Command Palette
Search for a command to run...
MinerU One-stop Data Extraction Tool
Model Introduction

MinerU is a tool that converts PDF to machine-readable formats (such as markdown, json), which can be easily extracted to any format. It supports accurate recognition of 176 languages and precise language type identification. It is specially designed to convert complex multimodal PDF documents containing images, formulas, tables, footnotes, etc. into clear and easy-to-analyze Markdown format. In addition, MinerU also supports fast parsing and extraction of formal content from web pages and e-books containing interference information such as advertisements, thereby effectively improving the efficiency of AI corpus preparation.
Key Features
- Delete elements such as headers, footers, footnotes, page numbers, etc. to maintain semantic coherence
- Output text in human-readable order for multiple columns
- Preserve the original document structure, including titles, paragraphs, lists, etc.
- Extract images, picture titles, tables, table titles
- Automatically recognize formulas in documents and convert them into latex
- Automatically recognize tables in documents and convert them into latex
- Automatically detect and enable OCR for garbled PDF
- Supports CPU and GPU environments
- Support windows/linux/mac platforms
Deploy the inference step
This tutorial has deployed the model and environment. You can directly use the large model for reasoning dialogue according to the tutorial instructions. The specific tutorial is as follows:
1. Model configuration
After the resources are configured, start the container and click the link at the API address to enter the Demo interface.
2. Open the interface
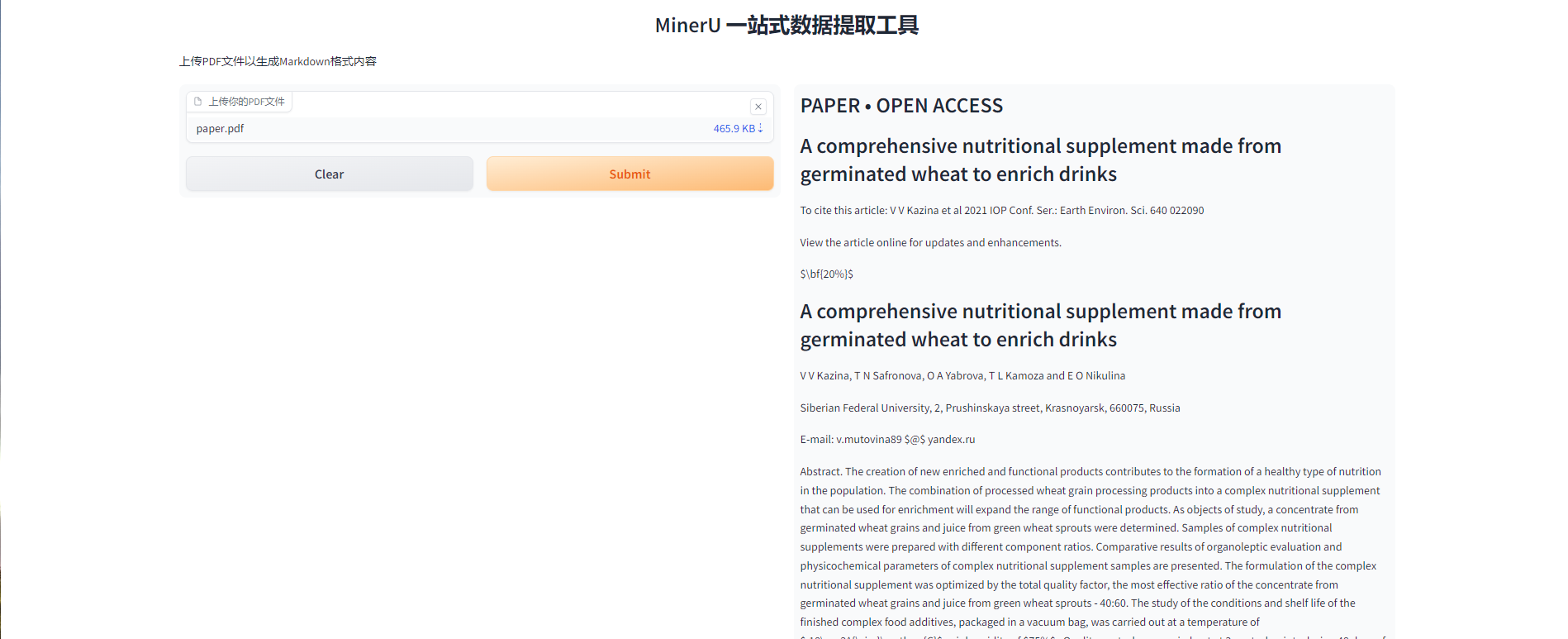
After a while, you can see the model interface, and now we can use the model. Users can upload the PDF file to be extracted (note that it should not be larger than 5 mb), click the submit button, and the model can start extracting. A sample file paper.pdf is also provided in the gradio interface for users to experience the model. (The extraction time of this file is about 110s)
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.