Command Palette
Search for a command to run...
ShowUI: A vision-language-action Model Focusing on GUI Automation
Date
Size
486.51 MB
License
Apache 2.0
GitHub
Paper URL

1. Tutorial Introduction

ShowUI, a visual-language-action model jointly developed by the Show Lab at the National University of Singapore and Microsoft in 2024, is designed for graphical user interface (GUI) intelligent assistants to improve human work efficiency. This model understands the content of the screen interface and performs interactive actions such as clicking, typing, and scrolling. Supporting both web and mobile application scenarios, it can automatically complete complex user interface tasks. ShowUI can parse screenshots and user commands to predict interactive actions on the interface. Related research papers are available. ShowUI: One Vision-Language-Action Model for GUI Visual Agent It has been included in CVPR 2025.
This tutorial uses a single RTX 5090 graphics card as the default resource, but a minimum single RTX 4090 graphics card can be used to start the program.
2. Project Examples
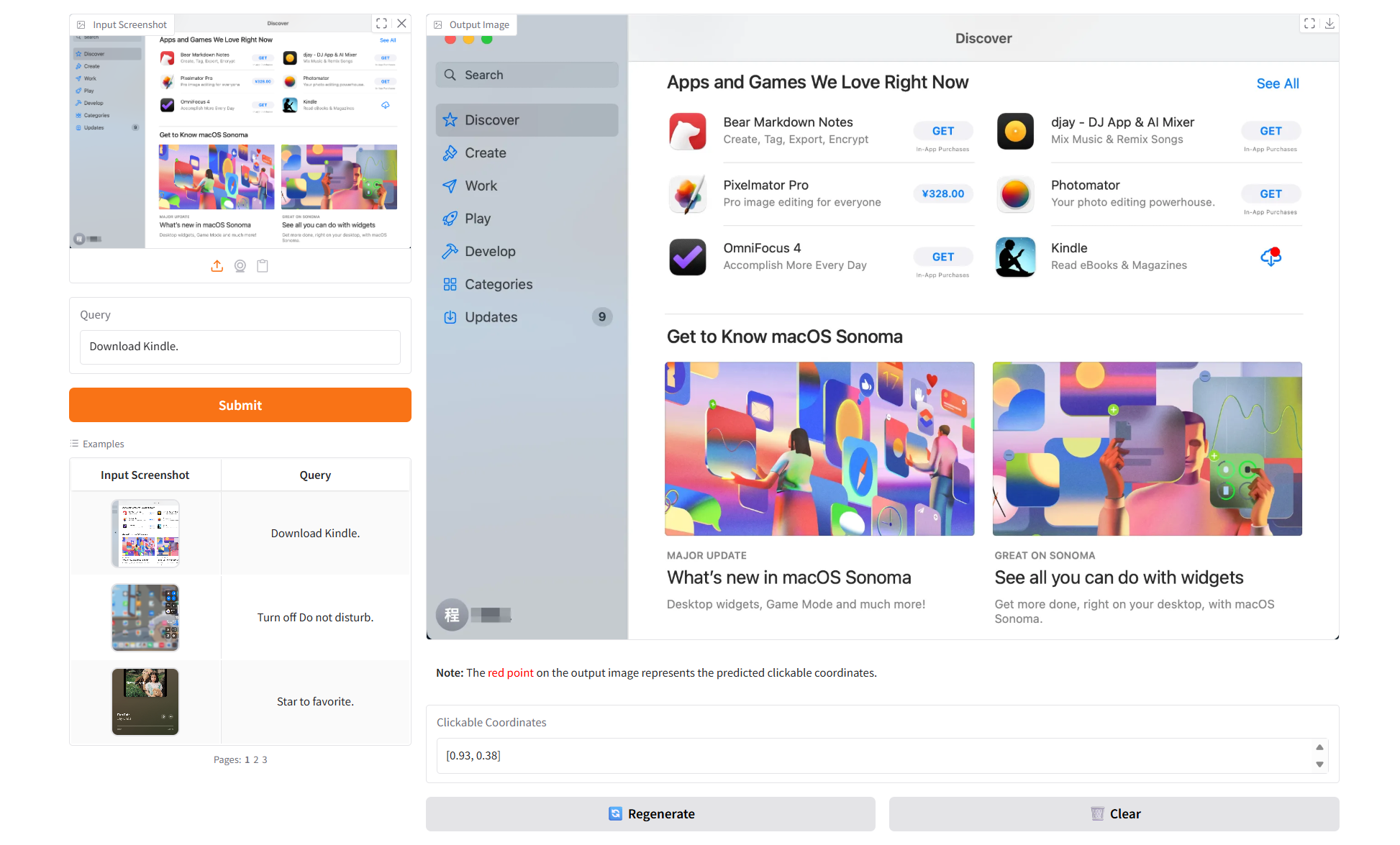
3. Operation steps
1. After starting the container, click the API address to enter the Web interface
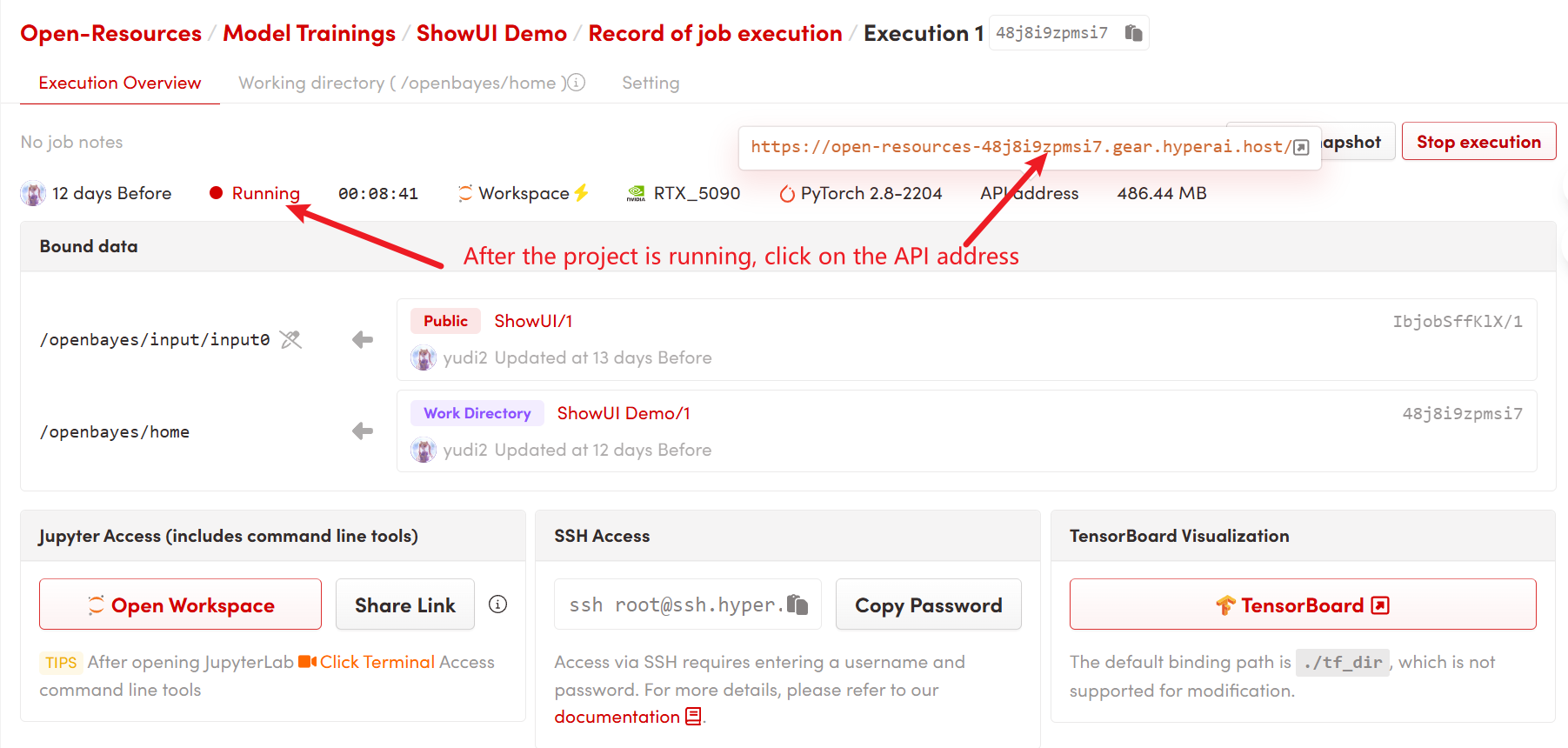
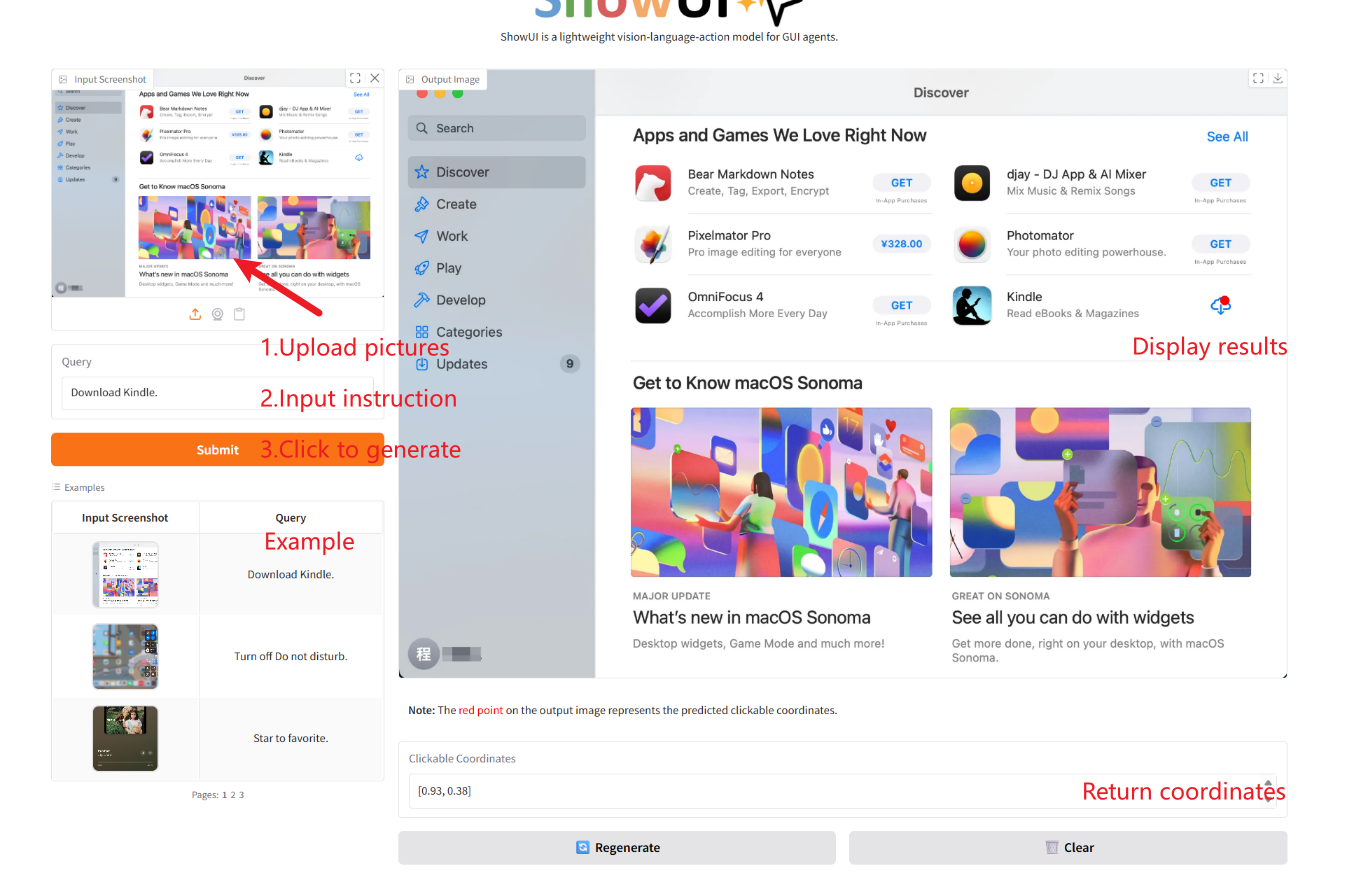
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
Citation Information
@misc{lin2024showui,
title={ShowUI: One Vision-Language-Action Model for GUI Visual Agent},
author={Kevin Qinghong Lin and Linjie Li and Difei Gao and Zhengyuan Yang and Shiwei Wu and Zechen Bai and Weixian Lei and Lijuan Wang and Mike Zheng Shou},
year={2024},
eprint={2411.17465},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.17465},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.