Command Palette
Search for a command to run...
FLUX.1-schnell Vincent Figure Demo
Date


Tutorial Introduction
FLUX.1 is a large model with 12 billion parameters that can generate images from text descriptions. It defines a new state-of-the-art level of image detail, timeliness, style diversity, and scene complexity for text-to-image synthesis. This tutorial uses the FLUX.1 [schnell] version model. The model and environment are deployed, and you can directly use the large model for reasoning dialogue according to the tutorial instructions.
Since the model is large, it needs to be run using A6000 and cannot be started using a single 4090 card.
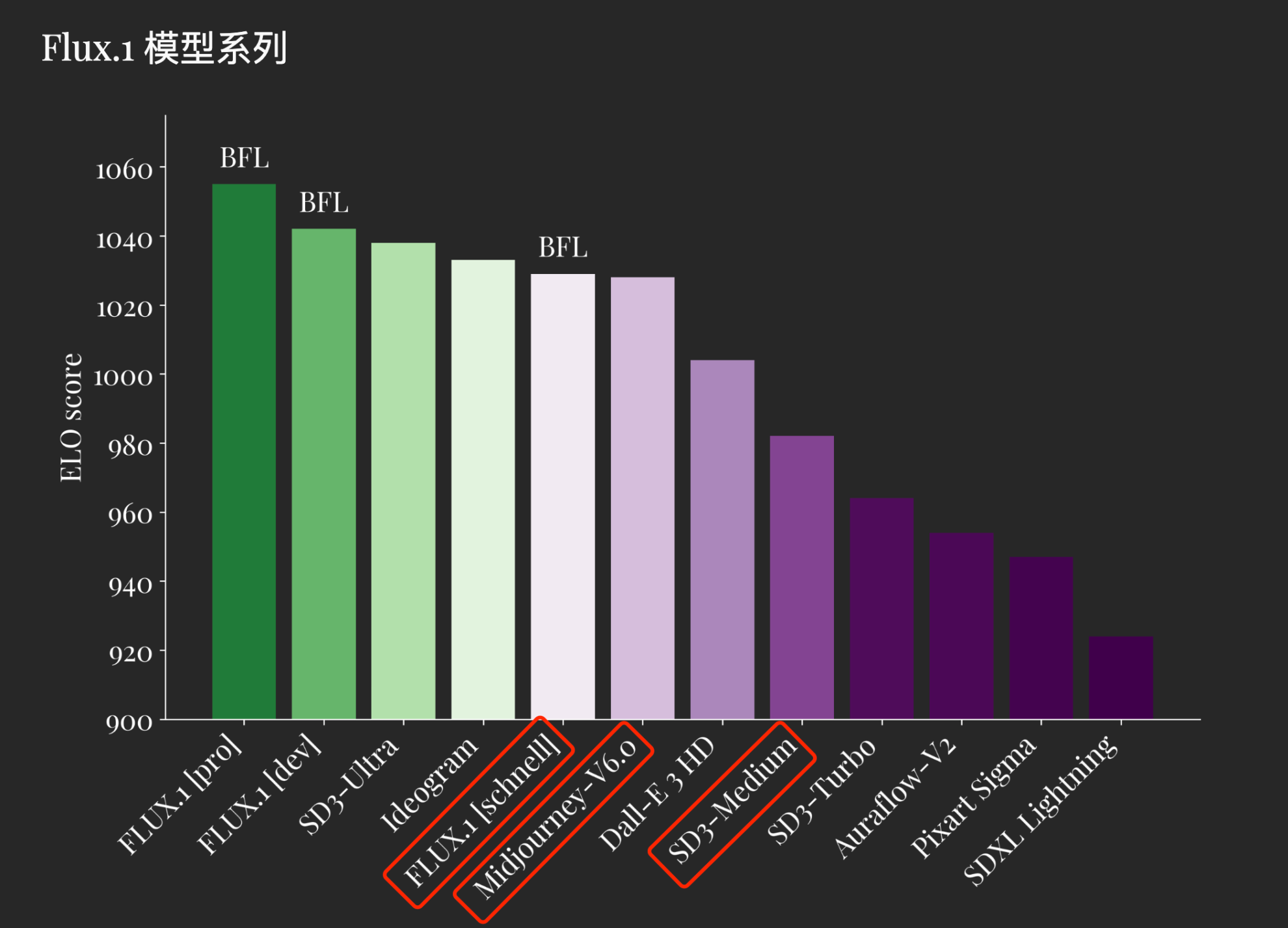
FLUX.1 defines the state of the art in image synthesis. FLUX.1 [pro] and [dev] surpass popular models such as Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra in every aspect: visual quality, fast follow-up, scale/aspect variation, typography, and output diversity. FLUX.1 [schnell] is the most advanced few-step model to date, outperforming not only its competitors but also strong non-distilled models such as Midjourney v6.0 and DALL·E 3 (HD).
To strike a balance between accessibility and model functionality, FLUX.1 is available in three versions: FLUX.1 [pro] , FLUX.1 [dev] , and FLUX.1 [schnell] :
FLUX.1 [pro]: The best features of FLUX.1, providing state-of-the-art performance image generation with top-notch live tracking, visual quality, image detail, and output diversity. Not for commercial use, you need to contact the research team for use. FLUX.1 [dev]: FLUX.1 [dev] is an open-weight, guided distillation model suitable for non-commercial applications. FLUX.1 [dev] is directly distilled from FLUX.1 [pro], with similar quality and live adherence, while being more efficient than standard models of the same size. FLUX.1 [dev] weights can be used on HuggingFace and can be tried directly on Replicate or Fal.ai. Not for commercial use. FLUX.1 [schnell]: This model is tailored for local development and personal use. FLUX.1 [schnell] is publicly available under the Apache 2.0 license.
Key Features
- Cutting-edge output quality and competitive tip-to-tip following, matching the performance of closed-source alternatives.
- Trained using latent adversarial diffusion distillation, FLUX.1 [schnell] can generate high-quality images in just 1 to 4 steps.
- This model is released under the Apache-2.0 license and can be used for personal, scientific and commercial purposes.
Comparison with other Wenshengtu model scores
Deploy the inference step
This tutorial has deployed the model and environment. You can directly use the large model for reasoning dialogue according to the tutorial instructions. The specific tutorial is as follows:
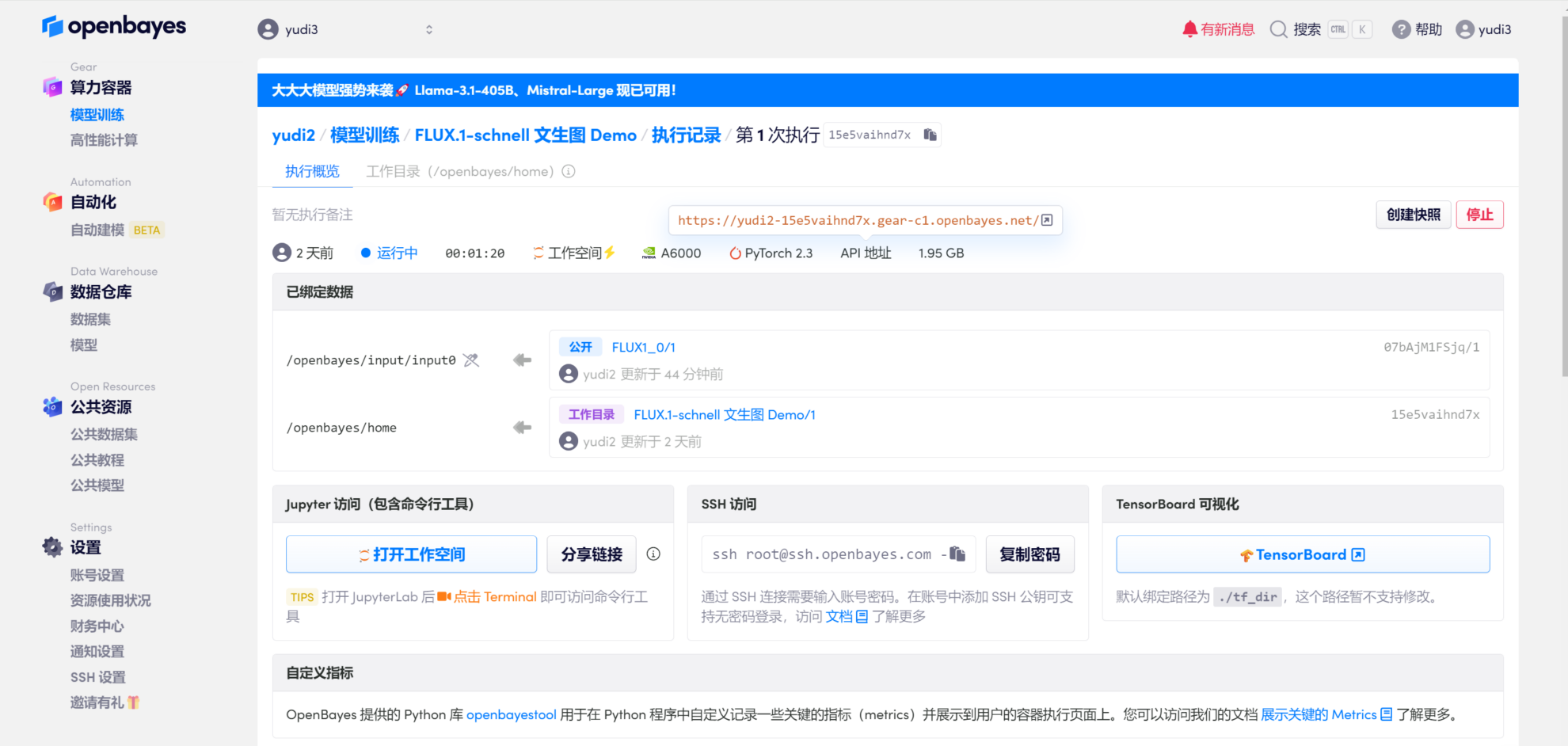
1. Open the interface
Click "Clone" in the upper right corner of the page to clone and start the container. After the resources are configured, start the container and directly click the link at the API address to enter the demo interface.
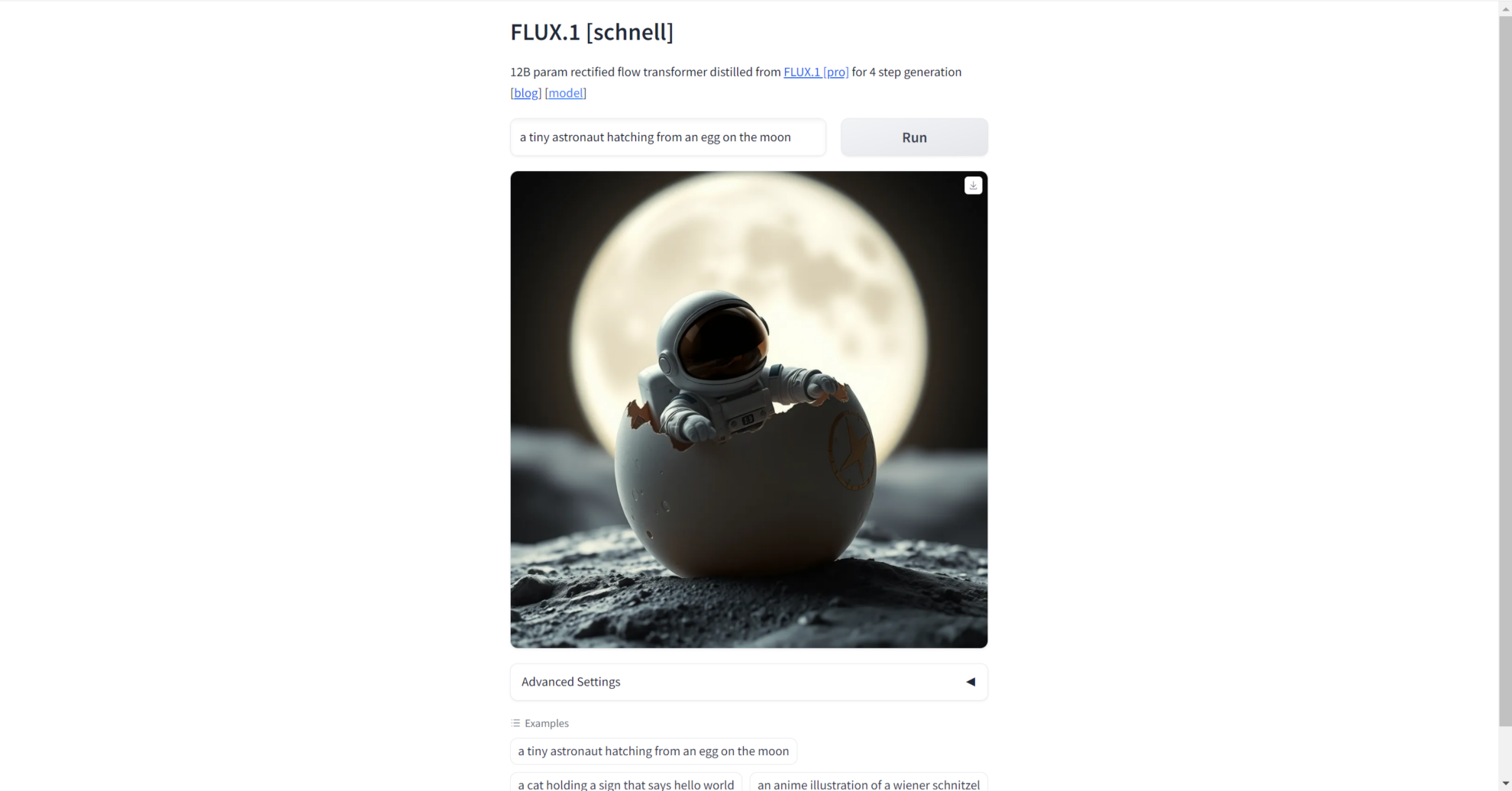
2. Enter the prompt word
After opening the interface, we can enter the prompt word we want to generate the image, and the corresponding high-quality image will be generated. We can also use the examples in the sample to verify.
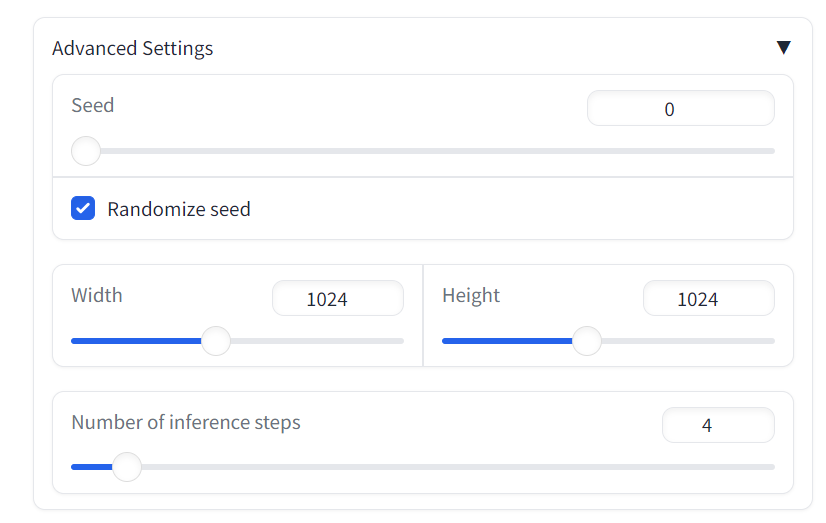
3. Change parameters
There are also multiple parameters in the model that can be adjusted by the user. We can adjust the number of inference steps of the model, the length and width of the generated image, and other parameters.
Discussion and Exchange
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [Tutorial Exchange] to join the group to discuss various technical issues and share application effects↓ 
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.