Command Palette
Search for a command to run...
Hunyuan3D: Generate 3D Assets in Just 10 Seconds
Tencent Hunyuan3D-1.0: A unified framework for text-to-3D and image-to-3D conversion


1. Tutorial Introduction
Hunyuan3D-1.0 is a 3D generative diffusion model released by Tencent's research team in 2024. It includes a lightweight version and a standard version, both supporting the generation of high-quality 3D assets from text and image inputs. The lightweight version can generate 3D objects in approximately 10 seconds, while the standard version completes the process in approximately 25 seconds. The standard version has three times more parameters than the lightweight version and other existing models. Related technical reports are available. Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation .
The framework involves a text-to-image model, namely Hunyuan-DiT. Hunyuan3D-1.0 is a unified framework that can be applied to text-to-3D and image-to-3D generation. The model adopts a two-stage approach to generate 3D assets. The first stage uses a multi-view diffusion model to efficiently generate multi-view RGB images in about 4 seconds. The second stage introduces a feedforward reconstruction model to use these multi-view images to quickly and accurately reconstruct 3D views in about 3 seconds. The model is able to reconstruct objects of various scales, from large buildings to small tools or flowers. It outperforms mainstream open source models on two public 3D datasets, GSO and OmniObject3D, and its overall capabilities are at the international leading level. After qualitative and quantitative multi-dimensional evaluations, Hunyuan3D-1.0 performs very well in terms of geometric details, texture details, texture-geometry consistency, 3D rationality, and instruction compliance.
The release of Hunyuan3D-1.0 provides 3D creators and artists with a powerful tool that can automate the production of 3D assets and improve the speed and generalization of 3D generation.
This tutorial is a lightweight version of Hunyuan3D-1.0. It uses 3 models to make the web interface include 2 functions:
Two functions:
- Image to 3D (image_to_3D)
- Text to 3D (text_to_3D)
Three models:
- Hunyuan3D-1/lite A compact model for multi-view generation
- Hunyuan3D-1/std Standard model for multi-view generation
- Hunyuan3D-1/svrm sparse view reconstruction model
2. Effect Examples

3. Operation steps
启动容器后等待约 3 分钟(加载模型),点击 API 地址即可进入 Web 界面(否则将会显示 BadGateway)
1. Image to 3D (image_to_3d)
选择「Text to 3D」功能,按如下要求输入提示词和进行相关设置
如果需要生成 gif 必须选中「Render gif」,否则不会生成效果。其他功能无需选中
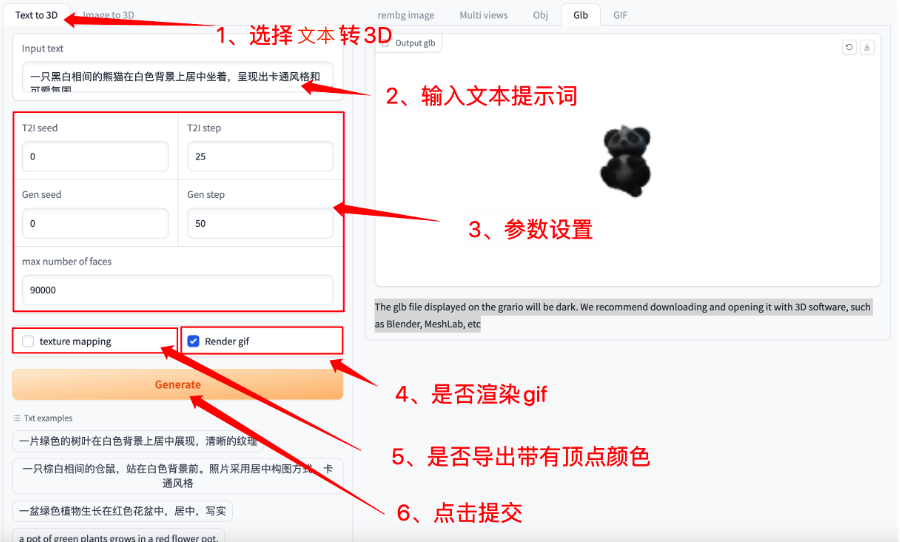
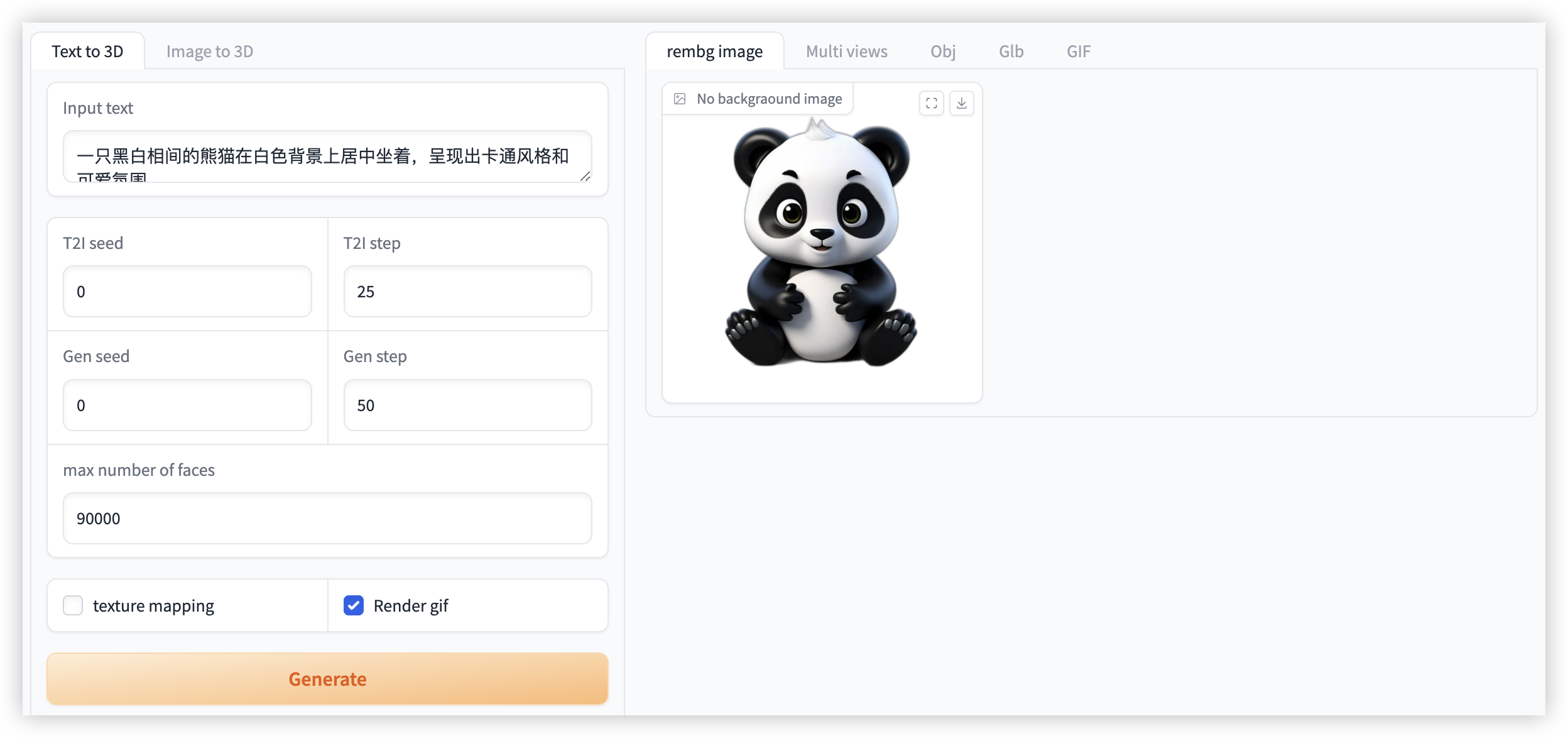
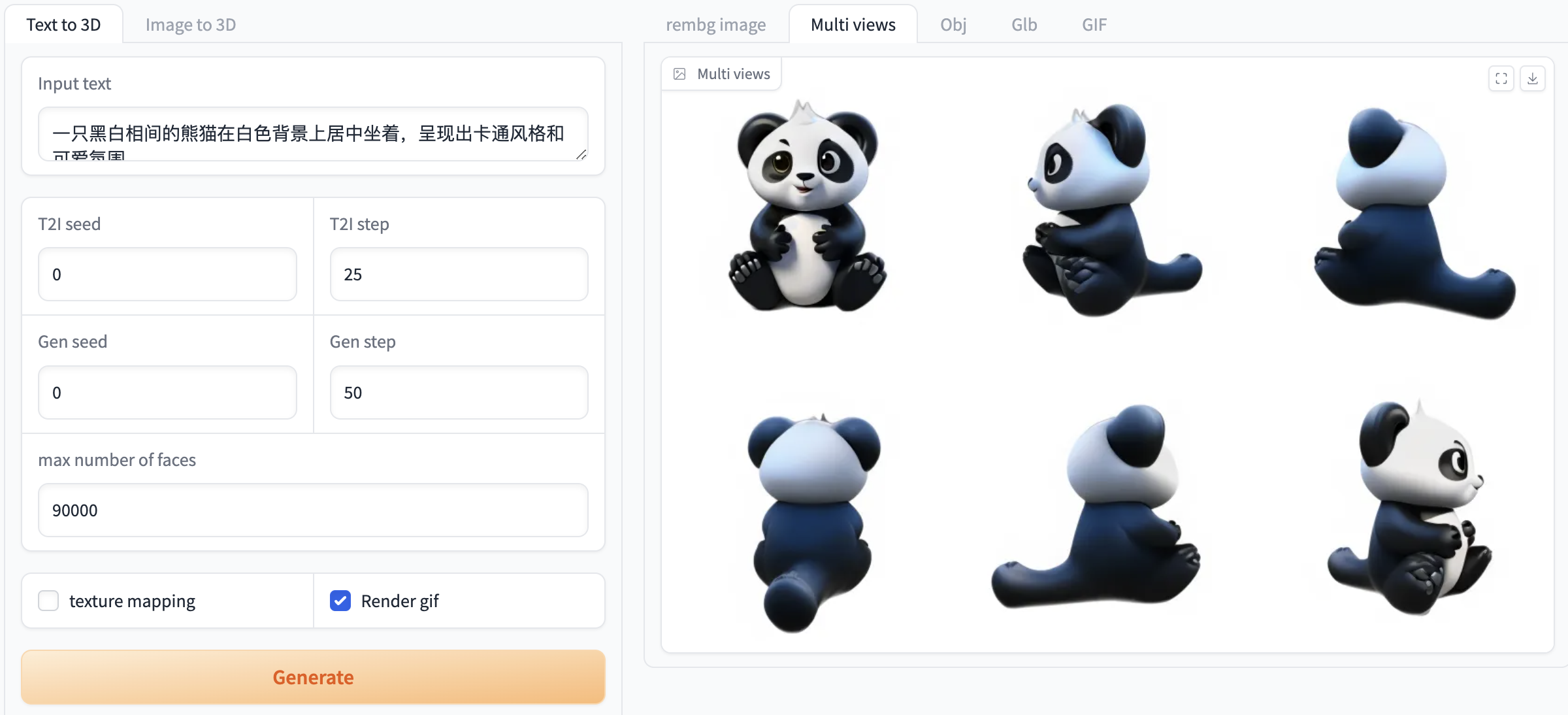
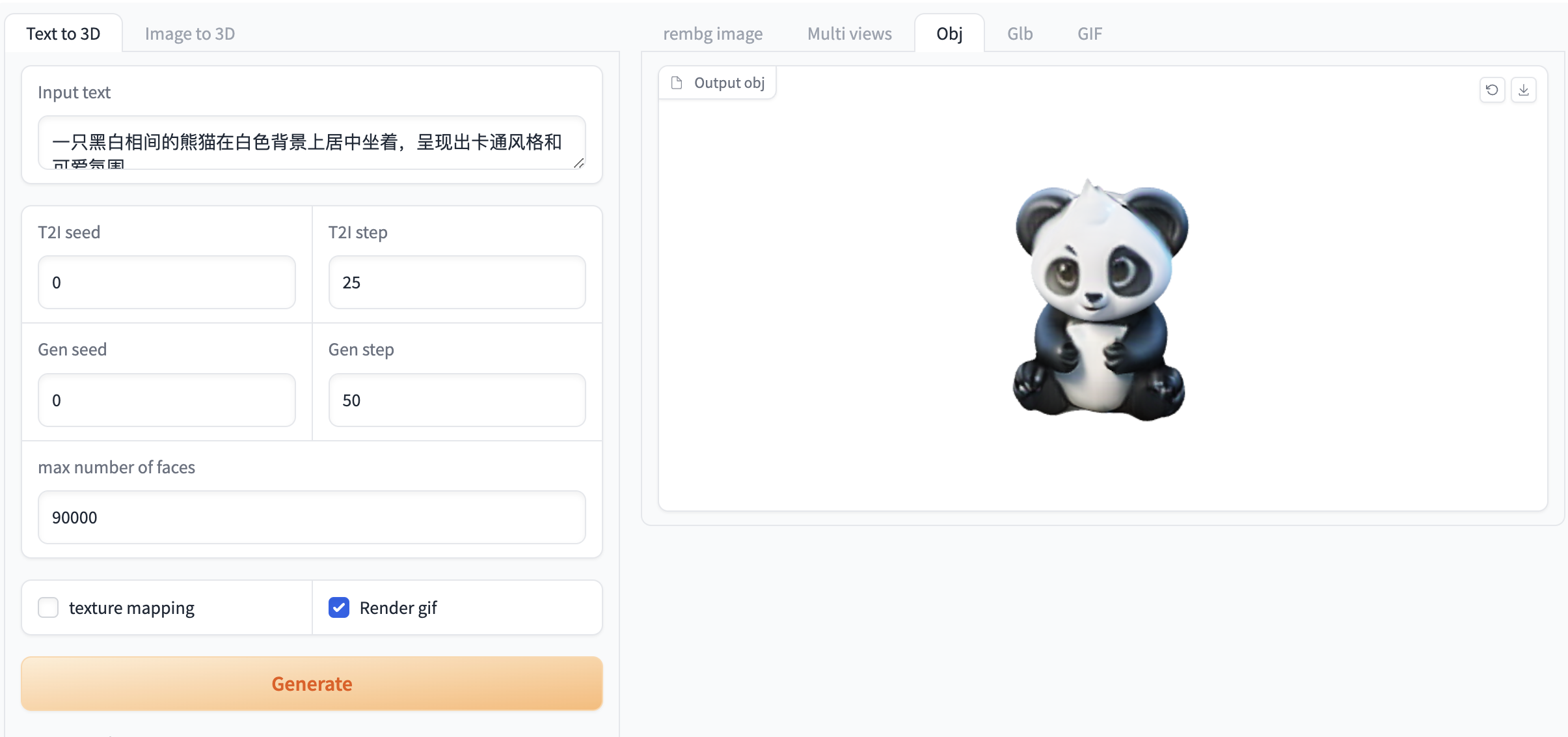
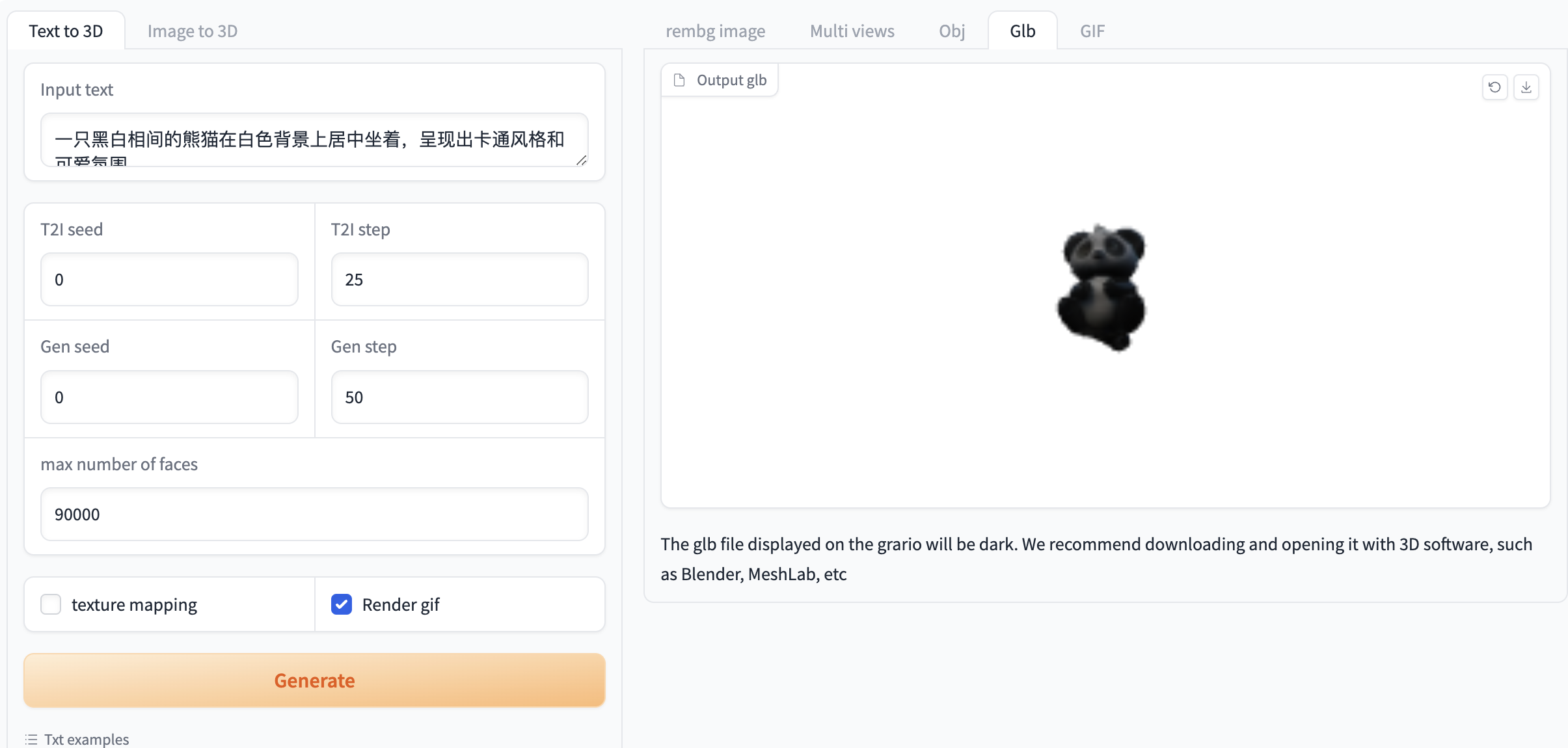
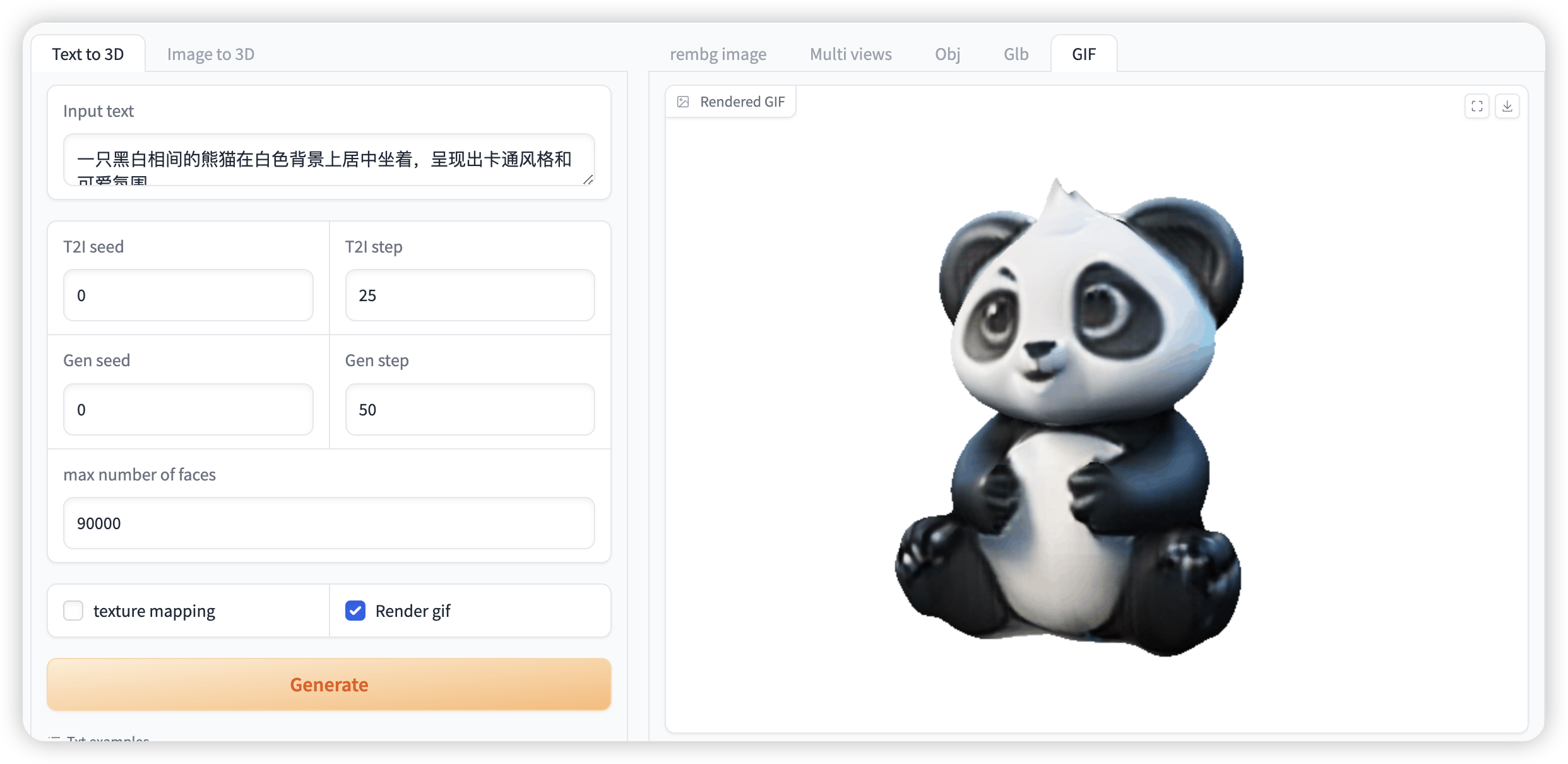
Figure 1. Image generation video demonstration
2. Text to 3D (image_to_video)
选择「Image to 3D」功能,按如下要求输入提示词和相关设置。
注意:自行上传图像时,请务必保证图片为 n*n 的正方形,否则会出现报错的情况
如果需要生成 gif 必须选中「Render gif」,否则不会生成效果。其他功能无需选中
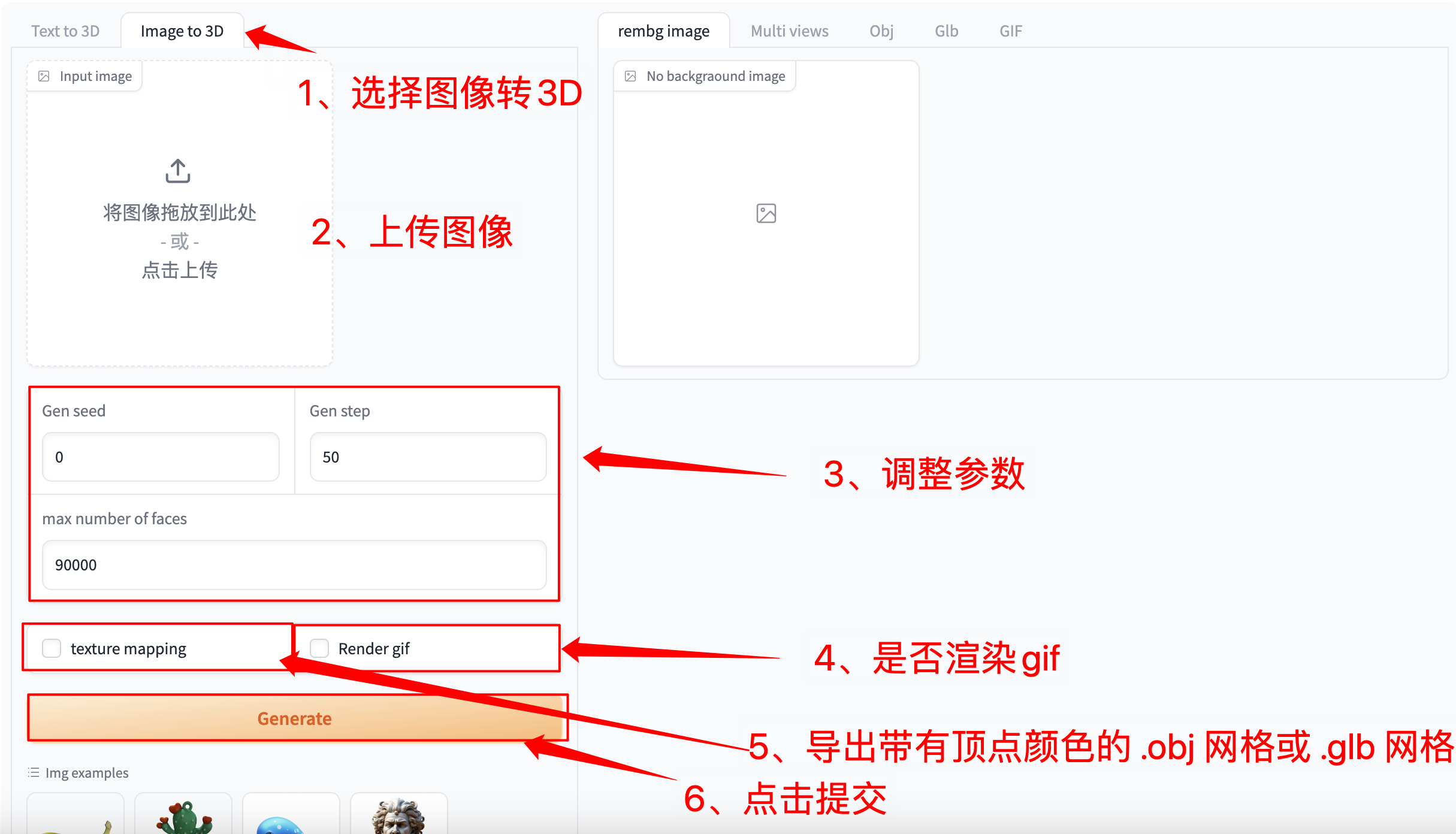
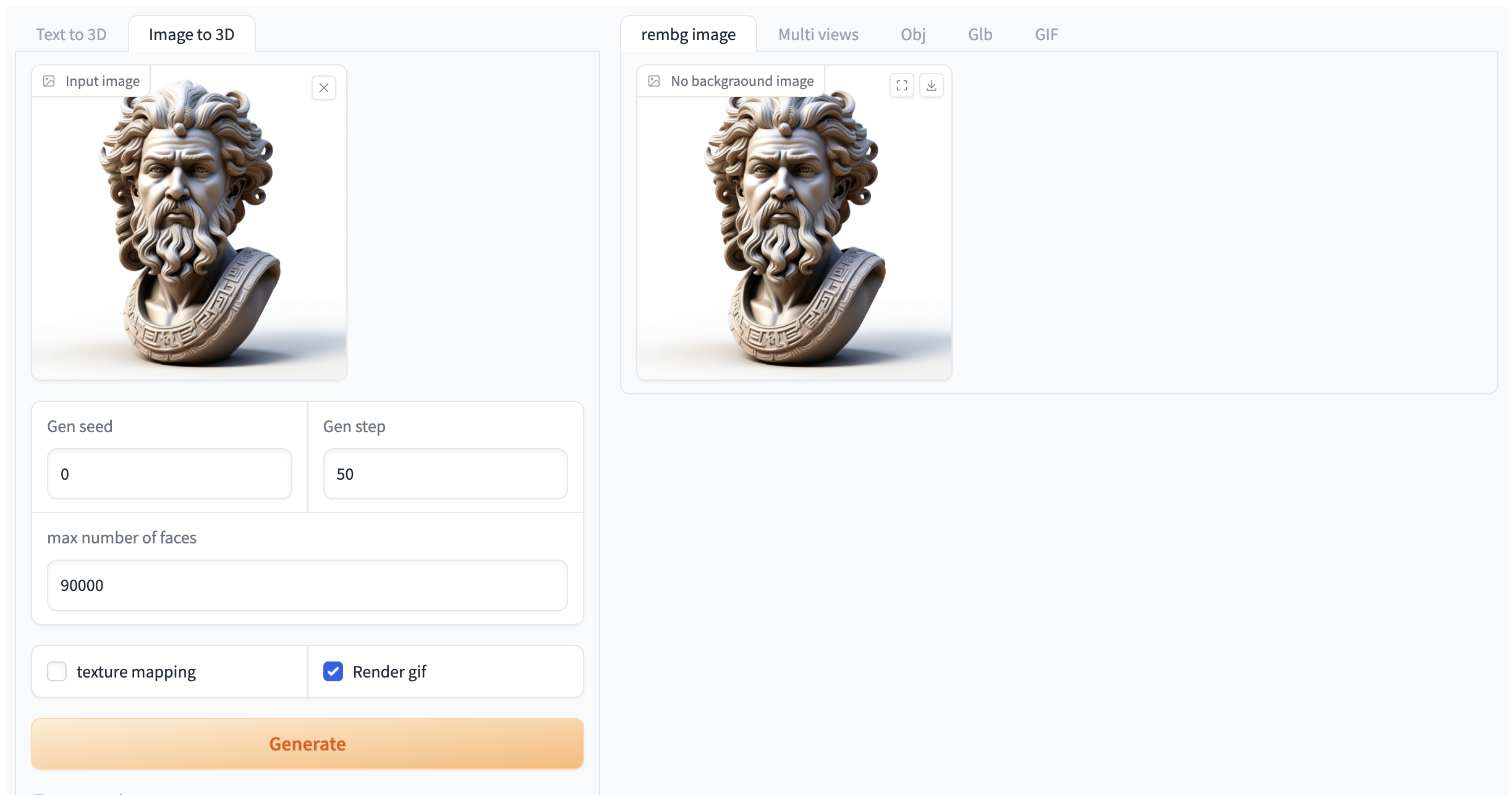
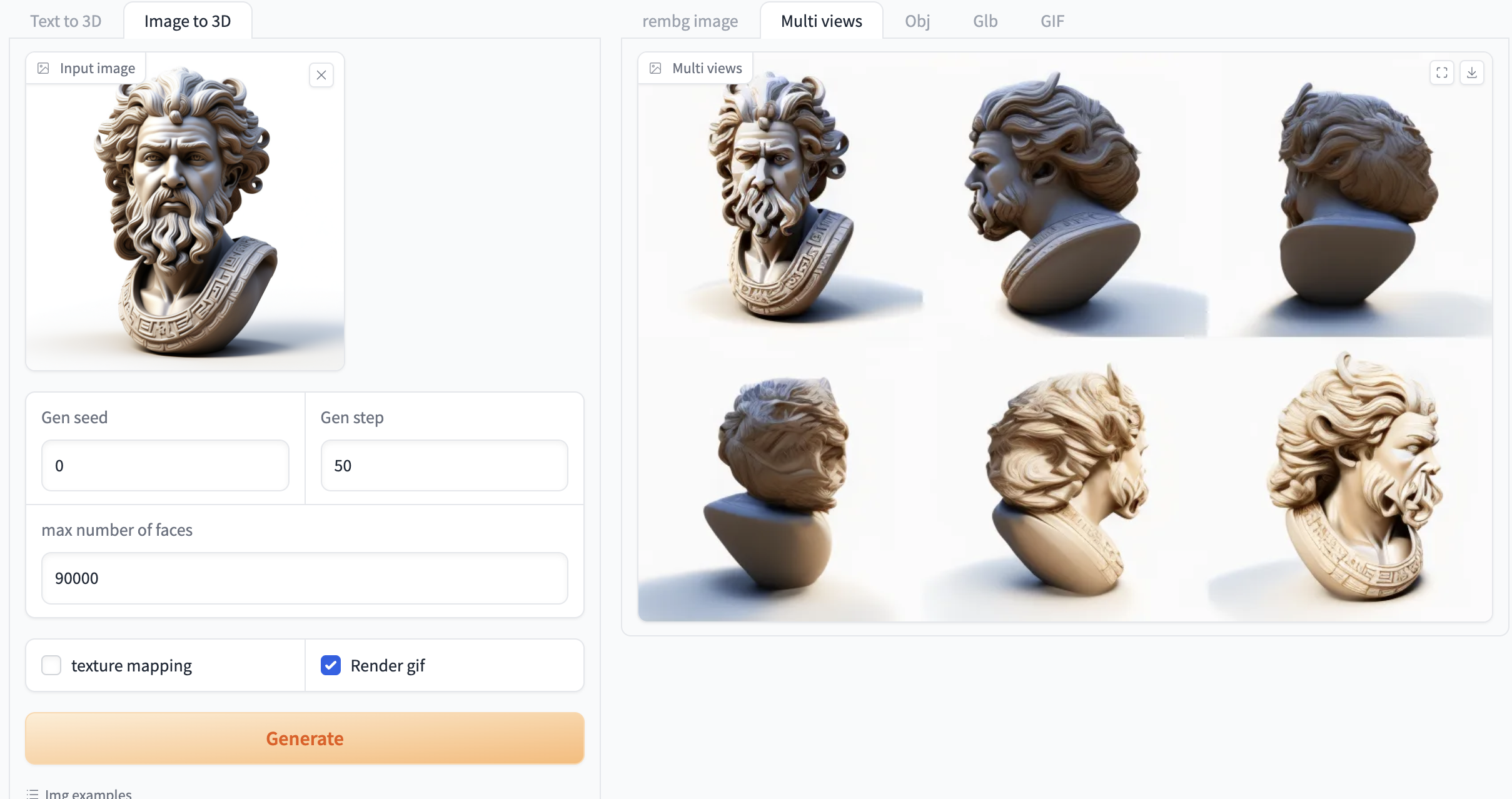
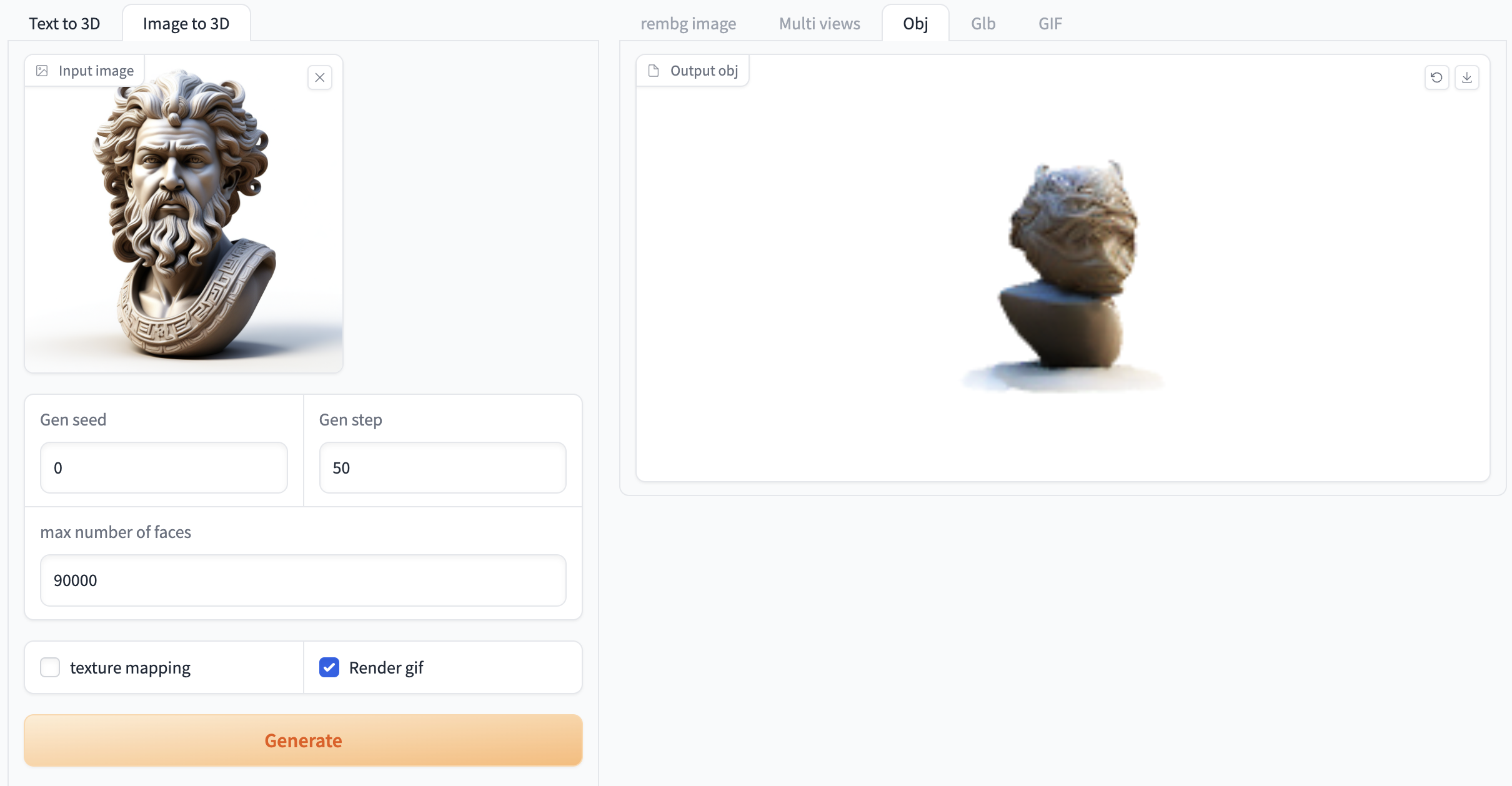
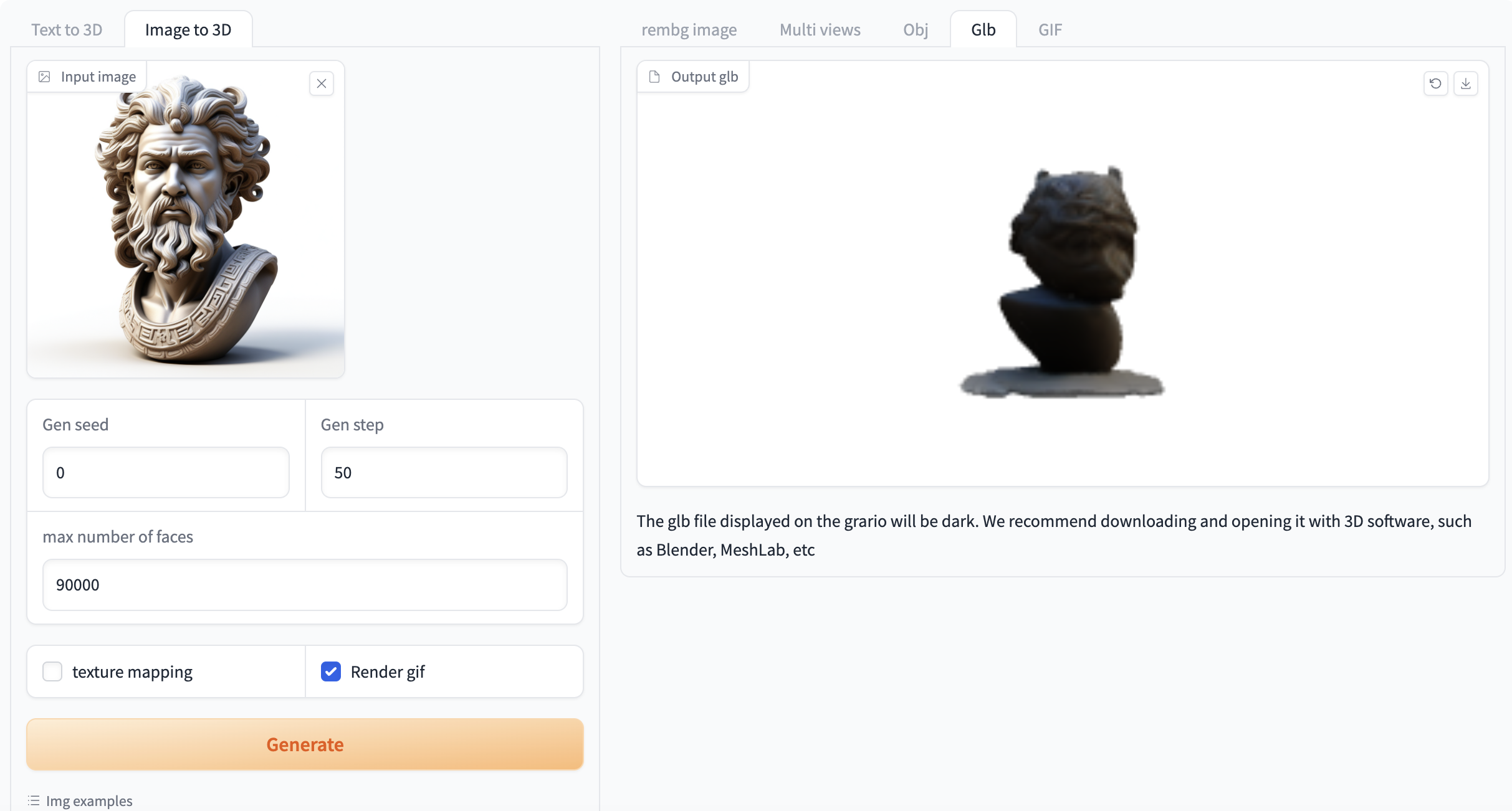
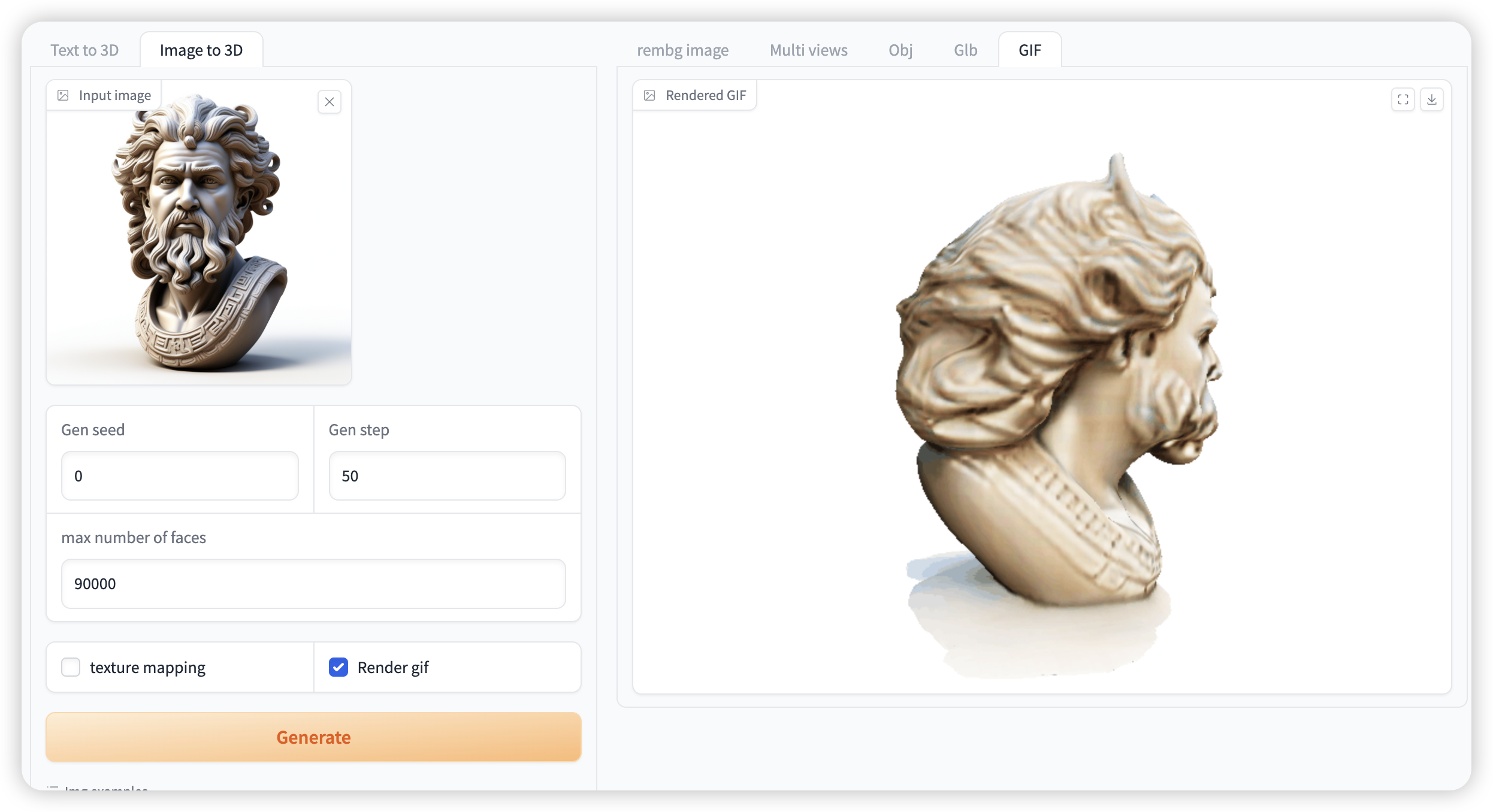

Figure 2 Image generation video demonstration
Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.