penalize longer sequences
- Higher values produce shorter output (not suitable for custom models).
- Repetition Penalty: Penalize repeated phrases
- Higher values reduce repetition.
- Top-k Sampling: Lower values constrain the output to more likely words, speeding up audio generation.
- Top-p Sampling: Control the cumulative probability of word selection
- Lower values make the output more predictable and generate audio faster.
- Narrator Speed: Adjust the narrator's speaking speed.
- Text Splitting: Split long text into sentences to generate audio in chunks.
- Good for very long inputs.
- Enable Text Splitting: Enable text splitting.
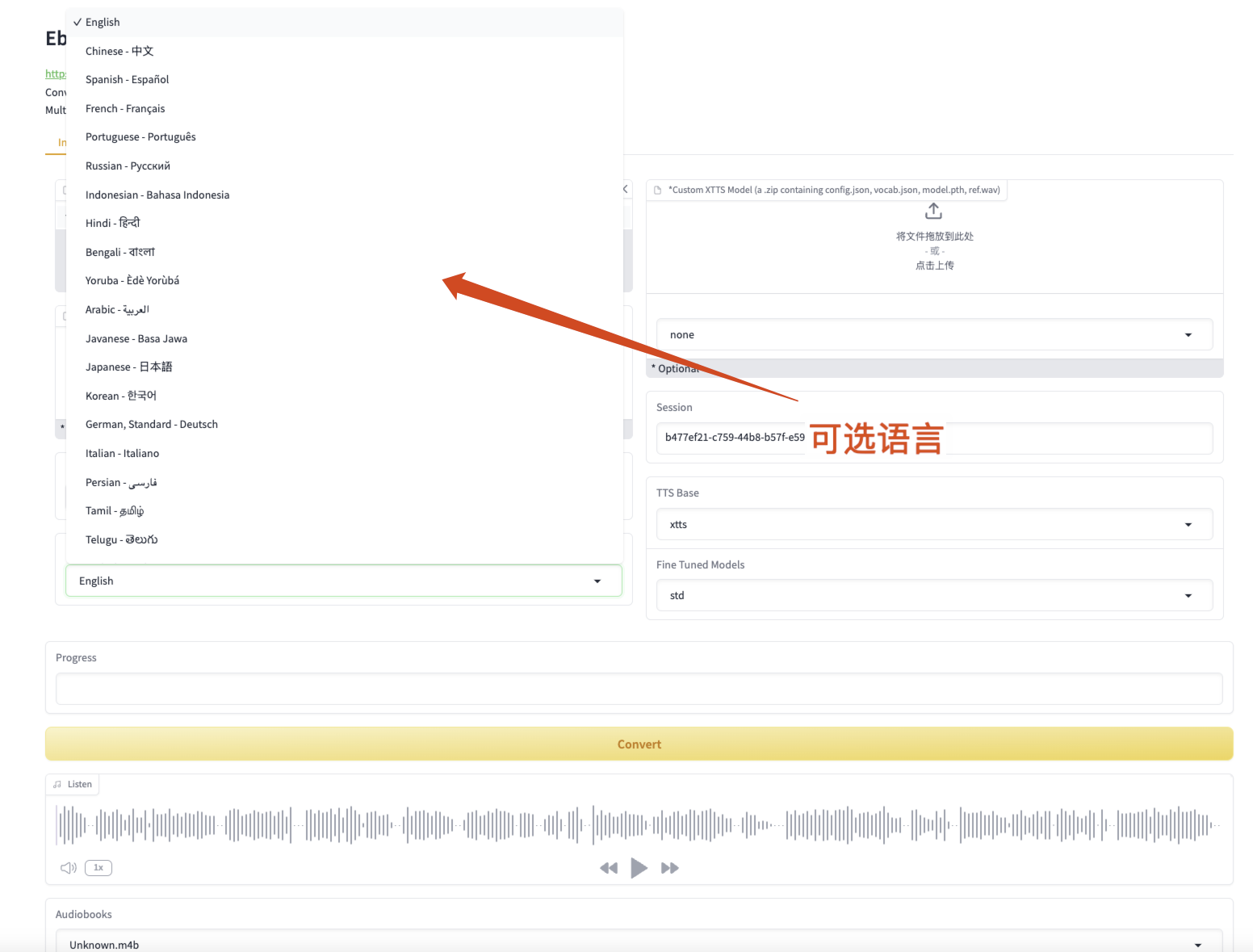
Figure 3 Selectable languages
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.