Command Palette
Search for a command to run...
MuseV Unlimited Length Virtual Human Video Generation Demo

Project Introduction
MuseV It is a virtual human video generation framework open sourced by Tencent Music Entertainment's Tianqin Lab in March 2024, focusing on generating high-quality virtual human videos and lip sync. It uses advanced algorithms to produce long video content with high consistency and natural expressions. It can be used with the already released MuseTalk Used in combination, a complete "virtual human solution" can be constructed.
The model has the following features:
- It supports the use of a novel visual conditional parallel denoising scheme for infinite length generation without the problem of error accumulation, which is especially suitable for scenes with fixed camera positions.
- A pre-trained model for virtual human video generation based on a character type dataset is provided.
- Supports image-to-video, text-to-image-to-video, and video-to-video generation.
- compatible
Stable DiffusionThe text and image generation ecosystem includesbase_model,lora,controlnetwait. - Supports multiple reference image techniques, including
IPAdapter,ReferenceOnly,ReferenceNet,IPAdapterFaceID.
Effect display
All frames that generate the results are directly generated by MuseV Generated without any post-processing such as temporal super-resolution or spatial super-resolution.
All the following test cases can be implemented in this tutorial. It takes about 2 and a half minutes to generate a 7-second video. The longest video tested is 20 seconds long and takes 8 minutes.
Character effect display
| image | video | prompt |
 | (masterpiece, best quality, highres:1), peaceful beautiful sea scene | |
 | (masterpiece, best quality, highres:1), playing guitar | |
 | (masterpiece, best quality, highres:1), playing guitar |
Scene effect display
| image | video | prompt |
 | (masterpiece, best quality, highres:1), peaceful beautiful waterfall, an endless waterfall | |
 | (masterpiece, best quality, highres:1), peaceful beautiful sea scene |
Generate videos from existing videos
| image | video | prompt |
 | (masterpiece, best quality, highres:1), is dancing, animation |
Run steps
1. Find the "Clone" button in the upper right corner of this tutorial. After clicking "Clone", directly use the platform's default configuration to create a container. Wait for the container to be successfully executed and started, and then you will see the page shown in the figure below. Follow the prompts in the figure to enter the project's operation interface.
❗Note❗ Since the model is large, it may take about 1 minute to wait for the model to load before opening the API address after the container is successfully started.
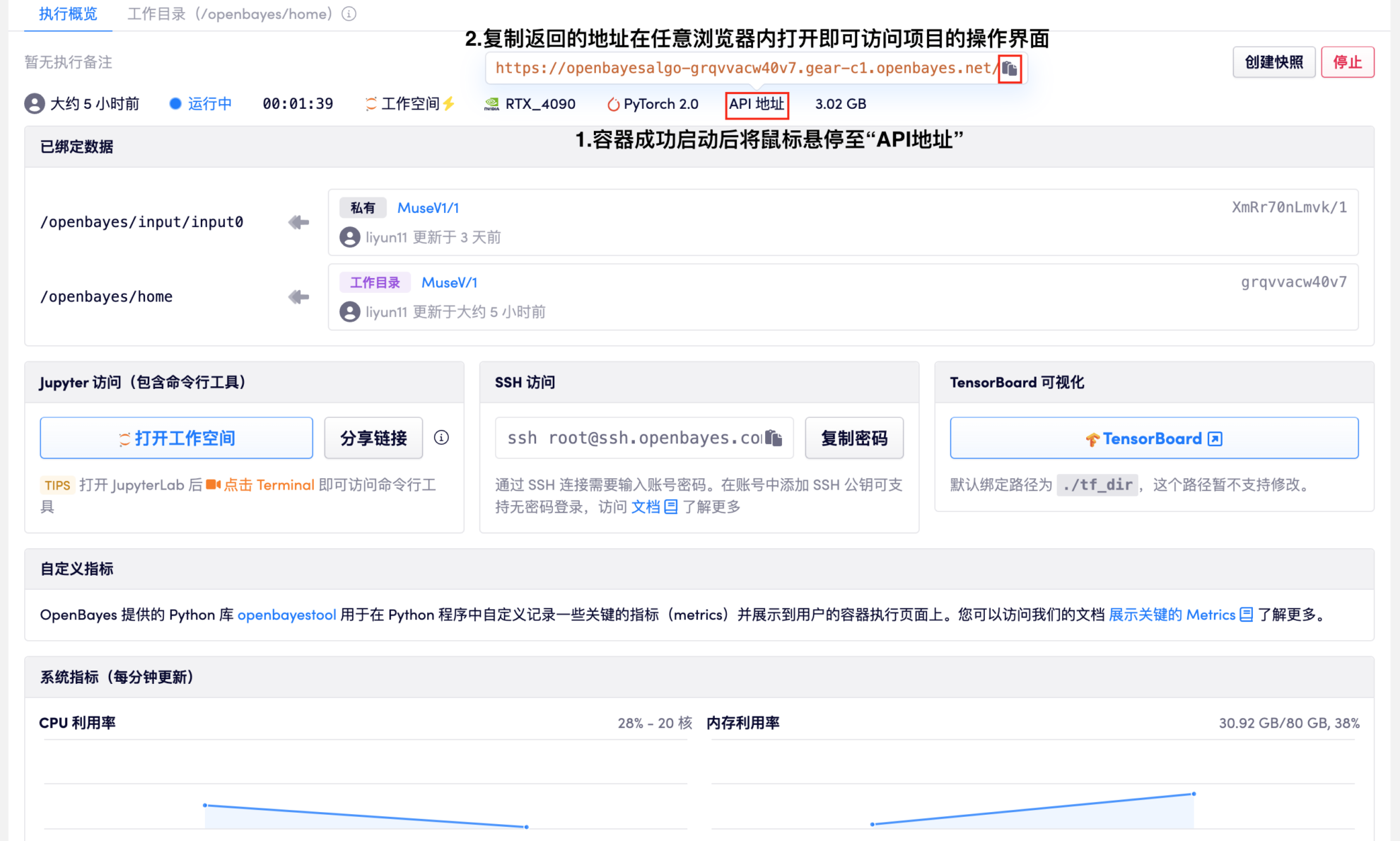
2. The usage of the page is explained as follows:

Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.