Command Palette
Search for a command to run...
Fish Speech v1.4 Voice Cloning-Text to Speech Tool Demo
Tutorial Introduction

Fish Speech's main features include text-to-speech, multi-language support, voice customization, high-quality sound library, and free open source. It is suitable for a variety of scenarios, such as content creation, education, customer service, auxiliary tools, etc. The model also provides support for API integration and model fine-tuning, allowing users to customize and optimize according to their needs.
The latest version 1.4 has made significant breakthroughs in multi-language support and performance, and the amount of training data has doubled to 700,000 hours., supports 8 major languages, including English, Chinese, German, Japanese, French, Spanish, Korean and Arabic. The new version also introduces instant voice cloning, allowing users to quickly copy a specific voice style, and provides flexible deployment options and API services.
This tutorial has deployed the model and environment. You can directly perform voice cloning or text-to-speech tasks according to the tutorial instructions.
How to run
1. 首先克隆容器, 按步骤启动容器
2. 复制生成的 API 地址到浏览器即可使用
3. 该教程主要包含 2 个功能:文本转语音和声音克隆
3.1 文本转语音:在「Input Text」输入生成的文本,点击「Generate」即可生成结果

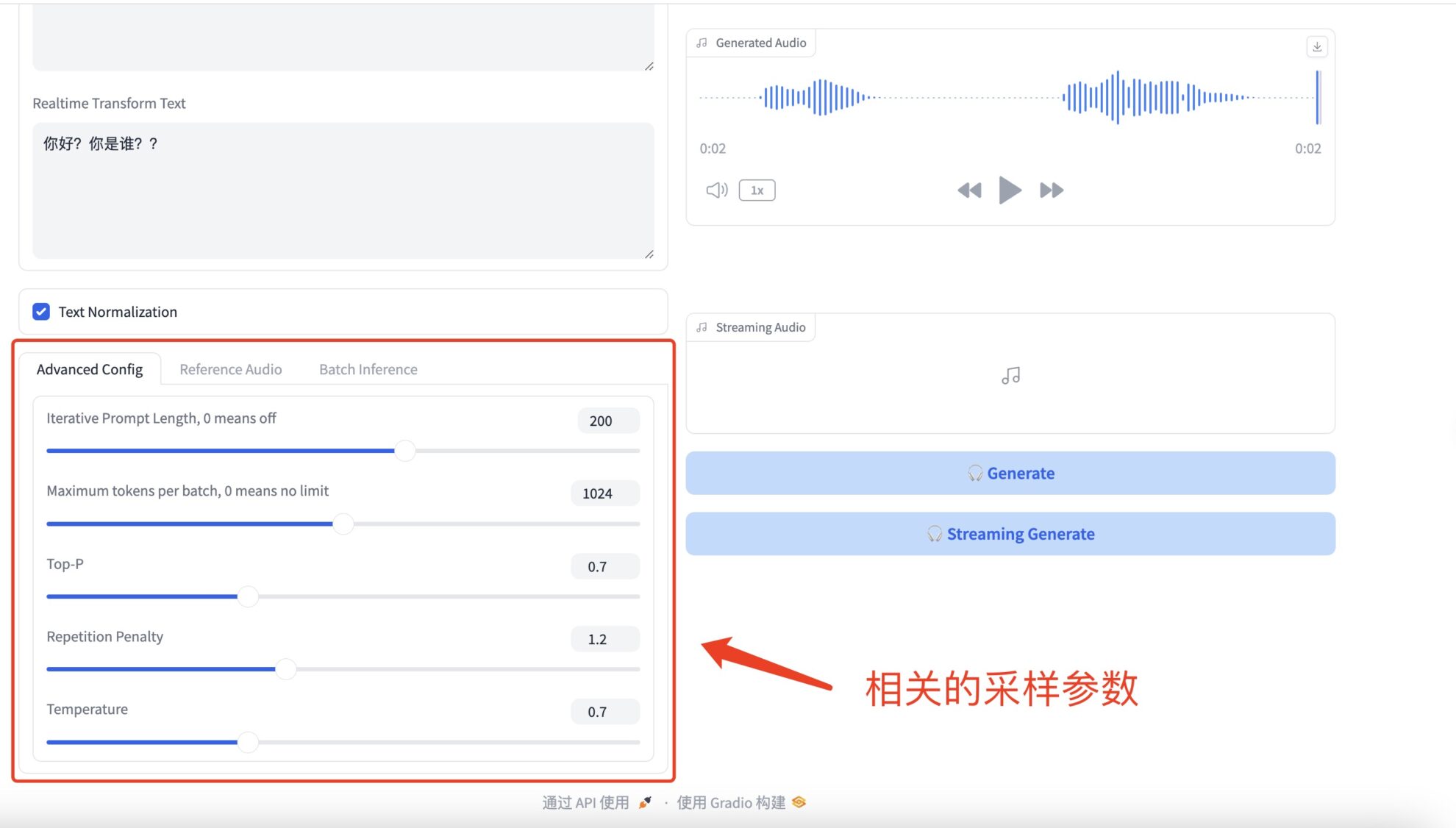
* Advanced Configs
相关的采样参数具体如下:
- Iterative Prompt Length: refers to the length of previous text that the model will consider when generating text. If set to a non-zero value, the model will consider the specified number of recent words or tokens as context at each step. If set to 0, this feature is turned off and the model may consider all available context or determine the context length based on other parameters (such as model window size).
- Maximum tokens per batch limits the maximum number of tokens that the model can generate in each batch. Tokens usually refer to words, punctuation marks, etc. If set to 0, there is no limit, and the model will generate text of any length as needed, or until the model's internal maximum length limit is reached.
- Top-P (also known as kernel sampling or probability sampling) is a text generation strategy where the model only considers the smallest set of words with a cumulative probability greater than P when generating each new word. This means that the model will randomly select the next word from this set, increasing the diversity of the generated text while avoiding the generation of irrelevant words with low probability.
- Repetition Penalty is used to reduce repetition in generated text. When the model tends to repeat generated words or phrases, applying this parameter can reduce the probability of selecting these words. The specific approach is to adjust (usually reduce) the probability score of the generated words to encourage the model to choose different words.
- Temperature controls the randomness of the generated text.
3.2 声音克隆:选择「Reference Audio」并点击「Enable Reference Audio」,
上传「Reference Audio(参考音频)」,以及「Reference Text(参考文本)」,在「Input Text」输入生成的文本,点击「Generate」即可生成声音克隆结果

4. 其他参数说明
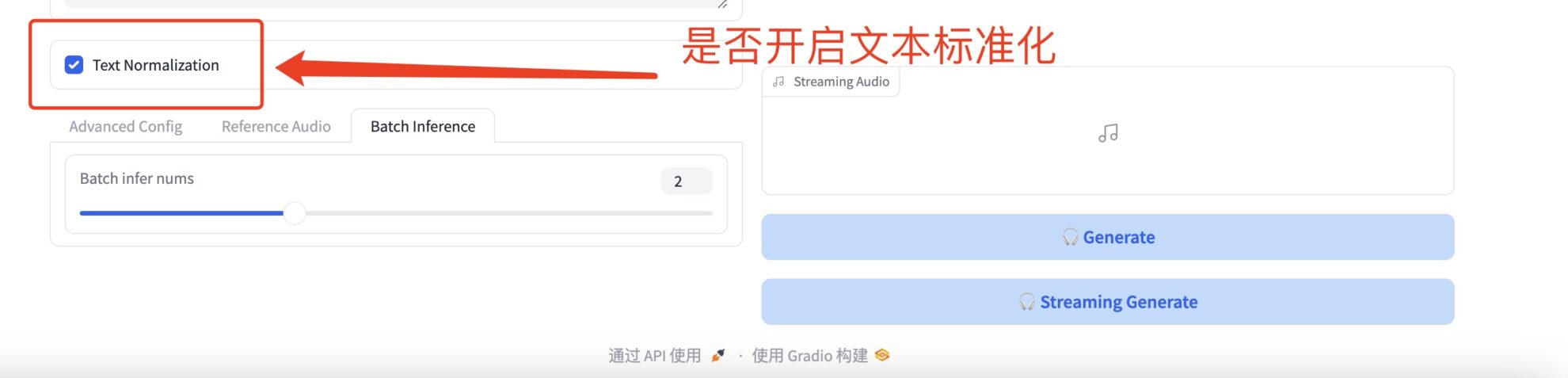
* Text Normalization
是否开启文本标准化(例如日期、固话、金钱等等)
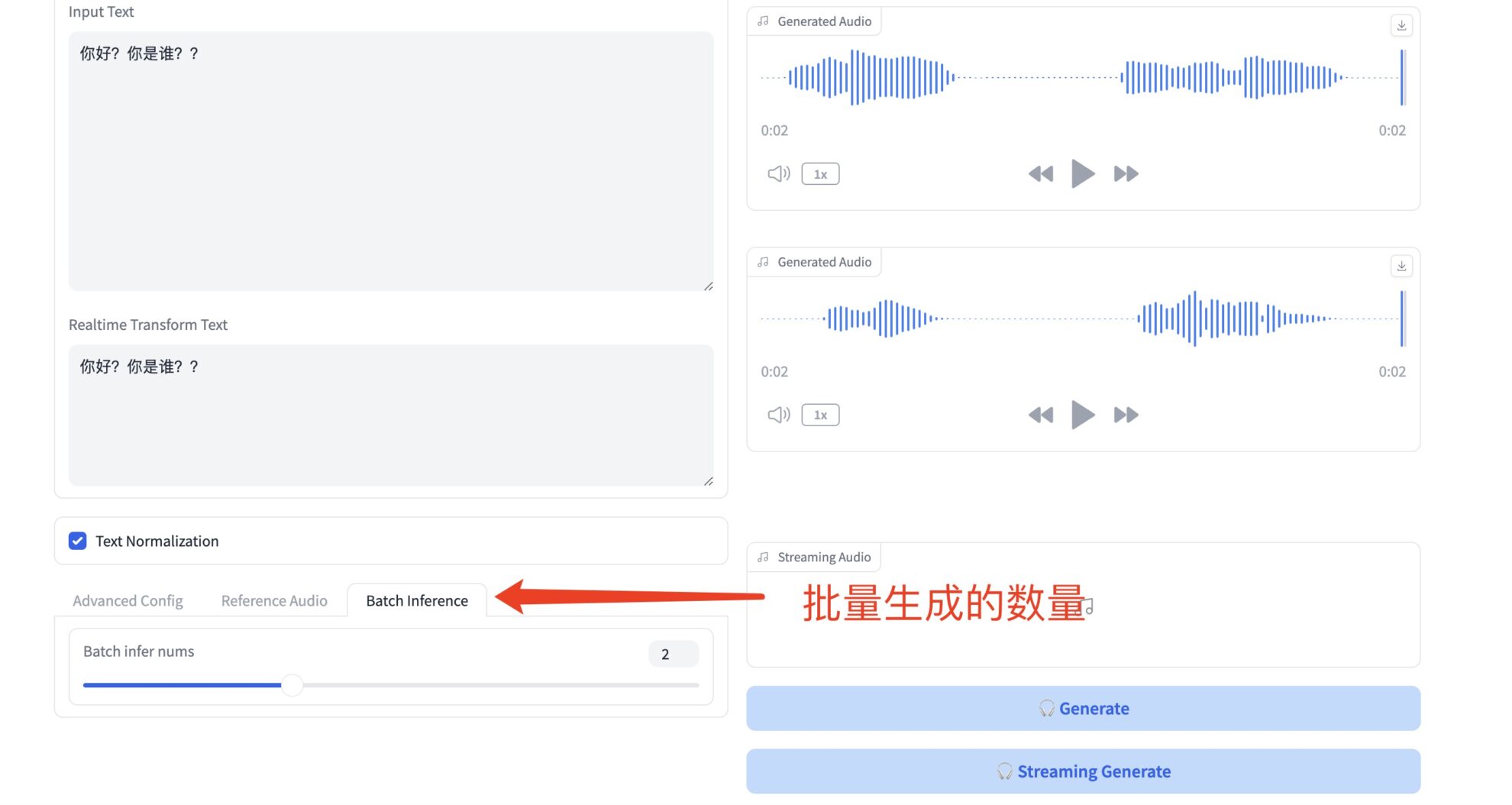
* Batch Inference
设置生成语音数量
Exchange and discussion
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.