Command Palette
Search for a command to run...
Paints-Undo: Demo of the Whole Process of Generating a Painting From One Picture
Tutorial Introduction

This tutorial is a one-click run demo of PaintsUndo. The relevant environment and dependencies have been installed. You can experience it by cloning and starting it with one click.
PaintsUndo is a basic model that can simulate human painting behavior. It aims to provide humans with a basic model of painting behavior, and at the same time hopes that future AI models will better meet the real needs of human artists. The project provides a series of models that take an image as input and then output a drawing sequence of the image. The model simulates human behavior in the drawing process, including but not limited to sketching, inking, shading, shading, transformation, left-right flipping, color curve adjustment, changing the visibility of layers, and even changing the overall conception during the drawing process. The name "Paints-Undo" is inspired by the similarity that the output of the model looks like pressing the "Undo" button (usually Ctrl+Z) multiple times in AI painting software.
The project currently releases two models: a single-frame model and a multi-frame model.
- paints_undo_single_frame
- paints_undo_multi_frame
The single-frame model takes an image and a as input and outputs an image.
- Assume that an artwork can always be created by manually drawing 1000 times, and the order of the drawings is an integer from 0 to 999. The order represented by 0 is the final artwork completed, and 999 is the first brushstroke drawn on a pure white canvas. This model can be thought of as the "undo" (or Ctrl+Z) model.
- Enter the final image and indicate the number of times you want to "Ctrl+Z". After pressing these "Ctrl+Z", the model will generate a screenshot of the corresponding number of painting processes. If the number of times selected is 100, it means that you want to simulate "Ctrl+Z" 100 times on this image to obtain a screenshot after 100 "Ctrl+Z".
The multi-frame model takes two images as input and outputs 16 intermediate frames between the two input images.
- Compared to the single-frame model, the difference between the two images is smaller, but the speed is also much slower and less random.
- The image generation is limited to 16 frames.
In the generation method of this project, the default method is to use them together. First, use the single-frame model to infer about 5-7 times to obtain 5-7 "key frames", and then use the multi-frame model to "interpolate" these key frames to actually generate a relatively long video. In the end, generally about 100 intermediate images can be obtained.
Theoretically, the system can be used in a variety of ways, even to provide infinitely long videos, but in practice it currently works best when the final frame count is around 100-500.
This tutorial uses a single RTX 5090 card as the resource.
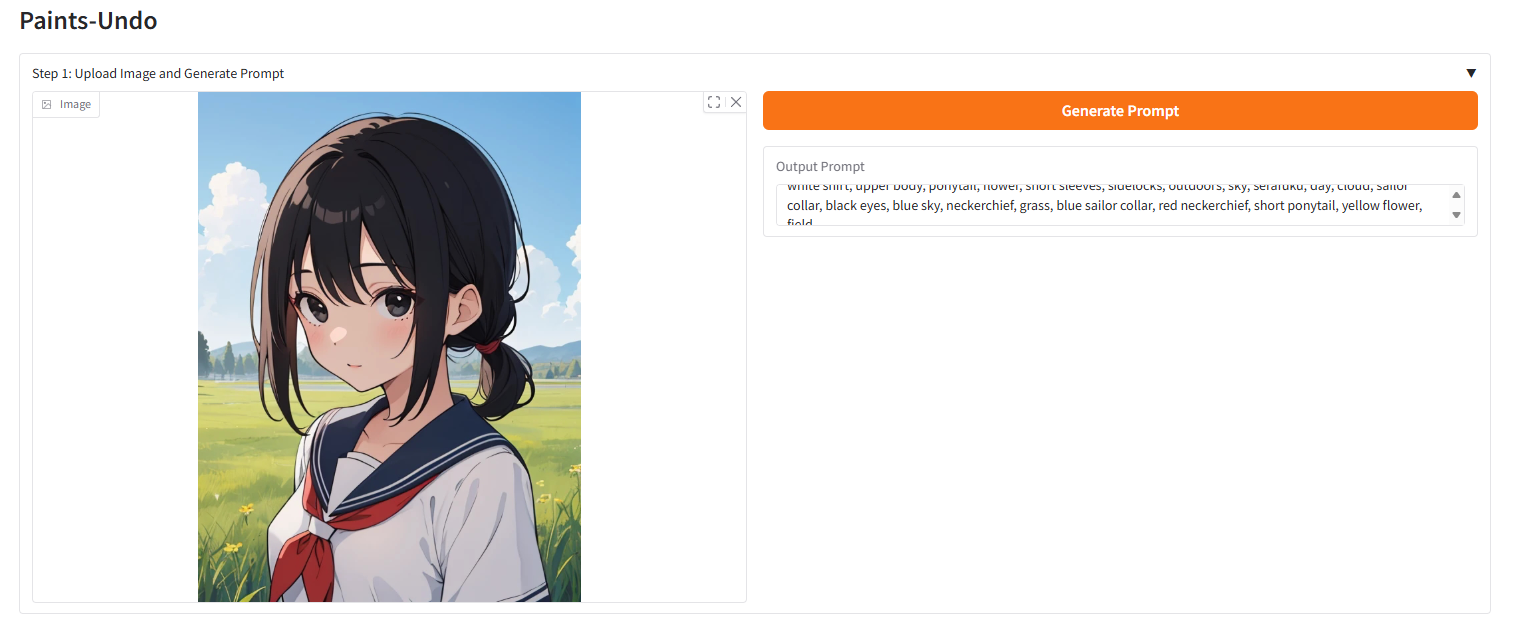
Effect display
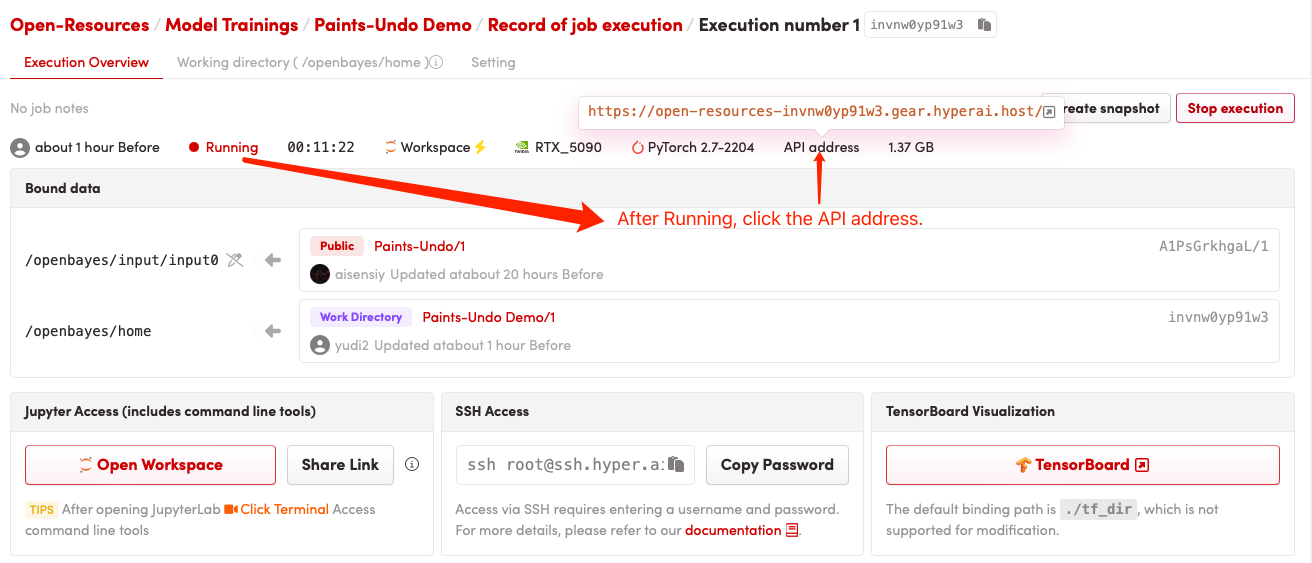
Running method (it takes about 10 seconds to initialize after starting the container, and then perform the following operations)
1. After cloning and starting the container, copy the API to your browser
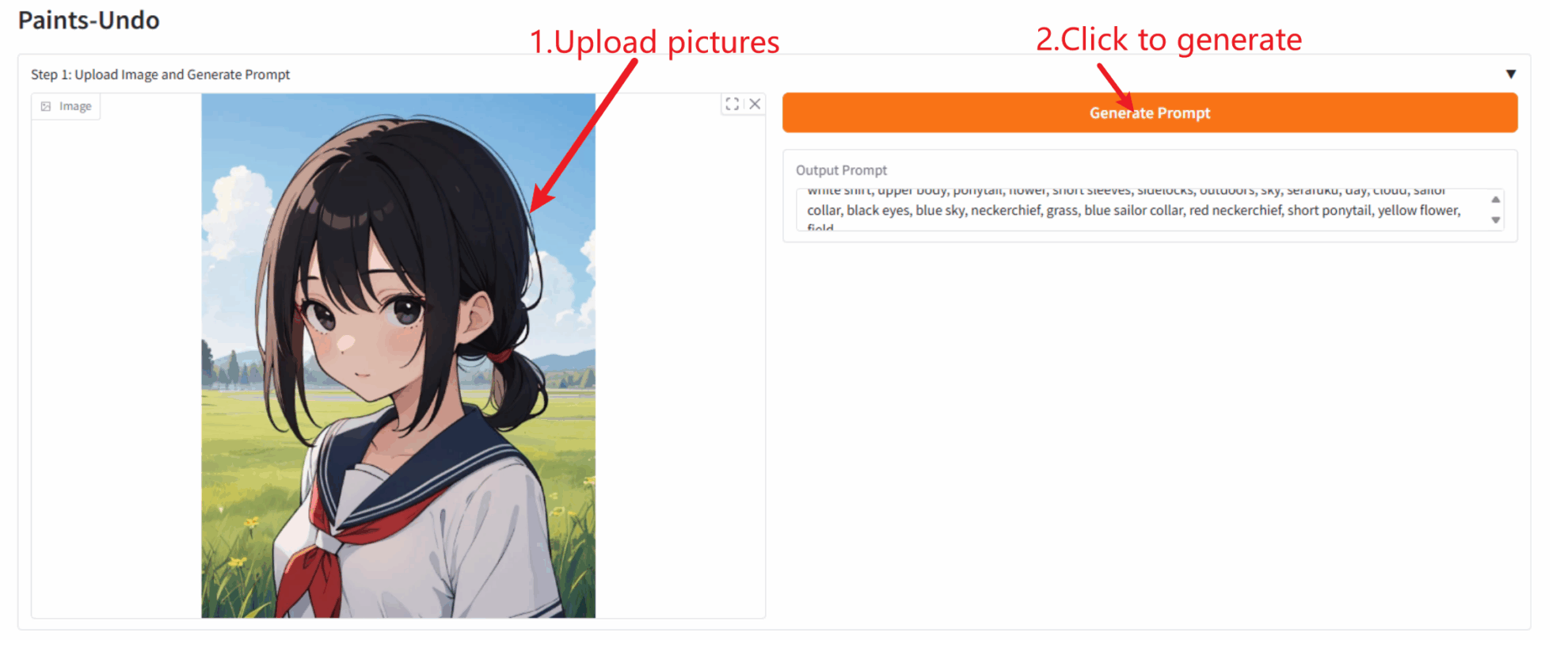
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
Single frame model output
Total model output
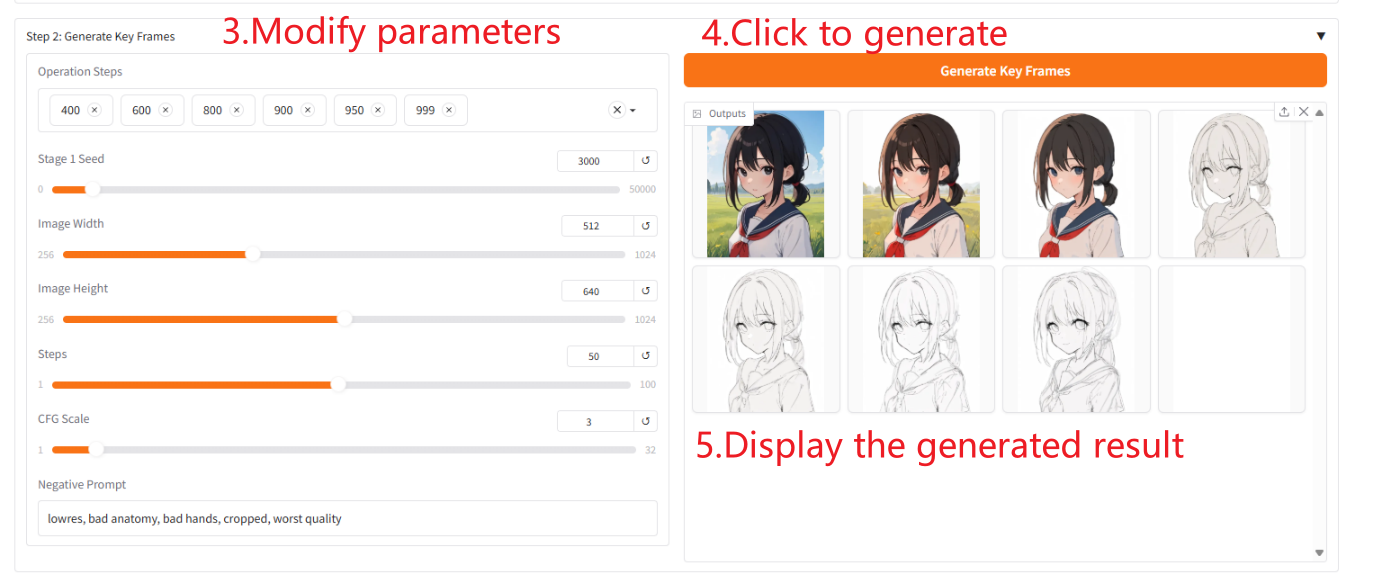
Parameter Description
- "Operation Steps": You can select the order of key frames to output. The larger the order you select, the more similar the generated image will be to the original image.
- 「Stage 1 Seed」: You can randomly select a seed for keyframe generation.
- "Steps": You can select the number of steps the model runs per frame.
- 「CFG Scale」: You can control the randomness of the generated image. The smaller the value, the higher the randomness of the generated image.
- 「Nagative Prompt」: Fill in negative words to alleviate the situation where the generated images contain these negative words.
Generate Video
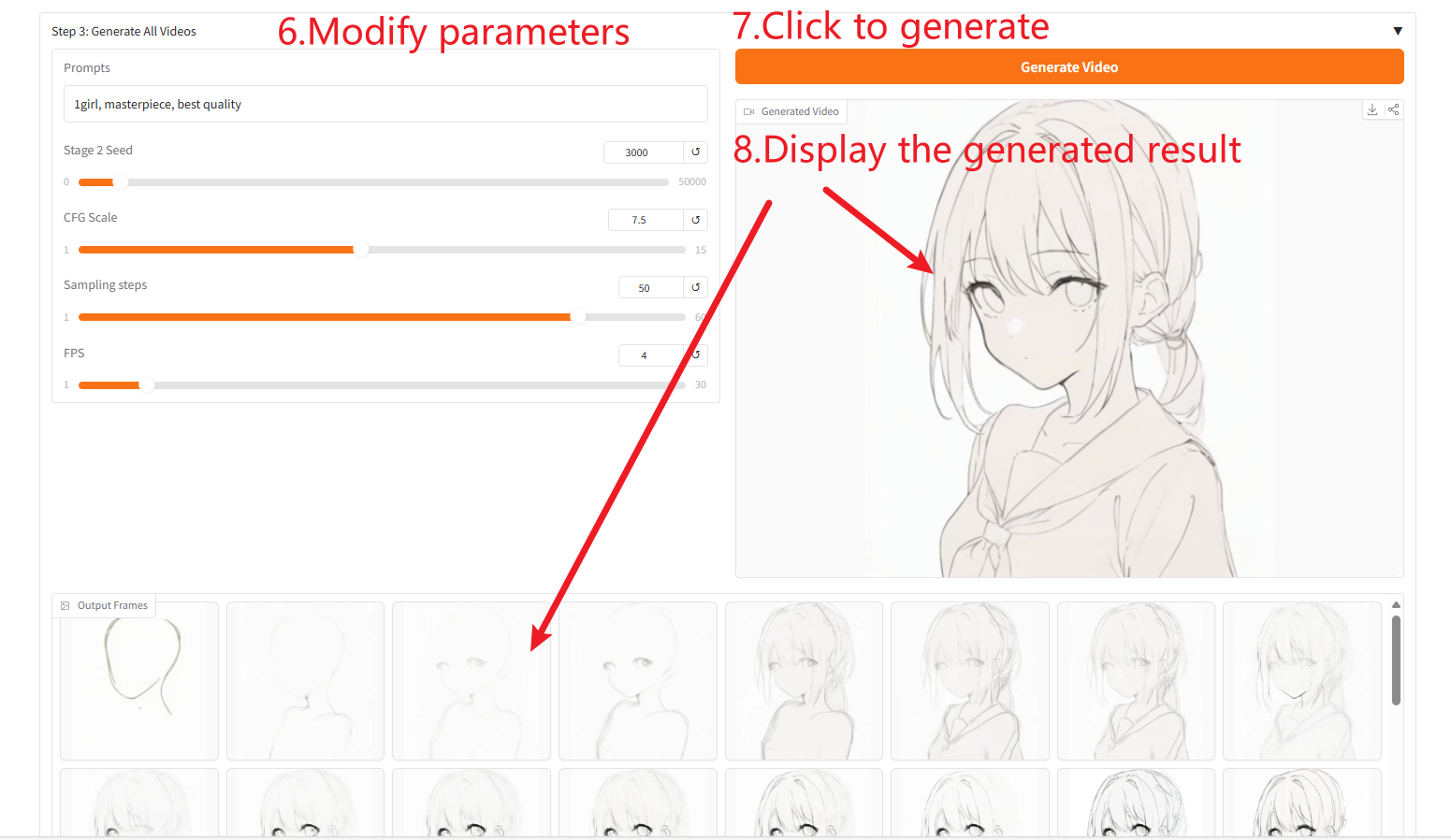
Parameter Description
- 「Prompts」: Fill in positive prompts to improve the quality and content of generated images.
- 「Stage 2 Seed」: You can randomly select seeds for image generation.
- 「CFG Scale」: You can control the randomness of the generated image. The smaller the value, the higher the randomness of the generated image.
- "Sampling steps": You can change the number of iterations of sampling. The larger the value, the more accurate the generated image.
- 「FPS」: You can change the frame rate of the generated video. The default is 4 frames, which means that the video contains four generated images per second.
Citation Information
The citation information for this project is as follows:
@Misc{paintsundo,
author = {Paints-Undo Team},
title = {Paints-Undo GitHub Page},
year = {2024},
}
@article{paintsalter,
author = {Zhang, Lvmin and Yan, Chuan and Guo, Yuwei and Xing, Jinbo and Agrawala, Maneesh},
title = {Generating Past and Future in Digital Painting Processes},
journal = {ACM Transactions on Graphics (SIGGRAPH 2025)},
year = {2025},
volume = {44},
number = {4},
articleno = {127},
numpages = {13},
}Notebook Overview
Level
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.