Command Palette
Search for a command to run...
OmniGen2: Exploration to Advanced Multimodal Generation
OmniGen2: Exploration to Advanced Multimodal Generation
Abstract
In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
One-sentence Summary
The authors, affiliated with Beijing Academy of Artificial Intelligence and collaborating institutions, propose OmniGen2, a lightweight open-source generative model with decoupled text and image decoding pathways and unshared parameters, enabling preserved text generation and improved consistency in multimodal tasks; it introduces a novel reflection mechanism and the OmniContext benchmark, achieving state-of-the-art performance on open-source benchmarks for in-context generation and image editing.
Key Contributions
-
OmniGen2 introduces a decoupled architecture with separate decoding pathways for text and image modalities, using unshared parameters and a dedicated image tokenizer, enabling it to leverage pre-trained multimodal understanding models without re-adapting VAE inputs and preserving strong text generation capabilities.
-
The model is trained on novel, high-quality datasets constructed from video sources for image editing and in-context generation, and incorporates a reflection mechanism specifically designed for iterative image refinement, supported by a curated reflection dataset based on OmniGen2.
-
OmniGen2 achieves state-of-the-art performance among open-source models on the newly introduced OmniContext benchmark for in-context generation, demonstrating superior consistency, and delivers competitive results on standard text-to-image and image editing benchmarks despite its relatively small parameter count.
Introduction
The authors leverage a decoupled architecture in OmniGen2 to enable unified multimodal generation across text-to-image synthesis, image editing, and in-context generation, addressing the limitations of prior unified models that often sacrifice text generation quality or require extensive retraining. Unlike earlier approaches that rely on shared parameters or end-to-end training of multimodal components, OmniGen2 uses unshared decoders and a dedicated image tokenizer, allowing it to preserve strong text generation capabilities by building on pre-trained multimodal understanding models without re-adapting VAE inputs. A key challenge in prior work—lack of high-quality, task-specific data for in-context generation and advanced editing—has been mitigated through novel data construction pipelines and the introduction of the OmniContext benchmark, a comprehensive evaluation suite for subject-driven image generation. The authors further contribute a reflection mechanism integrated within the model, enabling iterative refinement of image outputs, and release the full model, code, datasets, and training infrastructure to advance open research in multimodal generation.
Dataset
-
The dataset is constructed from a mix of open-source and proprietary sources, including Recap-DataComp, SAM-LLaVA, ShareGPT4V, LAION-Aesthetic, ALLaVA-4V, DOCCI, DenseFusion, JourneyDB, and BLIP3-o, totaling approximately 140 million open-source images. Additionally, 10 million proprietary images are included, with synthetic annotations generated using Qwen2.5-VL-72B.
-
For in-context generation, video data is used to create training pairs with consistent subjects across varying poses, viewpoints, and lighting. Keyframes are extracted from videos, with a base frame selected and primary subjects identified using Qwen2.5-VL-7B-Instruct. GroundingDINO generates subject bounding boxes, and SAM2 performs segmentation and tracking across frames. The last valid frame with all subjects is chosen to maximize appearance variation. A VLM-based filtering step ensures subject consistency, and FLUX.1-Fill-dev is used to outpaint subjects with new backgrounds. DINO-based similarity filtering removes outliers, and Qwen2.5-VL-7B-Instruct evaluates semantic quality and consistency. Object descriptions and captions are generated and integrated into natural language instructions, forming a training triplet: instruction, repainted image (input), original image (output).
-
For inpainting-based editing, high-quality images from text-to-image data are selected and inpainted using FLUX.1-Fill-dev without input instructions, ensuring random content filling. The inpainted image serves as input and the original as target, guaranteeing high-quality outputs. Editing instructions are then generated by an MLLM (Qwen2.5-VL), which produces accurate, high-fidelity instruction-image pairs by leveraging the model’s strong instruction-following ability.
-
Interleaved frame sequences are derived from video segments split at scene transitions. Two types are created: intra-scene (within same scene) and inter-scene (across different scenes), each up to five frames long. Consecutive frame pairs are annotated with descriptive captions using Qwen2.5-VL-7B-Instruct, capturing changes in object actions, environment, and appearance. This yields 0.8 million interleaved data samples for pretraining on continuous multimodal sequences.
-
The OmniContext benchmark is a manually curated, high-quality dataset designed to evaluate in-context image generation with multiple context types. It includes personal photos, open-source images, animation stills, and AI-generated images, covering three categories: Character, Object, and Scene. It supports three task types—SINGLE, MULTIPLE, and SCENE—each with eight subtasks (50 examples per subtask). Image-prompt pairs are created via a hybrid approach: initial filtering by MLLMs, followed by human curation based on subject clarity, aesthetic quality, and diversity. Prompts are generated with GPT-4o and refined by annotators for semantic and syntactic diversity.
-
Evaluation in OmniContext uses GPT-4.1 to assess outputs with three metrics: Prompt Following (PF), Subject Consistency (SC), and an Overall Score (geometric mean of PF and SC), all on a 0–10 scale with detailed rationales. This approach enhances explainability and accuracy compared to traditional image-level metrics like CLIP-I or DINO.
Method
The authors leverage a modular architecture for OmniGen2, designed to decouple text and image generation pathways while maintaining strong multimodal understanding. The core framework, as illustrated in the diagram, consists of an autoregressive transformer and a diffusion transformer, each handling distinct modalities. The autoregressive transformer, initialized with Qwen2.5-VL-3B, processes both textual and visual inputs. For text generation, it employs an autoregressive language head, while image generation is triggered by a special token, <limg>, which signals the diffusion decoder to synthesize an image. The hidden states from the autoregressive transformer serve as conditional inputs to the diffusion decoder. To enhance the decoder's visual fidelity, the model incorporates features extracted from a Variational Autoencoder (VAE) applied to the input images. This design allows the MLLM to preserve its multimodal understanding capabilities without the need for complex architectural modifications or retraining to adapt to the new image generation pathway.
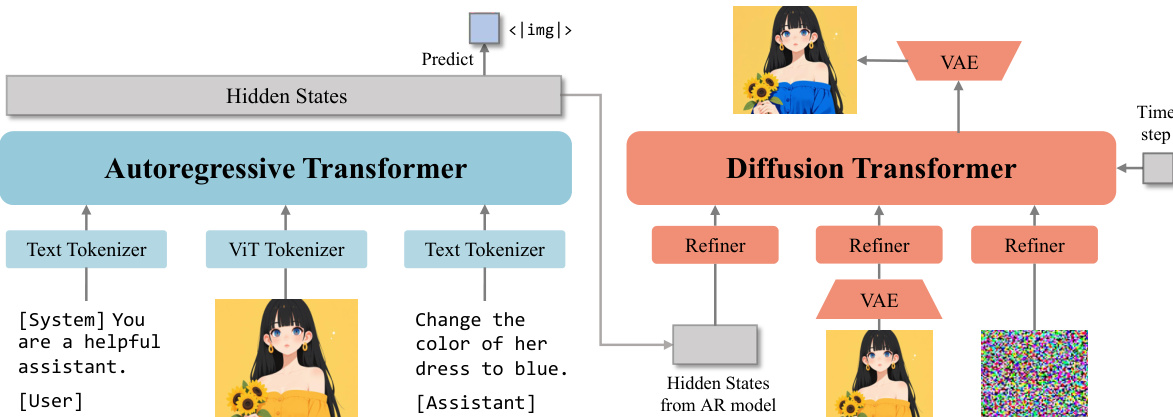
The diffusion transformer, depicted in the figure, is a simple architecture that directly concatenates features from the MLLM, VAE, and noise, enabling joint attention over these modalities. To ensure alignment between the multiple input conditions, a refiner network processes them before they are passed to the transformer layers. The diffusion decoder is composed of 32 layers with a hidden size of 2520, resulting in approximately 4 billion parameters. To reduce computational overhead, the model discards the image-related hidden states from the MLLM, retaining only those associated with text tokens, as the explicit incorporation of VAE features makes the MLLM's image-related states less critical. The diffusion transformer employs a 3D rotary position embedding, a modification of the Qwen mRoPE, which is designed to handle the complex positional requirements of multimodal tasks.

The authors introduce a novel multimodal rotary position embedding, Omni-RoPE, to address the challenges of position encoding in diverse and complex tasks. As shown in the figure, Omni-RoPE decomposes position information into three components. The first is a Sequence and Modality Identifier (idseq), which is constant for all tokens within a single image, treating it as a semantic unit, and unique across different images. For text tokens, this ID functions as a standard 1D positional index. The second and third components are 2D spatial height (h) and width (w) coordinates, which are normalized and locally computed from (0,0) for each image entity. This dual mechanism enables the model to unambiguously distinguish different images via their unique idseq, while the shared local spatial coordinates enhance consistency for tasks like image editing. For non-image tokens, both spatial coordinates (h,w) are set to zero, allowing the design to seamlessly degrade to a standard 1D positional embedding for text-only inputs.
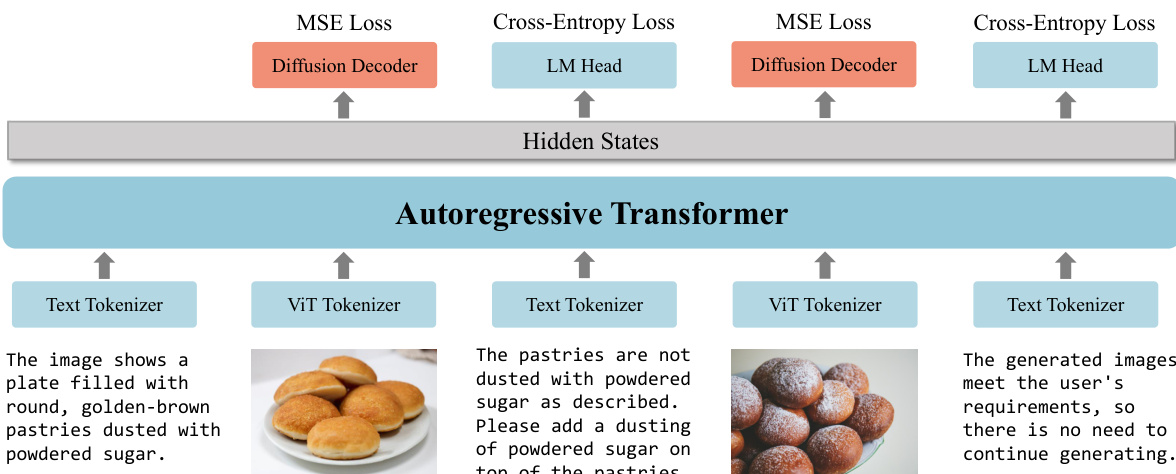
The training strategy for OmniGen2 is designed to preserve the MLLM's strong visual understanding while efficiently training the diffusion module. The MLLM is initialized with Qwen2.5-VL and kept frozen for the majority of its parameters during training, with only the newly introduced special tokens “” being updated. This approach ensures that the model's native multimodal understanding capabilities are fully preserved. The diffusion model is trained from scratch, initially on the text-to-image (T2I) generation task, and subsequently using a mixed-task training strategy to accommodate multiple objectives. During the reflection training phase, all model parameters are unfrozen, allowing the model to generate reflective textual descriptions and iteratively refine image outputs. The training process involves multiple loss functions, including MSE loss for the diffusion decoder and cross-entropy loss for the language model head, as illustrated in the diagram. The model is trained on a combination of text-to-image and in-context generation data, with the diffusion decoder learning to generate images conditioned on the hidden states from the MLLM and the VAE features.
Experiment
- OmniGen2 demonstrates unified performance across visual understanding, text-to-image generation, image editing, and in-context generation, achieving strong balance and excelling in in-context generation.
- On GenEval, OmniGen2 with LLM rewriter achieves 0.86 overall score, surpassing UniWorld-V1 (0.84) and approaching BAGEL (0.88), using only 4B trainable parameters and 15M T2I pairs.
- On DPG-Bench, OmniGen2 scores 83.57, outperforming UniWorld-V1 (81.38) and rivaling SD3-medium (84.08), confirming strong long prompt following.
- On Emu-Edit, OmniGen2 achieves the highest CLIP-Out score (0.309) and second-best CLIP-I (0.876) and DINO (0.822), indicating superior edit accuracy and image preservation.
- On GEdit-Bench, OmniGen2 scores 6.41 overall with a high SC score of 7.16, though performance is lower in Portrait Beautification (5.608) and Text Modification (5.141), indicating data limitations.
- On ImgEdit-Bench, OmniGen2 sets a new state-of-the-art among open-source models, with strong performance across all tasks.
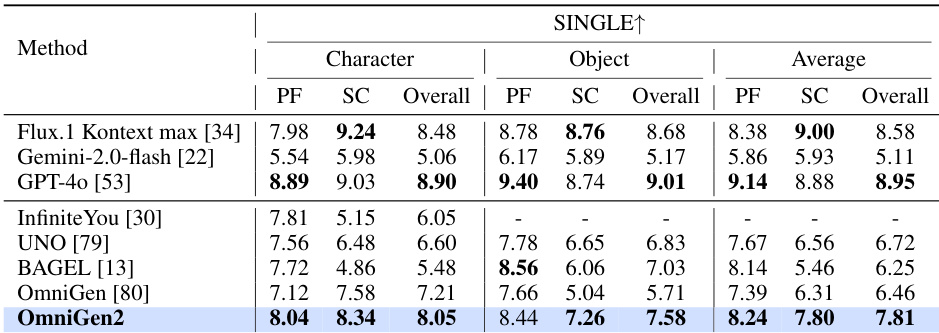
- On the proposed OmniContext benchmark, OmniGen2 achieves an overall score of 7.18, outperforming all open-source baselines in prompt following and subject consistency across single, multiple, and scene-based tasks.
- The reflection capability enables OmniGen2 to correct initial image flaws, particularly in color, quantity, and shape, though over-reflection and failure to correct occur due to limited perceptual capacity and training data.
- Limitations include performance disparity between English and Chinese prompts, difficulty with human body shape modification, sensitivity to input image quality, ambiguity in multi-image inputs, and imperfect object reproduction in in-context generation.
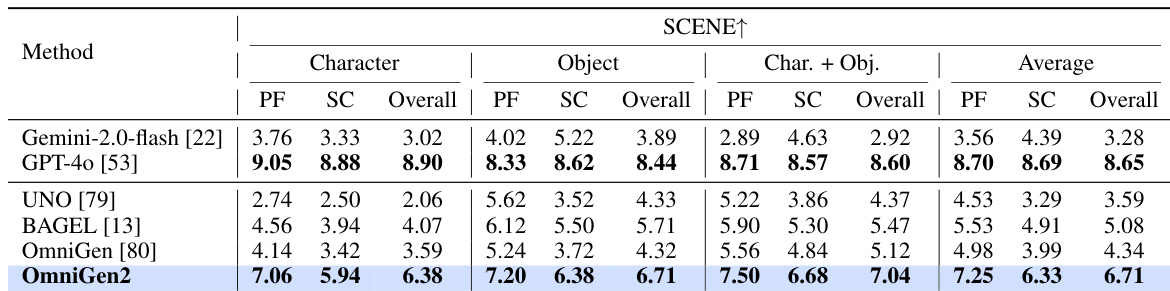
Results show that OmniGen2 achieves the highest overall score of 6.71 on the SCENE task in the OmniContext benchmark, outperforming all compared models across all subtasks. It demonstrates strong prompt-following and subject consistency, particularly excelling in the Character and Object categories with scores of 7.25 and 7.20 respectively.
The authors use the OmniContext benchmark to evaluate in-context generation capabilities, and results show that OmniGen2 achieves an overall score of 7.18, outperforming all open-source models across all subtasks and demonstrating strong prompt-following ability and subject consistency. It shows significant improvements over existing models, particularly in handling single and multiple image inputs, though closed-source models like GPT-4o and Flux.1 Kontext achieve higher scores in specific metrics.
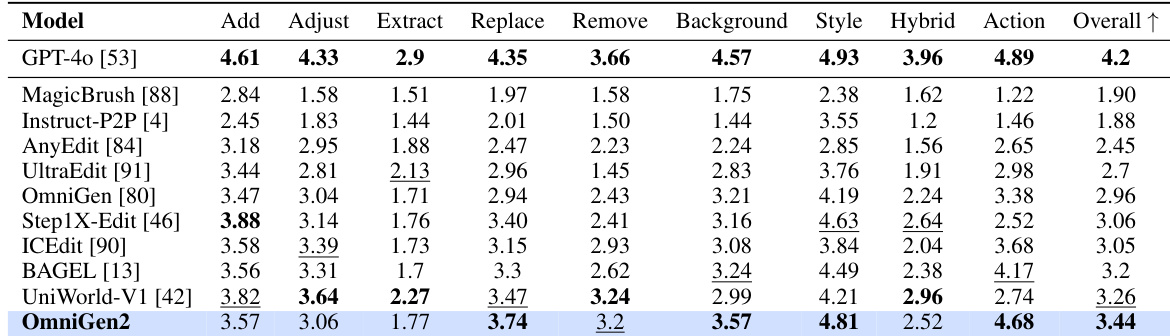
Results show that OmniGen2 achieves the highest scores across all metrics in the MULTIPLE task type of the OmniContext benchmark, outperforming both open-source and closed-source models. The authors use this table to demonstrate OmniGen2's superior prompt-following ability and subject consistency in in-context generation tasks involving multiple images.
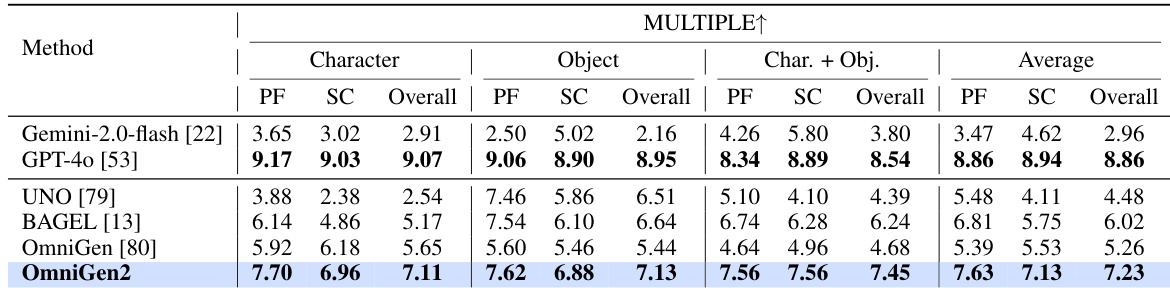
The authors use the table to compare OmniGen2 with existing models across multiple tasks, showing that OmniGen2 achieves strong performance in in-context generation, particularly in the Single and Multiple task types, with scores of 7.81 and 7.23 respectively. Results show that OmniGen2 also performs competitively in image generation and editing, with high scores on GenEval and DPG-Bench, and it outperforms other models in image editing tasks such as Emu-Edit and ImgEdit-Bench.
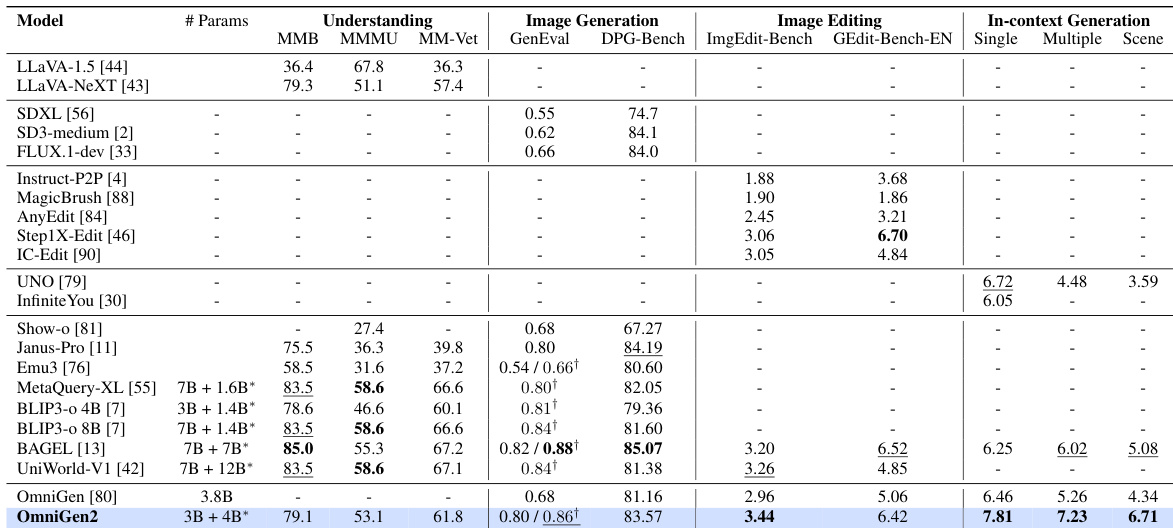
Results show that OmniGen2 achieves strong performance across all evaluation metrics on the OmniContext benchmark, particularly excelling in prompt following and subject consistency. It outperforms all open-source models and ranks among the top-performing models overall, demonstrating superior in-context generation capabilities.