Command Palette
Search for a command to run...
GLM-4-Voice End-to-end Chinese-English Conversation Model
Date
Size
1.91 GB
1. Tutorial Introduction
GLM-4-Voice is an end-to-end voice model launched by Zhipu AI in 2024. GLM-4-Voice can directly understand and generate Chinese and English voices, conduct real-time voice conversations, and can follow the user's instructions to change the voice's emotion, intonation, speaking speed, dialect and other attributes.
This tutorial demo contains two functional implementations of the model: "Voice Conversation" and "Text Conversation".
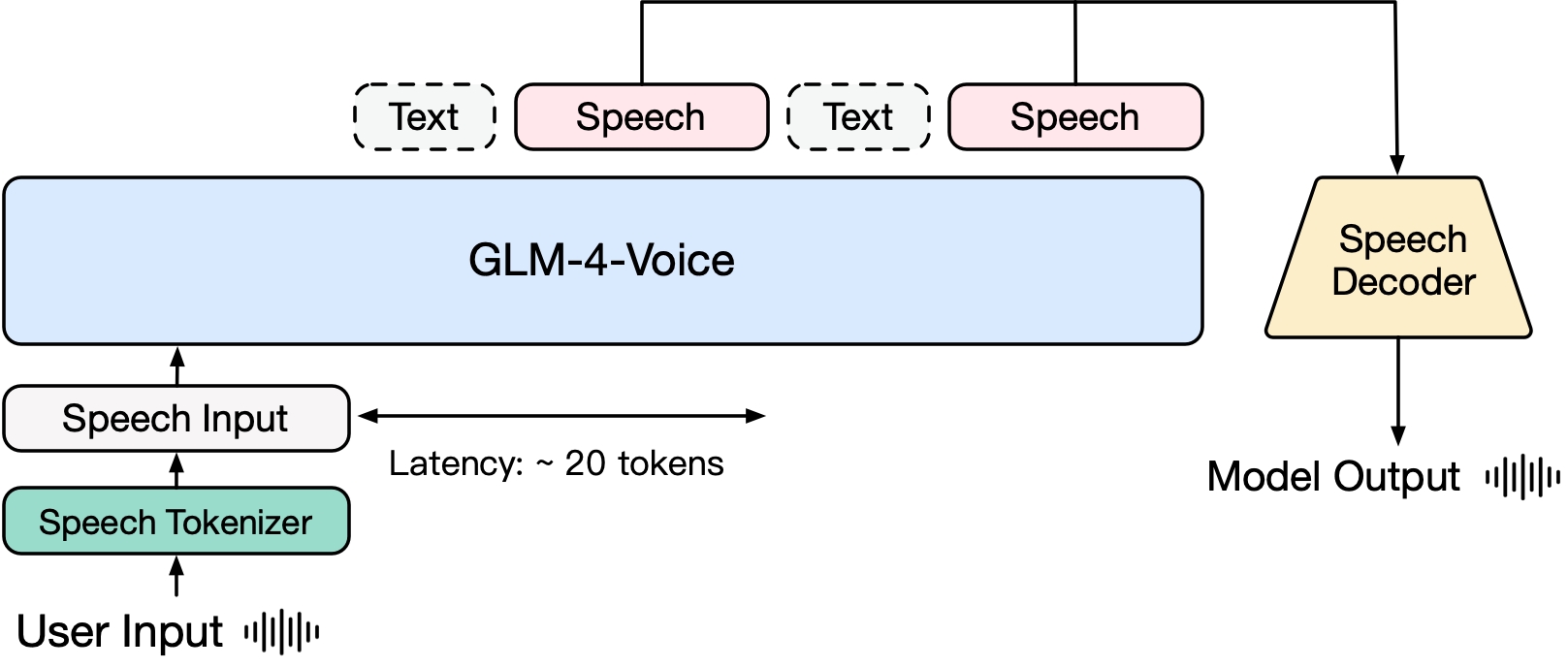
GLM-4-Voice consists of three parts:
- GLM-4-Voice-Tokenizer: By adding Vector Quantization to the Encoder part of Whisper and supervised training on ASR data, continuous speech input is converted into discrete tokens. On average, only 12.5 discrete tokens are needed per second of audio.
- GLM-4-Voice-Decoder: A voice decoder that supports streaming inference and is trained based on the Flow Matching model structure of CosyVoice. It converts discrete voice tokens into continuous voice output. Only 10 voice tokens are needed to start generating, reducing end-to-end conversation latency.
- GLM-4-Voice-9B: Pre-trains and aligns the speech modality based on GLM-4-9B, so that it can understand and generate discrete speech tokens.
In terms of pre-training, in order to overcome the two difficulties of the model's IQ and synthesis expression in the voice mode, the research team decoupled the Speech2Speech task into two tasks: "making text replies based on user audio" and "synthesizing reply voice based on text replies and user voice", and designed two pre-training goals, synthesizing speech-text interleaved data based on text pre-training data and unsupervised audio data to adapt to these two task forms. GLM-4-Voice-9B is based on the base model of GLM-4-9B and has been pre-trained on millions of hours of audio and hundreds of billions of tokens of audio-text interleaved data, and has strong audio understanding and modeling capabilities.
In terms of alignment, in order to support high-quality voice conversations, the research team designed a streaming thinking architecture: based on the user's voice, GLM-4-Voice can stream and output the content of both text and voice modes alternately. The voice mode uses text as a reference to ensure the high quality of the reply content, and makes corresponding sound changes according to the user's voice command requirements. It still has the ability of end-to-end modeling while retaining the IQ of the language model to the greatest extent, and has low latency. It only needs to output 20 tokens at a minimum to synthesize speech.
2. Operation steps
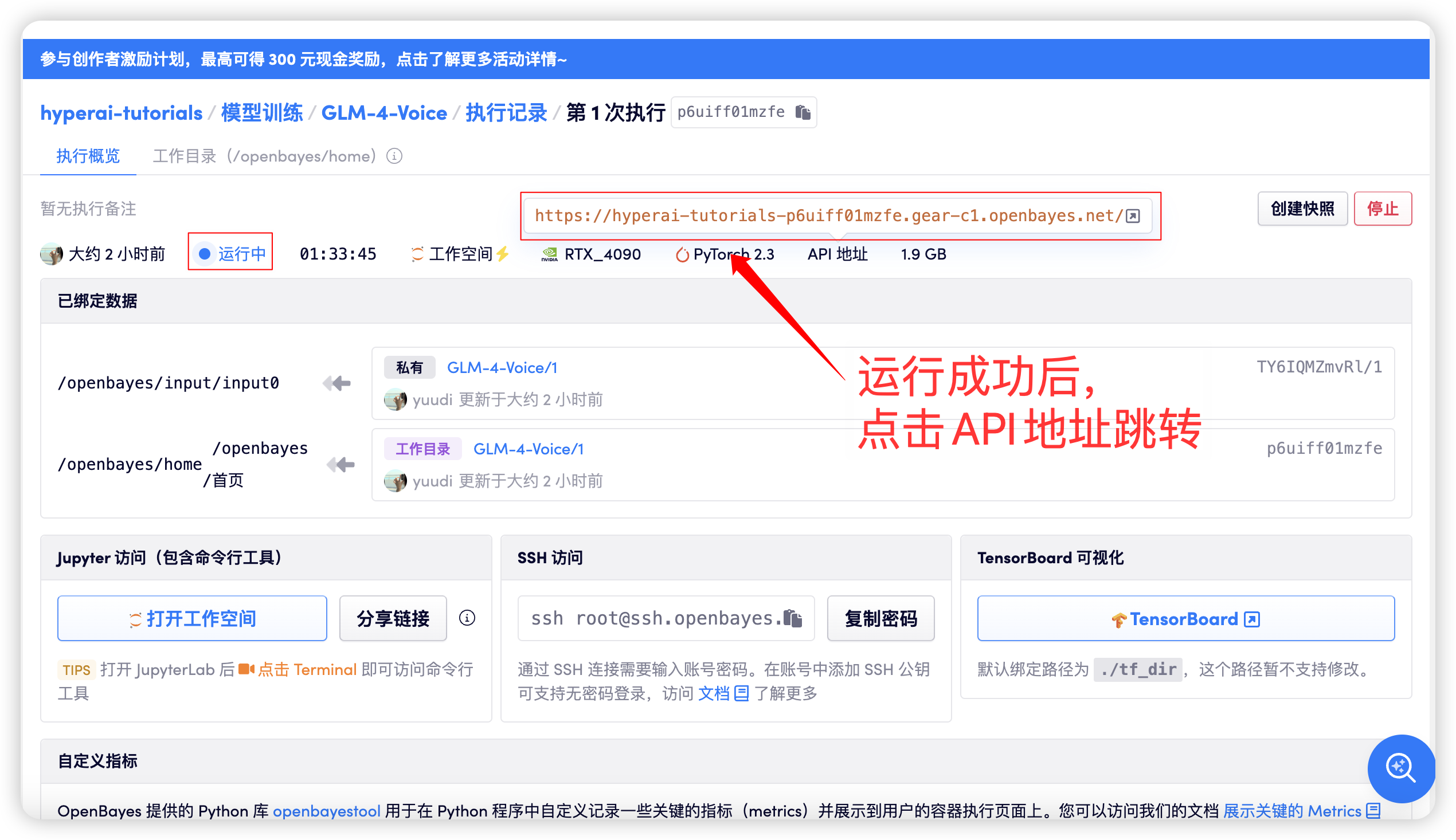
After starting the container, click the API address to enter the Web interface
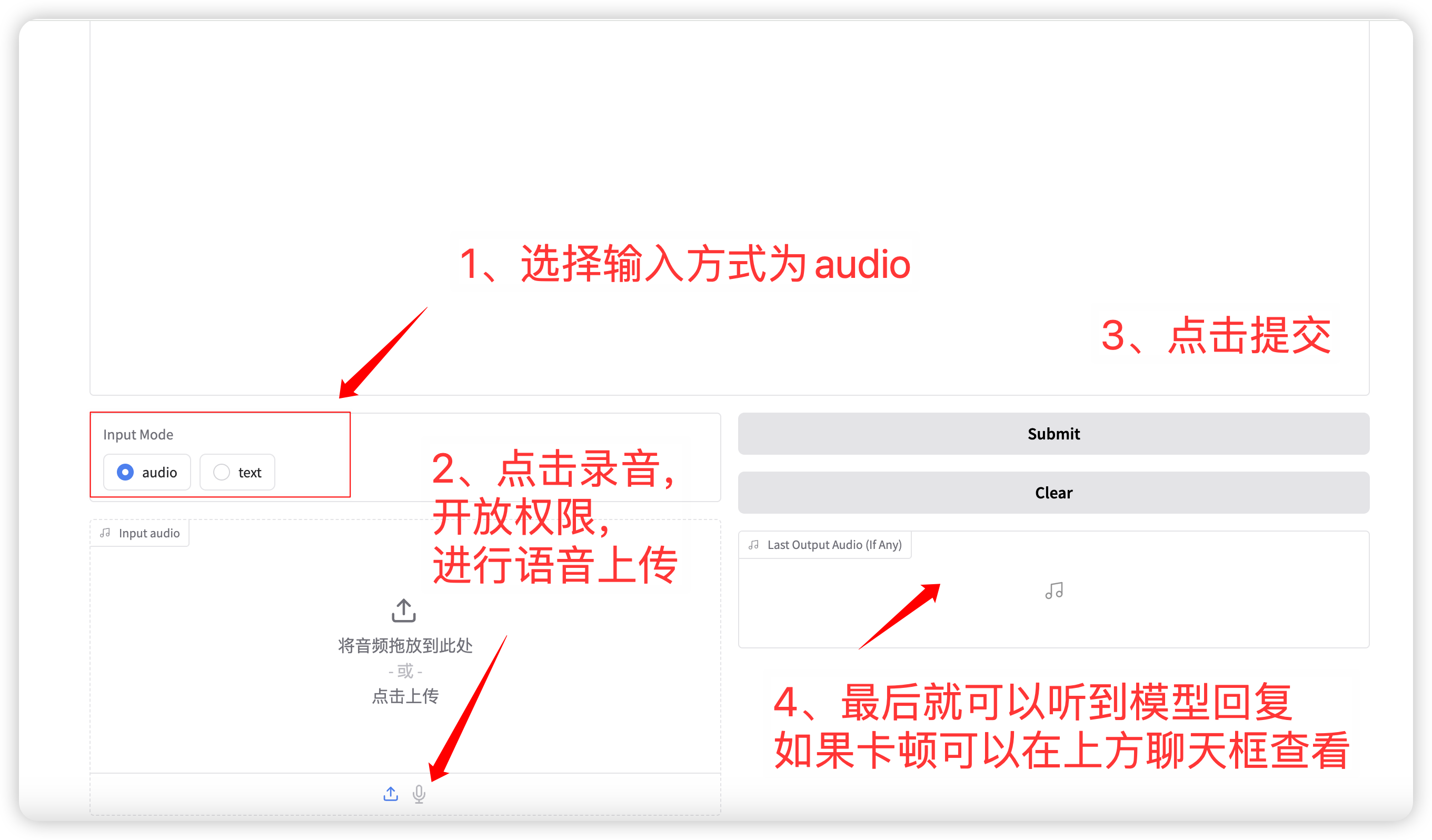
1. Voice dialogue
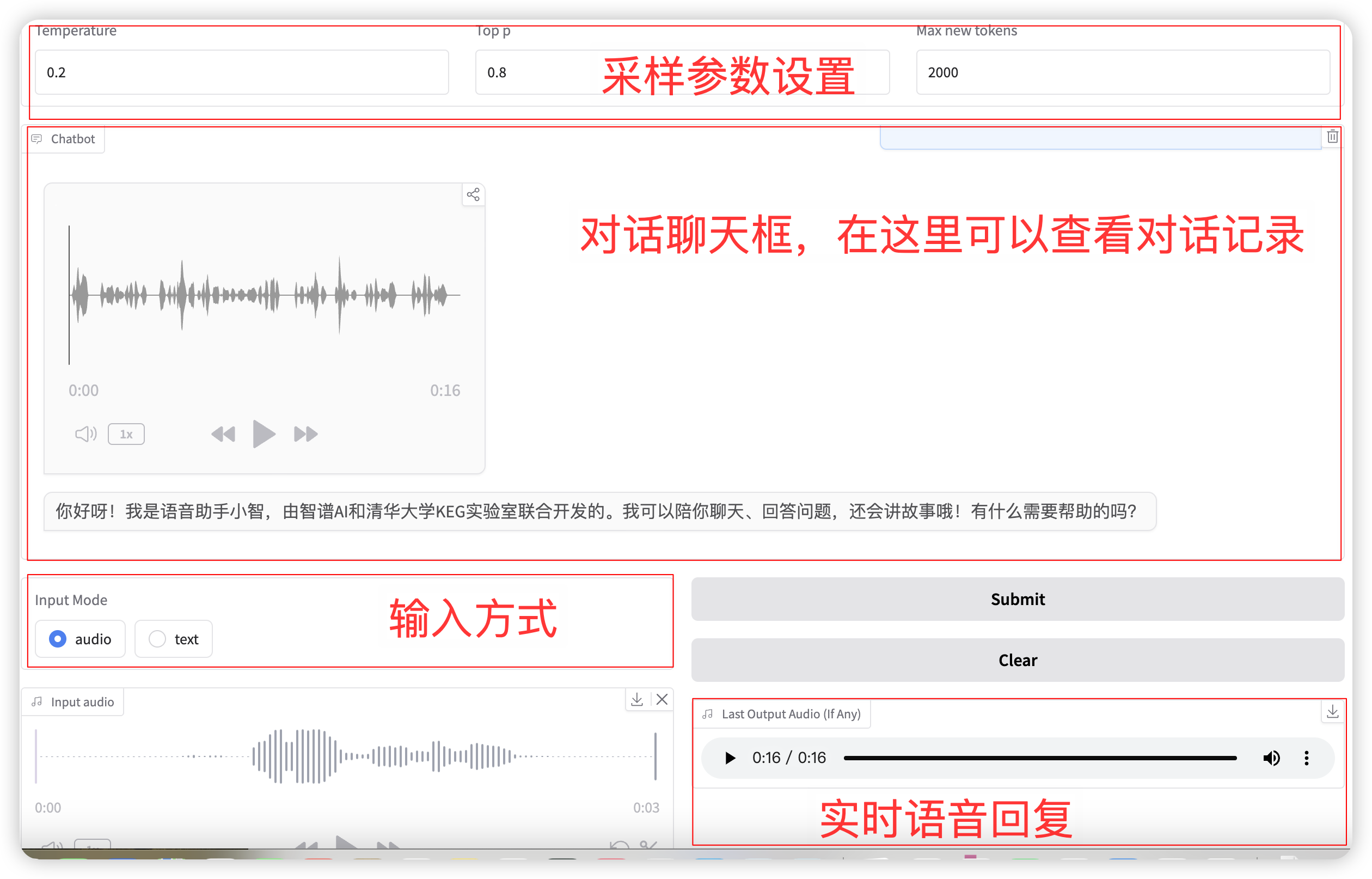
Input mode selection audio Function, click to record or upload a voice file. The relevant sampling parameters are:
- Temperature: Range 0-1, the higher the temperature, the greater the randomness of the generation!
- Top p: Used to specify that only the top p options with the highest probability will be considered when selecting the next word during the generation process. This helps maintain diversity when generating text and avoids always selecting the prediction result with the highest probability, making the generated text richer and more diverse.
- Max new tokens: The maximum number of tokens generated.
After completing the settings, the model will output voice and text in real time, but it may be intermittent due to network latency. You can listen to the voice in the chat box. The overall page layout is as follows:
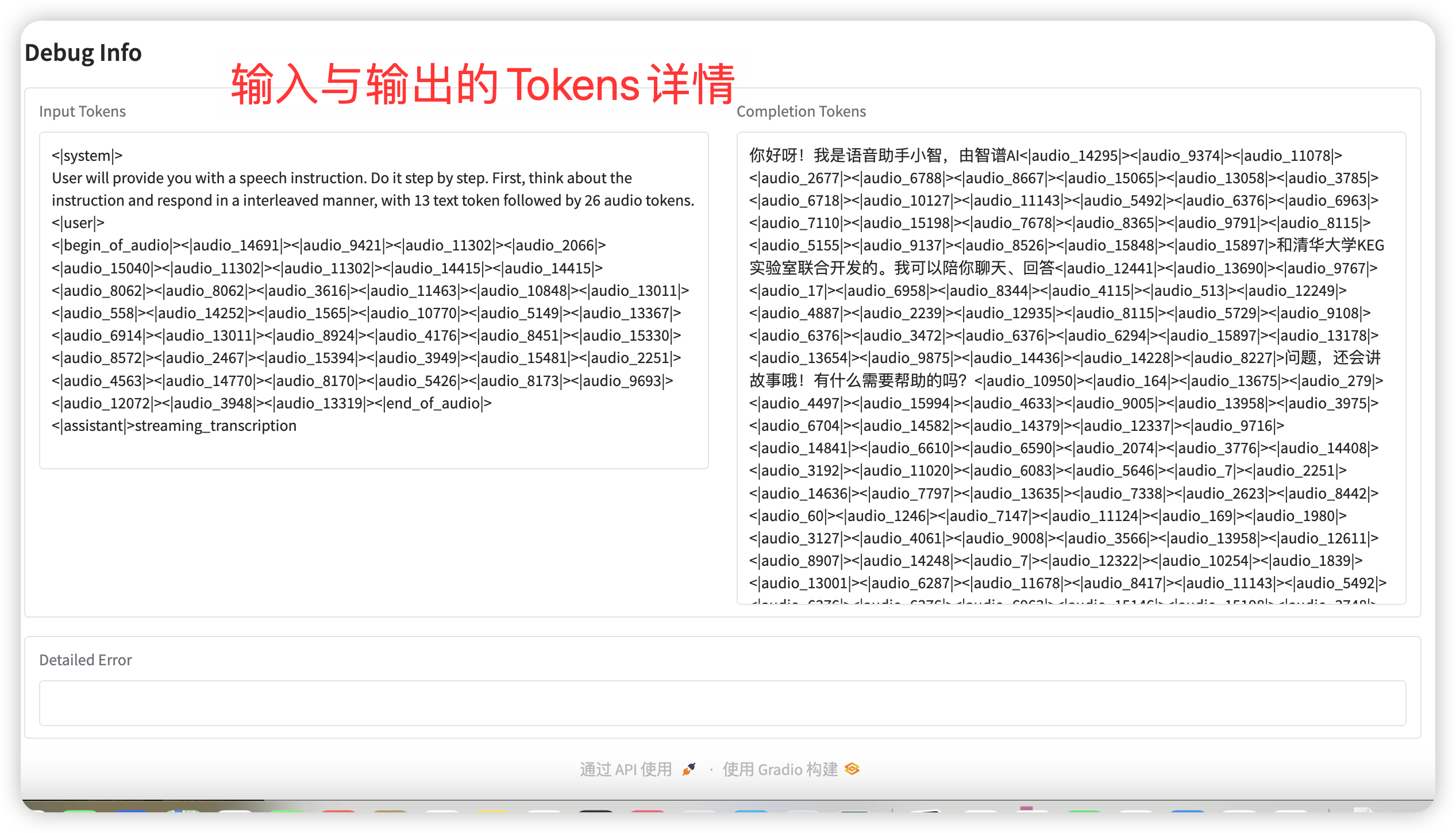
语音对话流程
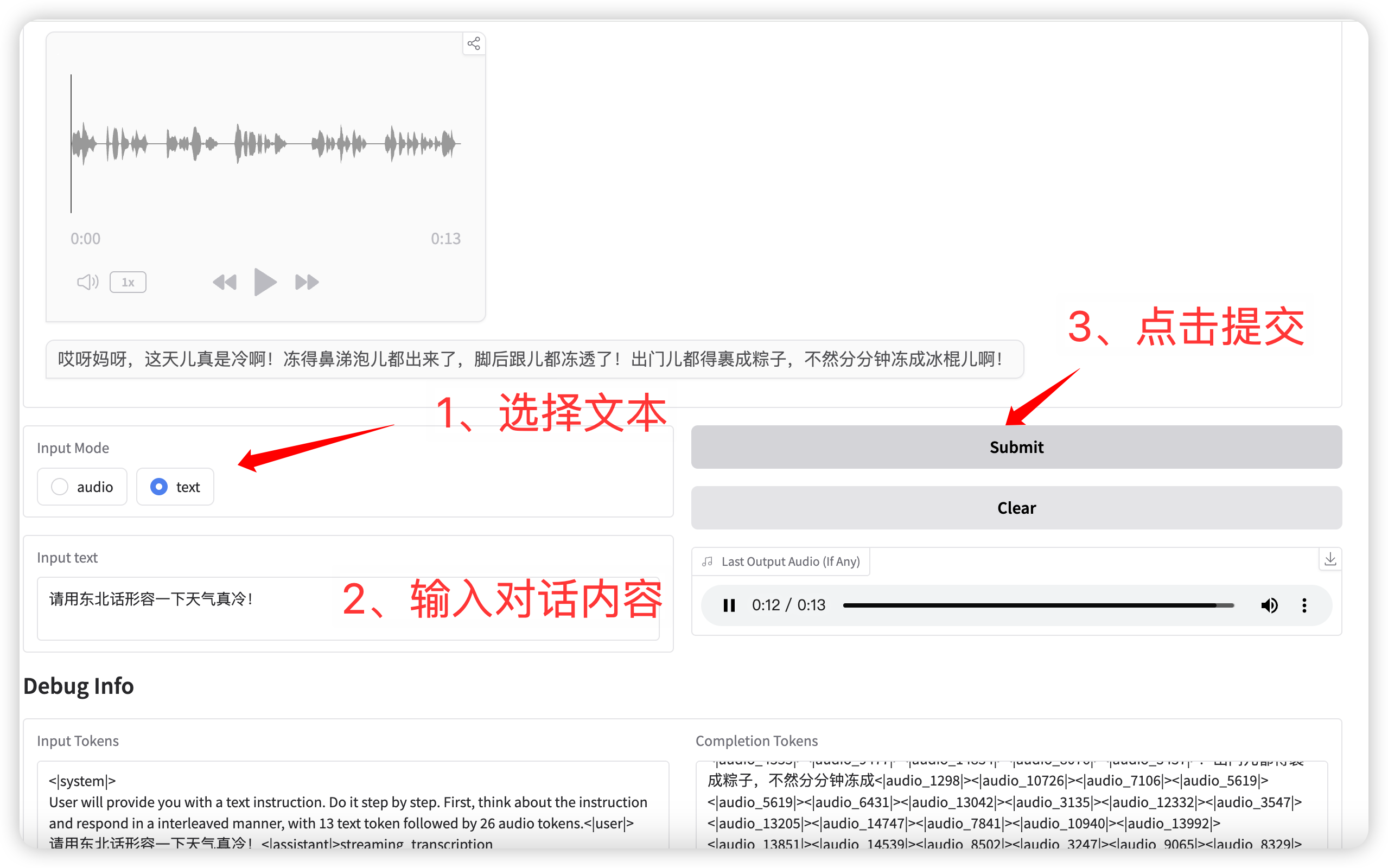
2. Text Conversation
输入模式选择 **text** 功能,输入对话文本。
点击提交后,模型同时输出文本和语音。
语音对话(输入为文本)
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.