Command Palette
Search for a command to run...
F5-E2 TTS Clones Any Sound in Just 3 Seconds
1. Tutorial Introduction

This tutorial includes two demos of the models, F5-TTS and E2 TTS.
F5-TTS is a high-performance text-to-speech (TTS) system jointly open-sourced in 2024 by Shanghai Jiao Tong University, Cambridge University, and Geely Automobile Research Institute (Ningbo) Co., Ltd. It is based on a non-autoregressive generation method using stream matching, combined with diffusion transformer (DiT) technology. Related research papers are available. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching This system can rapidly generate natural, fluent, and faithful speech from the original text through zero-shot learning without additional supervision. F5-TTS supports multilingual synthesis, including Chinese and English, and can effectively synthesize speech on long texts. Furthermore, F5-TTS features emotion control, adjusting the emotional expression of the synthesized speech based on the text content, and supports speed control, allowing users to adjust the playback speed as needed. The system was trained on a large-scale dataset of 100,000 hours, demonstrating excellent performance and generalization ability. F5-TTS's main functions include zero-shot voice cloning, speed control, emotion control, long text synthesis, and multilingual support. Its technical principles involve stream matching, Diffusion Transformer (DiT), ConvNeXt V2 text representation improvement, Sway Sampling strategy, and end-to-end system design. F5-TTS has a wide range of applications, including audiobooks, voice assistants, language learning, news broadcasting, and game dubbing, providing powerful speech synthesis capabilities for various commercial and non-commercial uses.
E2 TTS, short for "Embarrassingly Easy Text-to-Speech," is an advanced text-to-speech (TTS) system that achieves human-level naturalness and speaker similarity through a simplified process. The core of E2 TTS lies in its completely non-autoregressive nature, meaning it can generate the entire speech sequence at once, without requiring stepwise generation, thus significantly improving generation speed while maintaining high-quality speech output. Related research papers include... E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTSE2 TTS, accepted by SLT 2024, transforms text input into a sequence of characters with padding markers. A Mel spectrogram generator based on stream matching is then trained for the audio padding task. Unlike many previous works, it requires no additional components (e.g., duration models, character-to-phoneme conversion) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS functionality, comparable to or surpassing previous work including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in input representation.
该教程支持如下模型和功能: 2 个模型检查点: F5-TTS E2 TTS 3 个功能:单人语音生成(Batched TTS): 根据上传的音频进行文本生成。 双人语音生成(Podcast Generation):根据双人音频模拟双人对话。多种语音类型生成(Multiple Speech-Type Generation):可根据同一讲话人不同情绪下的音频,生成不同情绪的音频。
This tutorial uses a single RTX 5090 card as the resource.
2. Project Examples
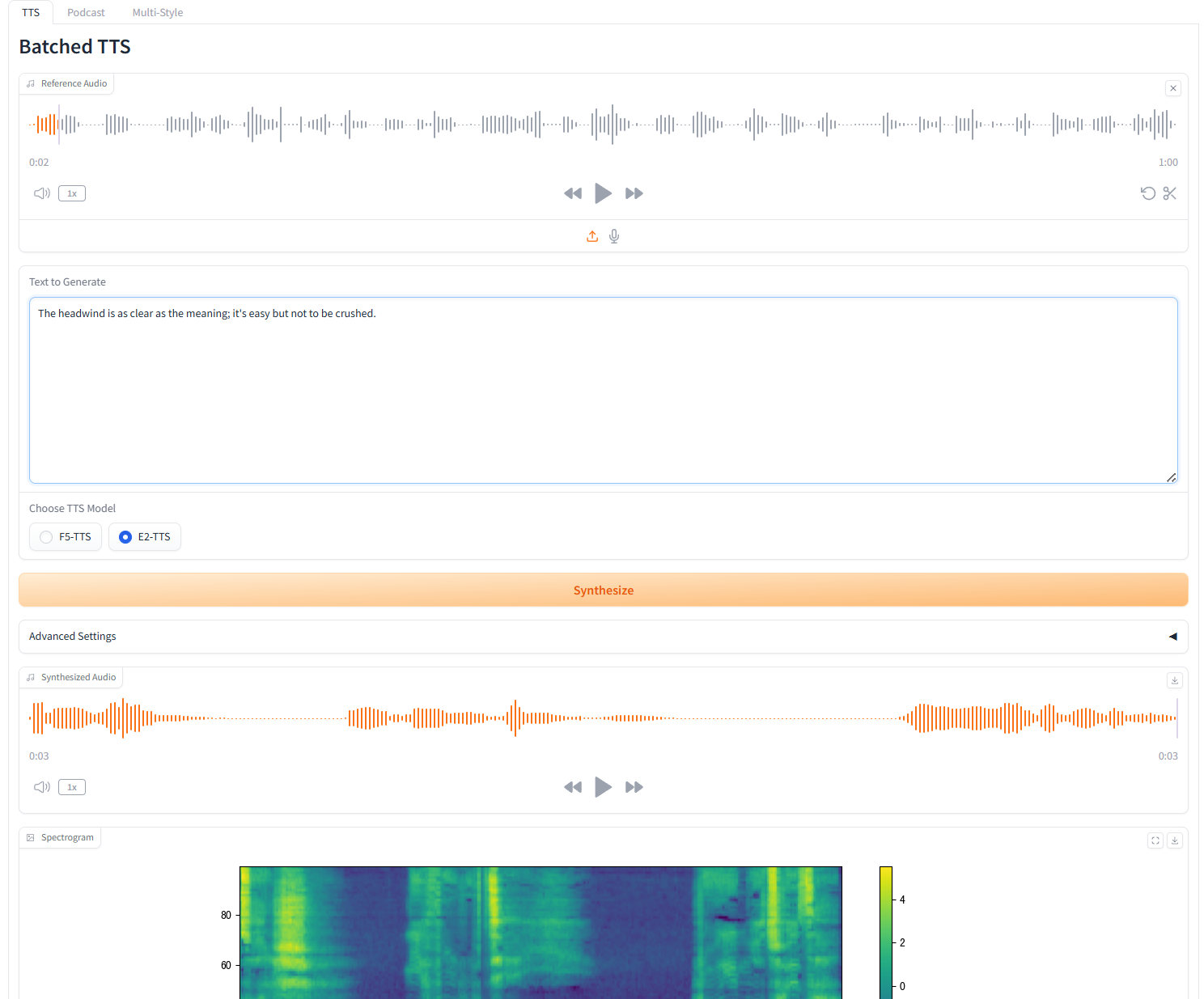
1. Batched TTS
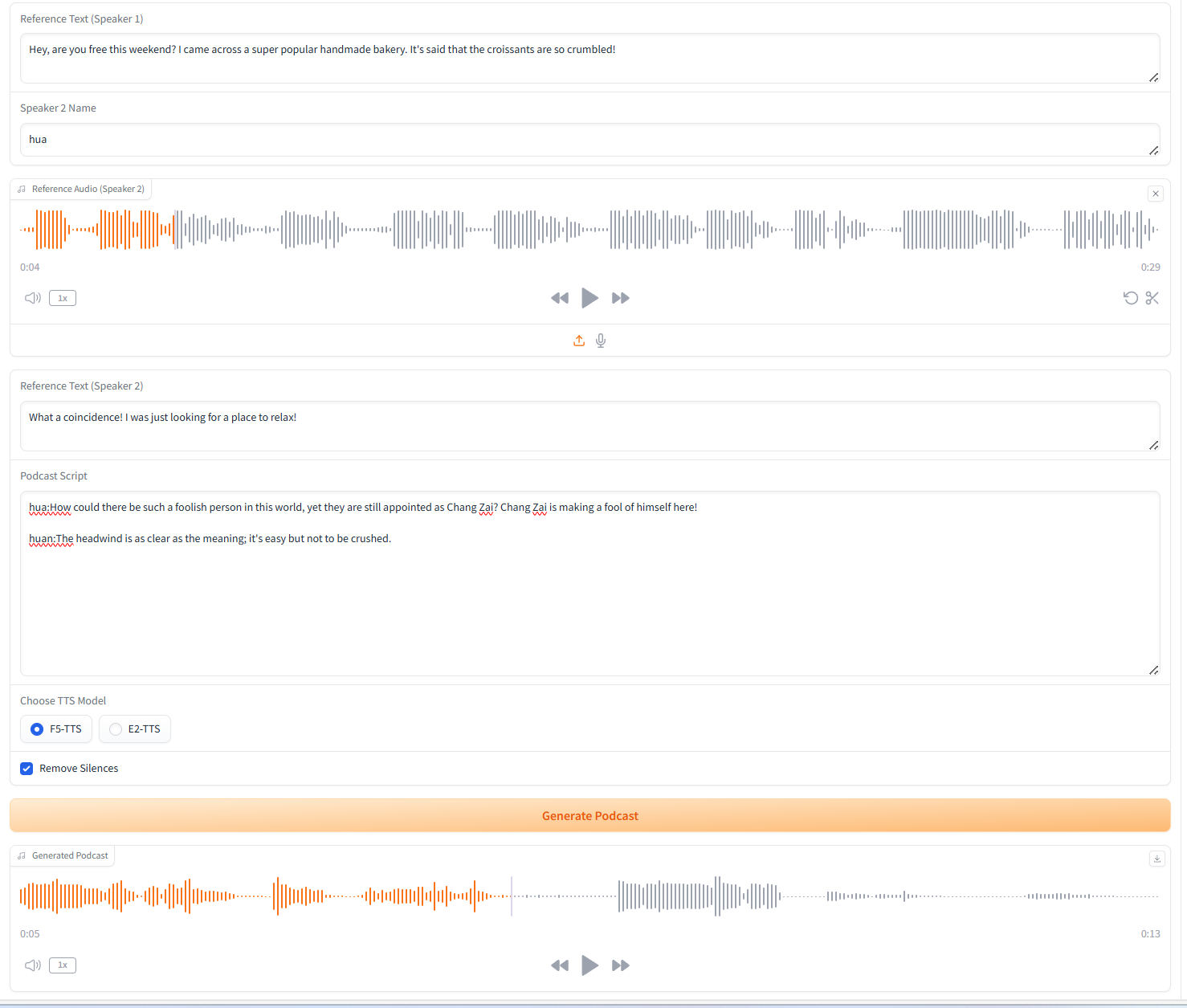
2. Podcast Generation
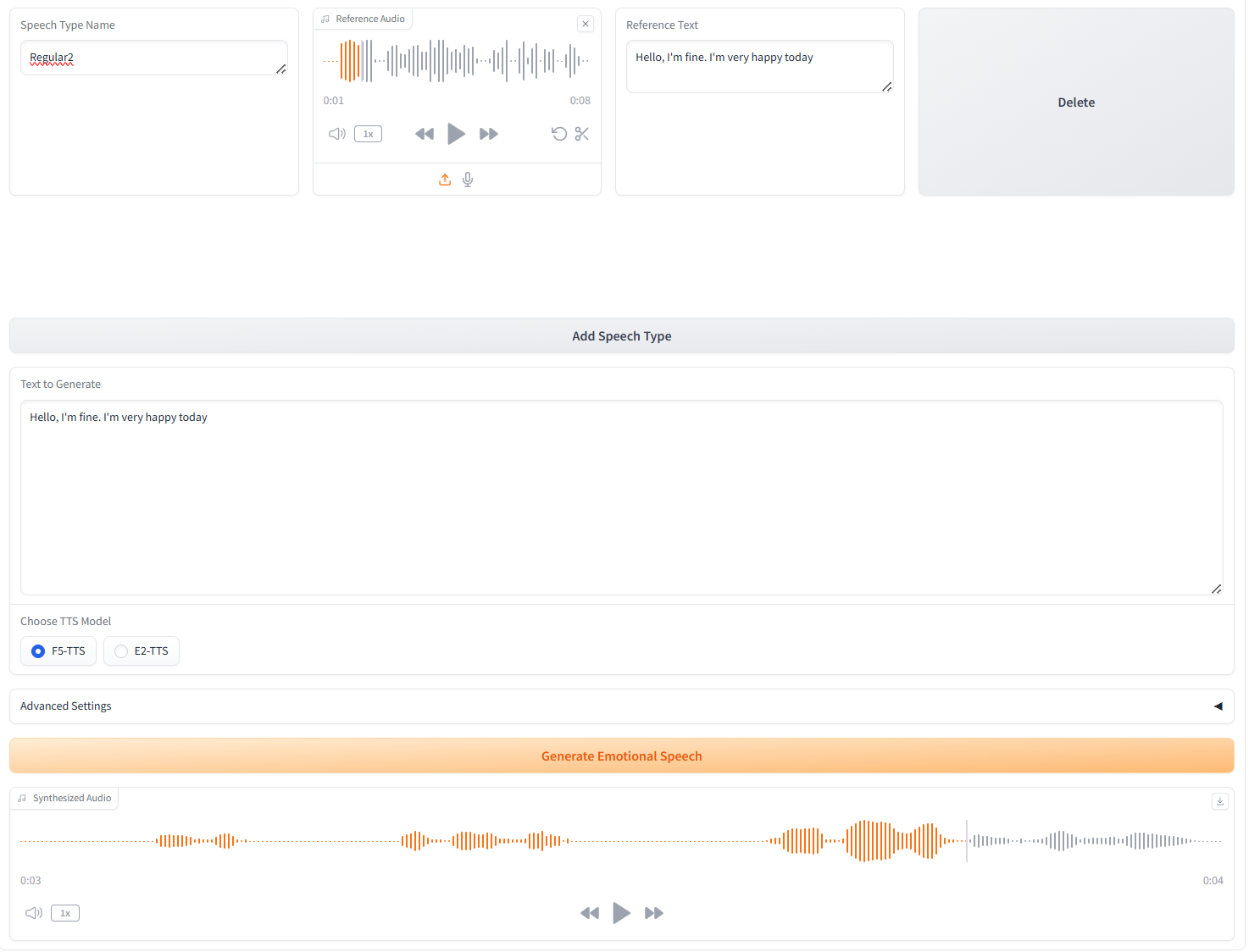
3. Multiple Speech-Type Generation
3. Operation steps
1. After starting the container, click the API address to enter the Web interface
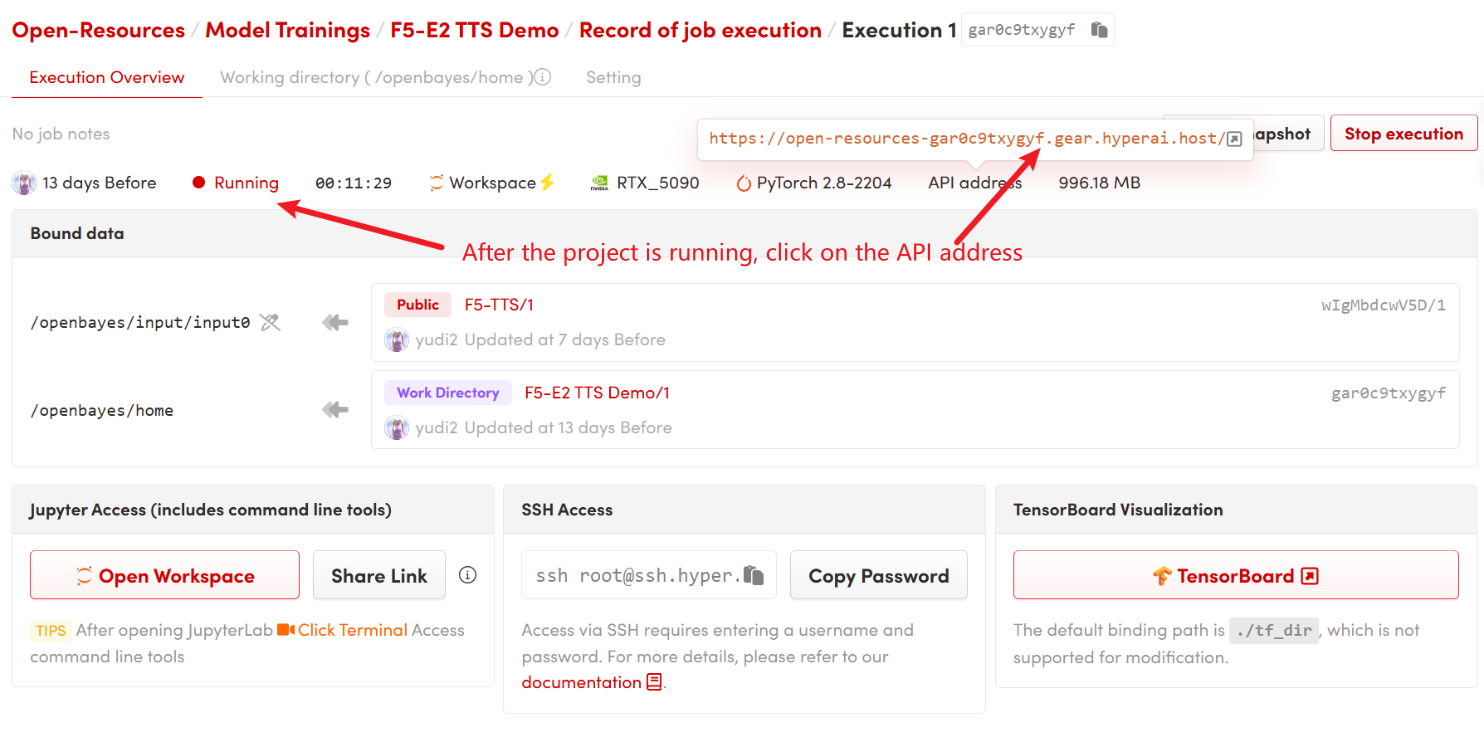
2. Usage steps
If "Bad Gateway" is displayed, it means that the model is initializing. Since the model is large, please wait about 9 minutes and then refresh the page.
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
1. Batched TTS
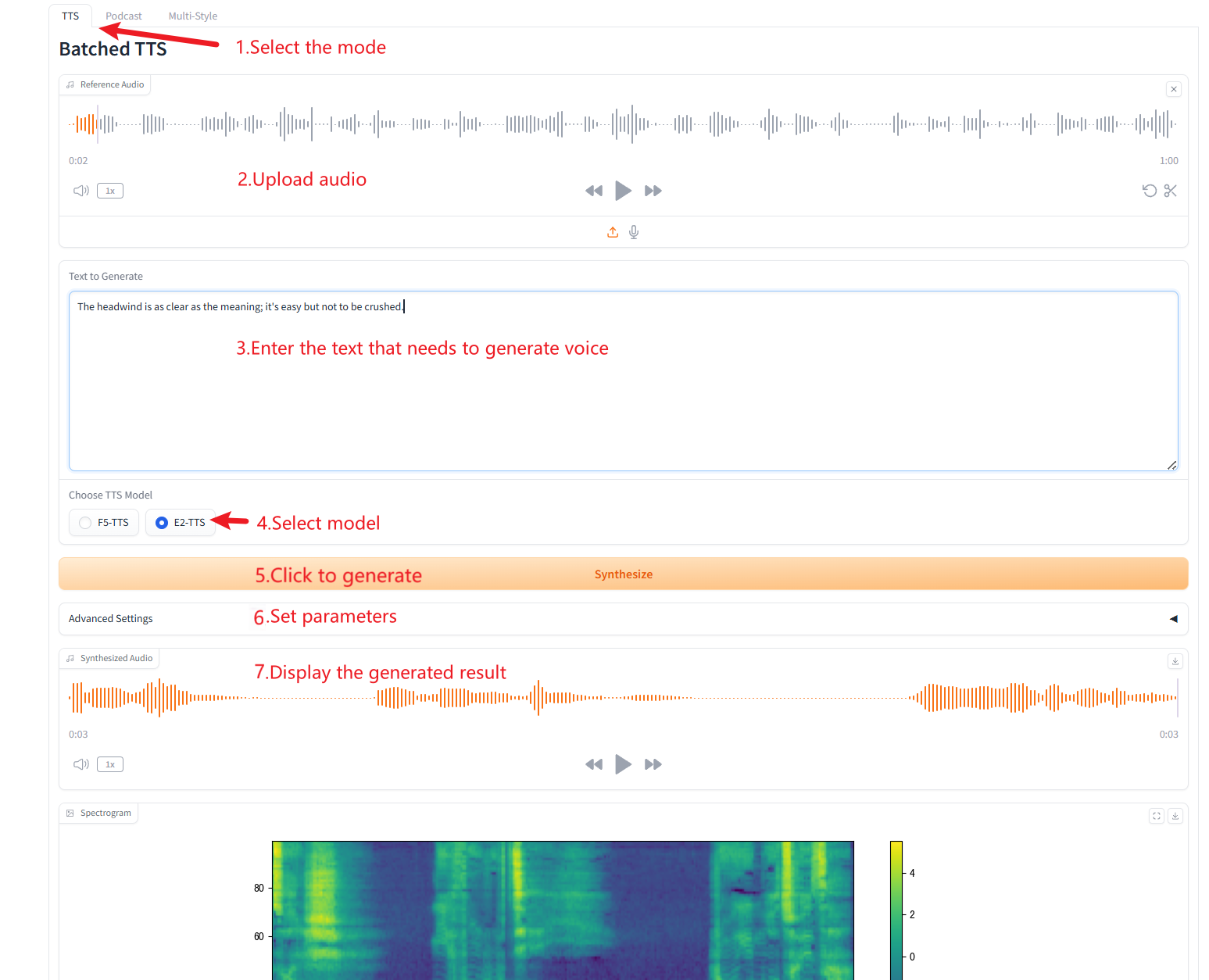
Parameter Description
- Reference Text: Leave blank to automatically transcribe the reference audio. If you enter text, it will override the automatic transcription.
- Remove Silences: The model tends to produce silence, especially on longer audio. We can remove silence manually if needed. Please note that this is an experimental feature and may produce strange results. This will also increase generation time.
- Custom Split Words: Enter custom words to split, separated by commas. Leave blank to use the default list.
- speed: Control the speed of generated speech
2. Podcast Generation
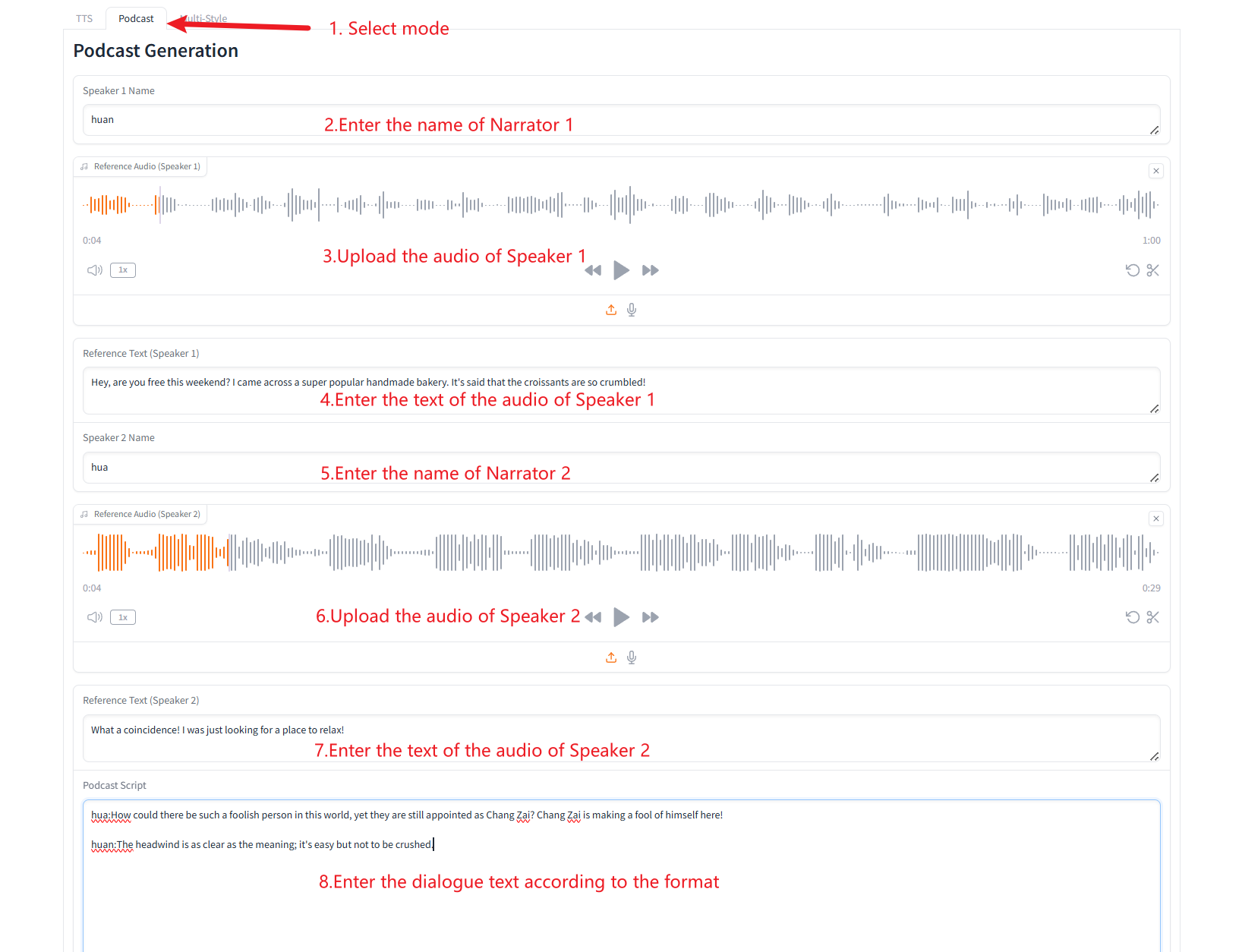
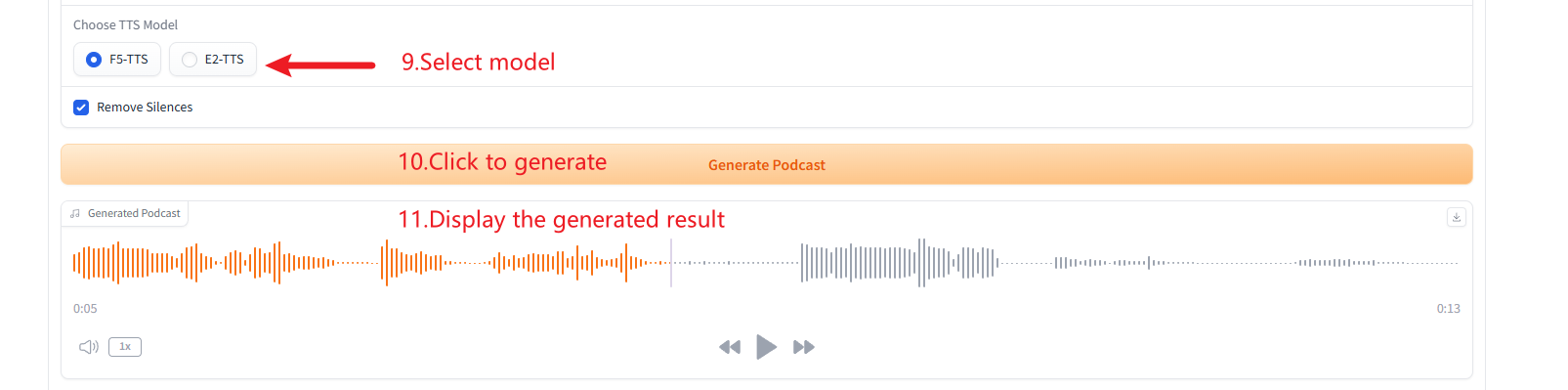
3. Multiple Speech-Type Generation
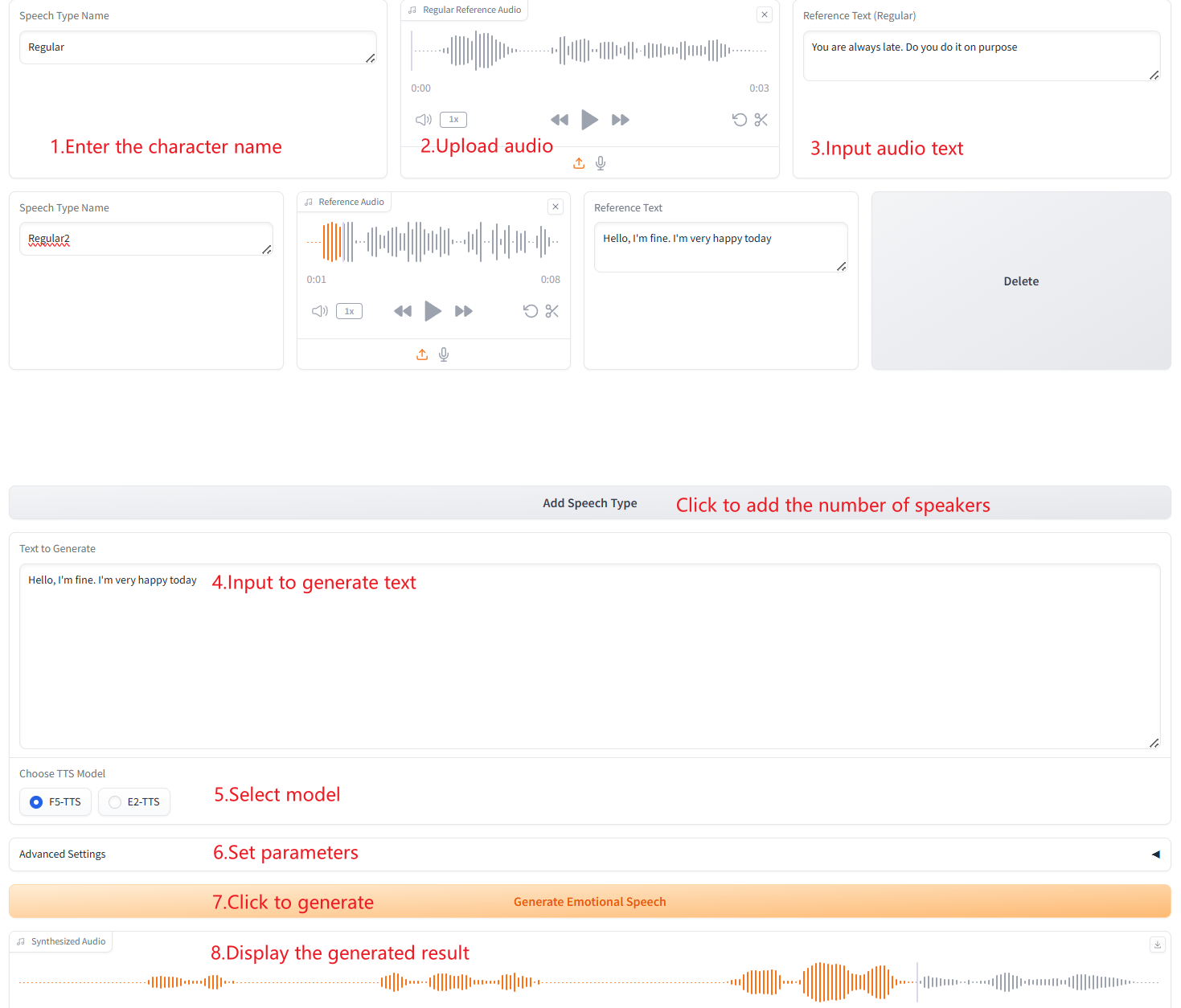
Citation Information
@article{chen-etal-2024-f5tts,
title={F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching},
author={Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen},
journal={arXiv preprint arXiv:2410.06885},
year={2024},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.