Command Palette
Search for a command to run...
Quantizing Vision Transformers (Vit) for Efficient Deployment: Strategies and Best Practices
This tutorial recommends using pytorch version 2.0 and a single 4090 GPU. For ease of use, the models used have been downloaded into the tutorial. Please run them one by one.
1. Introduction
As the demand for advanced computer vision systems continues to surge across industries, the deployment of vision transformers has become a focus for researchers and practitioners. However, to fully realize the potential of these models, a deep understanding of their architecture is required. In addition, developing optimization strategies to effectively deploy these models is equally important.
This article aims to provide an overview of the Vision Transformer, fully exploring its architecture, key components, and the fundamentals that make them unique. At the end of the article, we will discuss some optimization strategies with code demonstrations to make the model more compact for easier deployment.
2. Overview of Vit
ViT is a special type of neural network that is mainly used for image classification and object detection. The accuracy of ViT has surpassed traditional CNNs, and the key factor that contributed to this is that they are based on the Transformer architecture. Now what is this architecture?
In 2017, Vaswani et al. "Attention is all you need"The Transformer neural network architecture was introduced in . This network uses an encoder and decoder structure very similar to a recurrent neural network (RNN). In this model, there is no concept of timestamps in the input; all words are passed at the same time and their word embeddings are determined at the same time.
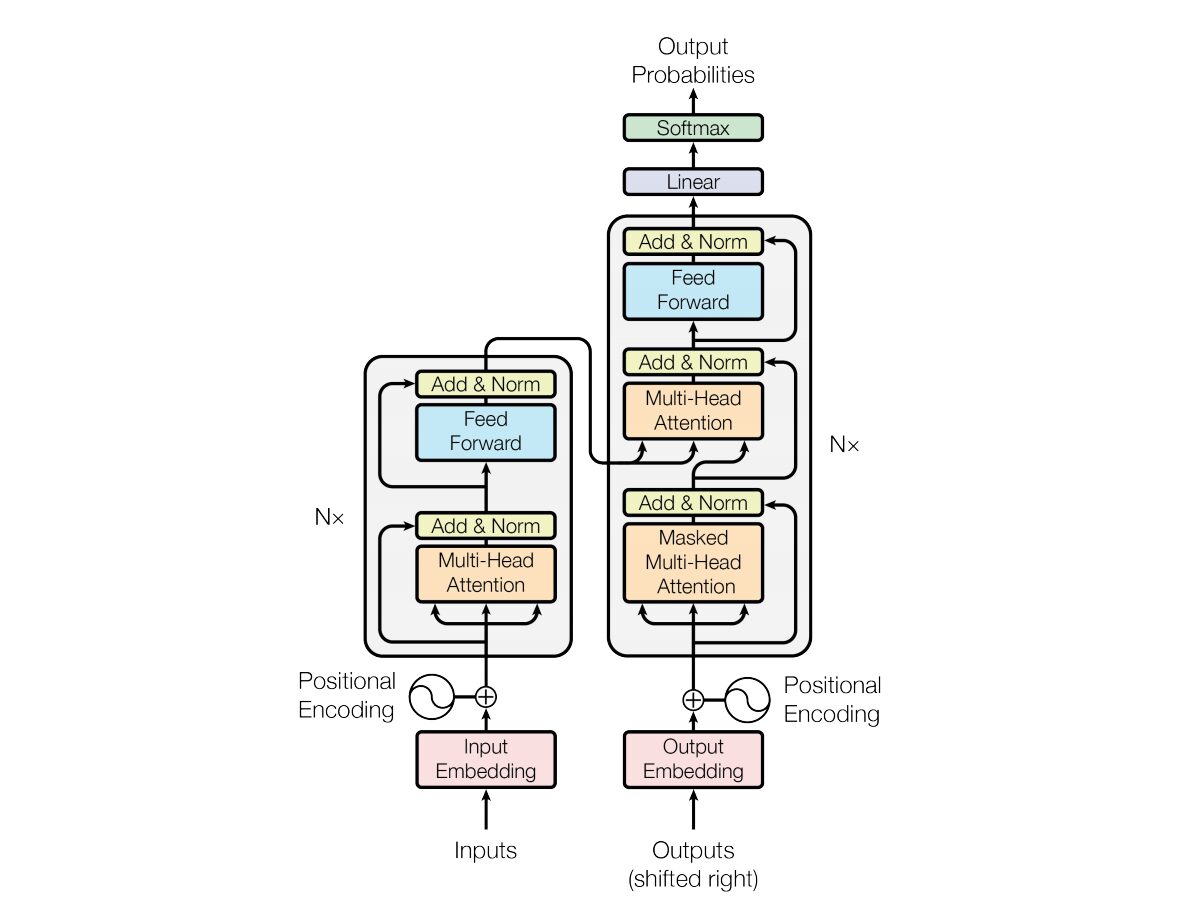
This type of neural network architecture relies on a mechanism called self-attention.
Here is a high-level explanation of the key components of the Transformer architecture:
- Input Embedding: Input embedding is the first step in passing the input to the transformer. Input embedding refers to the process of converting the input tokens or words into a fixed-size vector that can be fed into the model. This embedding step is crucial as it converts the discrete token representation into a continuous vector representation in a way that captures the semantic relationship between words. This embedding step maps a word to a vector, but the same word can have different meanings in different sentences. This is where positional encoders come in.
- Positional encoding: Since Transformer itself does not understand the order of elements in a sequence, positional encoding is added to the input embedding to provide the model with information about the position of the element in the sequence. In short, positional embedding gives a vector that is contextually based on the position of the word in the sentence. The original paper used sine and cosine functions to generate this vector. This information is passed to the encoder block.
- Encoder-Decoder Structure: Transformer is mainly used for sequence-to-sequence tasks, such as machine translation. It consists of an encoder and a decoder. The encoder processes the input sequence and the decoder generates the output sequence.
- Multi-head self-attention: Self-attention allows the model to weight different parts of the input sequence differently when making predictions. The key innovation of the Transformer is the use of multiple attention heads, which enables the model to focus on different aspects of the input simultaneously. Each attention head is trained to focus on different patterns.
- Scaled Dot Product Attention: The attention mechanism computes a set of attention scores by taking the dot product of the input sequence with a learnable weight vector. These scores are scaled and passed through a softmax function to obtain the attention weights. The weighted sum of the input sequence using these attention weights is the output of the attention mechanism.
- Feedforward Neural Network: After the attention layer, each encoder and decoder block usually includes a feedforward neural network with an activation function (such as ReLu). This network is applied independently to each position in the sequence.
- Layer Normalization and Residual Connections: Layer normalization and residual connections are used to stabilize training. Each sub-layer (attention or feed-forward) in the encoder and decoder has layer normalization, and the output of each sub-layer is passed through a residual connection.
- Encoder and Decoder Stack: The encoder and decoder consist of multiple identical layers stacked on top of each other. The number of layers is a hyperparameter.
- Masked Self-Attention in Decoder: During training, in the decoder, the self-attention mechanism is modified to prevent paying attention to future tokens. This is done using a masking technique to ensure that each position can only process the positions that precede it.
- Final Linear and Softmax Layers: The output of the decoder stack is transformed into final prediction probabilities (e.g., using a linear layer followed by a softmax activation) to produce the output sequence.
3. Understanding the Vision Transformer Architecture
CNNs are considered the best solution for image classification tasks. ViT consistently beats CNNs on such tasks if the pre-trained dataset is large enough. ViT has made significant achievements, successfully training Transformer encoders on ImageNet, showing impressive results compared to well-known convolutional architectures.
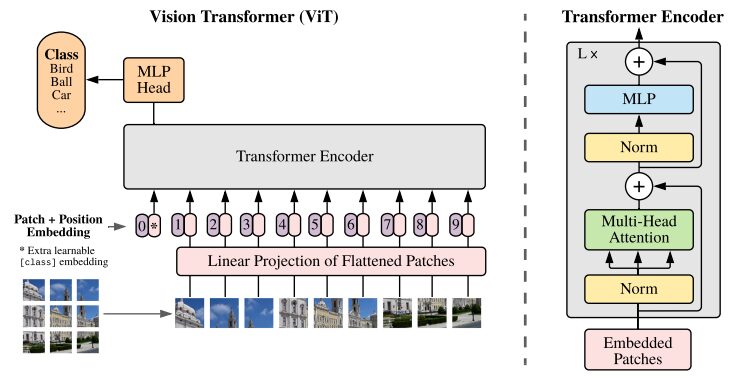
Illustration of the ViT architecture from the original research paper
Transformers models typically process images and words that are passed sequentially to an encoder-decoder. Here is a simplified overview of ViT:
- Patch Extraction: An image is fed to the Transformer encoder as a sequence of patches. A patch is a small rectangular portion of an image, typically 16×16 pixels in size.

- After dividing the image into non-overlapping blocks (usually a 16×16 grid), each block is converted into a vector representing its features. These features are usually extracted by utilizing a convolutional neural network (CNN), which is trained to identify important features necessary for image classification.
- Linear Embedding: These extracted patches are linearly embedded into flat vectors. These vectors are then treated as input sequences to the Transformer, also known as linear projections of the flattened patches.
- Transformer Encoder: The embedded patch vector is passed through a stack of Transformer encoder layers. Each encoder layer consists of a self-attention mechanism and a feed-forward neural network.
- Self-Attention Mechanism: The self-attention mechanism allows the model to capture the relationship between different patches in the image, enabling it to learn long-range dependencies and relations. The attention mechanism in the Transformer enables the model to capture both local and global contextual information, enabling it to effectively perform a variety of visual tasks.
- Position Encoding: Since the Transformer itself does not understand the spatial relationship between patches, position encoding is added to the input embedding to provide information about the location of the patch in the original image.
- Multiple Encoder Layers: ViT typically uses multiple Transformer encoder layers to capture hierarchical and abstract features from the input image.
- Global Average Pooling: The output of the Transformer encoder is usually subjected to global average pooling, which aggregates information from different patches into a fixed-size representation.
- Classification head: The merged representation is then fed into a classification head (usually consisting of one or more fully connected layers) to generate the final output for a specific computer vision task (e.g. image classification).
We strongly recommend that you view the originalResearch Papers, for a deeper understanding of the ViT architecture.
4. How to use
The following codes can all be accessed and executed in pre_ViT.ipynb! ! ! !
4.1 Classify images using the pre-trained ViT model
Pre-trained ViT models are pre-trained using the famous ImageNet-21k, a dataset with 14 million images and 21k categories, and fine-tuned on the ImageNet dataset with 1 million images and 1k categories.
Demo:
- The following two libraries will be missing when you start the platform for the first time. Use pip to install dependencies. Add the additional parameter --user when installing dependencies with pip. Then the installed dependencies will be saved in the container's workspace and will not be invalidated when you restart next time.
!pip install --user -q transformers timm- Import the necessary classes from the Transformer library. ViTFeatureExtractor is used to extract features from images and ViTForImageClassification is a pre-trained ViT model for image classification.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球Code breakdown:
- ViTFeatureExtractor.from_pretrained: Responsible for converting the input image into a format suitable for the ViT model.
- ViTForImageClassification.from_pretrained: Loads a pre-trained ViT model for image classification.
- feature_extractor: Processes the input image using the ViT feature extractor, converting it into a format suitable for the ViT model.
- model: The pre-trained model processes the input and generates output logits, which represent the model’s predictions for different classes. The next step is to find the index of the class with the highest Logit score. Create a variable to store the index of the predicted class.
- model.config.id2label[predicted_class_idx]: Maps predicted class indices to their corresponding labels.
4.2 Classifying images using DeiT
DeiT demonstrates the successful application of Transformers to computer vision tasks even with limited data availability and resources.
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())Code breakdown:
- Install Libraries: The first necessary step is to install the required libraries. We strongly recommend users to study these libraries for better understanding.
- Load pretrained model:: model=torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True) loads the pretrained DeiT model named 'deit_base_patch16_224' from the DeiT repository.
- Set the model to evaluation mode: model.eval(): Sets the model to evaluation mode, which is very important when using a pre-trained model for inference.
- Image Transformations: Defines a series of transformations to be applied to the image. For example, resizing, center cropping, converting the image to a PyTorch tensor, and normalizing the image using the mean and standard deviation values commonly used by ImageNet data. Download and transform the image: The next step involves downloading the image from the URL and transforming it. Adding the parameter [None,] adds an extra dimension to simulate a batch of size 1.
- Model Inference and Prediction: out = model(img) will allow the preprocessed image to be inferred through the DeiT model. clsidx = torch.argmax(out) will find the index of the class with the highest probability. Next, print the index of the predicted class.
4.3 Quantization Model
To reduce the model size, quantization is applied. This process reduces the size without affecting the accuracy of the model.
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")Code breakdown:
- torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
- qconfig_spec specifies that quantization should be applied only to linear (fully connected) layers. The quantization data type used is torch.qint8 (8-bit integer quantization).
4.4 Optimization Model
The optimize_for_mobile function optimizes it specifically for mobile deployment and saves the resulting optimized model to a file.
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())4.5 Lite version
This is important for deploying models on mobile or edge devices that support PyTorch Lite to ensure compatibility and efficiency of the runtime environment of such devices.
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 Comparison of Inference Speed
To compare the inference speed of different model variants, execute the provided code:
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
The above codes can all be accessed and executed in pre_ViT.ipynb! ! ! !
Conclusion and Thoughts
In this article, we covered everything to get started with the Vision Transformer and explore the model using the Paperspace console. We explored one of the important applications of the model: image recognition. For comparison and easier interpretation of ViT, we also included the Transformer architecture.
The Vision Transformer paper introduces a promising and simple model as an alternative to CNNs. After being pre-trained on ILSVRC's ImageNet and its superset ImageNet-21M, the model achieves state-of-the-art benchmarks on popular image classification datasets including Oxford-IIIT Pets, Oxford Flowers, and Google Brain's JFT-300M.
In summary, Vision Transformers (ViTs) and DeiT represent significant advances in computer vision. ViT, with its attention-based architecture, demonstrates the effectiveness of the Transformer model for image understanding, challenging traditional convolutional approaches.
DeiT, in particular, further addresses the challenges faced by ViT by introducing knowledge distillation. By leveraging a teacher-student training paradigm, DeiT demonstrates the potential to achieve competitive performance with significantly less labeled data, making it a valuable solution in scenarios where large datasets are not easily available.
As research in this field continues to advance, these innovations are paving the way for more efficient and powerful models, opening up exciting possibilities for the future of computer vision applications.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.