Command Palette
Search for a command to run...
A New Milestone in the Field of brain-computer Interfaces: Thoughts Speak, Machines Interpret
Using neural networks to decode the neural signals in the corresponding brain areas when people speak, and then using recurrent neural networks to synthesize the signals into speech, can help patients with language disorders solve language communication problems.
"Mind reading" may really become a reality.
Speaking is a very common thing for most people. However, there are still many people in this world who suffer from diseases such as stroke, traumatic brain injury, neurodegenerative diseases such as Parkinson's disease, multiple sclerosis and amyotrophic lateral sclerosis (ALS or Lou Gehrig's disease), etc., who often have difficulty speaking.Irreversible loss of the ability to speak.
Scientists have been working hard to restore human functions and repair nerves, and brain-computer interface (BCI) is a key area.
Brain-computer interface refers to a direct connection created between the human or animal brain and external devices to enable information exchange between the brain and the device.
But it seems that brain-computer interface has always been a distant concept. Today, a paper published in the top academic journal NatureSpeech synthesis from neural decoding of spoken sentences” (“Speech Synthesis with Neural Decoding of Spoken Sentences”), which shows us that research in the field of brain-computer interfaces has taken a major step forward.
The plight of people with speech impairments
In fact, the research on brain-computer interface has been going on for more than 40 years. However, the most successful and clinically popular ones so far are sensory prosthetic technologies such as cochlear implants.
To this day, some people with severe speech impairments can only express their thoughts word by word using assistive devices.
These assistive devices can track very subtle eye or facial muscle movements and spell out words based on the patient's gestures.
Physicist Stephen Hawking once had such a device installed on his wheelchair.

At that time, Hawking used infrared to detect muscle movements to issue commands, confirm the letters scanned by the computer cursor, and write down the words he wanted. After that, he used a text-to-speech device to "speak" the words. It is with the help of these black technologies that we can read his book "A Brief History of Time".
However, with such equipmentGenerating text or synthesized speech is laborious, error-prone, and very slow.Usually, a maximum of 10 words per minute is allowed. Hawking was already very fast at the time, but he could only spell 15-20 words. Natural speech can reach 100 to 150 words per minute.
In addition, this method is severely limited by the operator's own body movement ability.
To solve these problems, the brain-computer interface field has been studying how to directly interpret the corresponding electrical signals of the cerebral cortex into speech.
Neural networks interpret brain signals to synthesize speech
Now, there has been a breakthrough in solving this difficult problem.
Edward Chang, a professor of neurosurgery at the University of California, San Francisco, and his colleagues proposed in their paper "Speech Synthesis from Neural Decoding of Spoken Sentences" thatThe brain-computer interface created can decode the neural signals generated when people speak and synthesize them into speech.The system can generate 150 words per minute, which is close to the normal human speaking speed.

The team of researchers recruited five epilepsy patients who were undergoing treatment and had them speak hundreds of sentences aloud while their high-density electroencephalogram (ECoG) signals were recorded and tracked neural activity in the ventral sensorimotor cortex, the brain's speech production center.
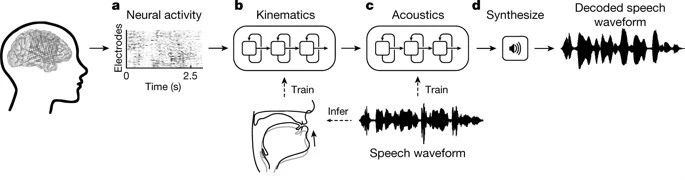
useRecurrent Neural Networks (RNNs), the researchers decoded the collected neural signals in two steps.
First, theyConvert neural signals into signals that represent the movements of the vocal organs.Includes brain signals related to jaw, throat, lip and tongue movements.
The second step is to convert the signal into spoken words based on the decoded movements of the vocal organs.

In the decoding process, the researchers first decoded the continuous electrogram signals from the surface of three brain regions when the patient spoke. These electrogram signals were recorded by invasive electrodes.
After decoding, 33 types of vocal organ movement characteristic indicators are obtained, which are then decoded into 32 speech parameters (including pitch, voicing, etc.), and finally speech sound waves are synthesized based on these parameters.
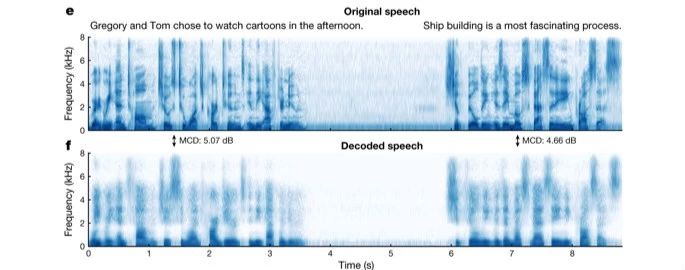
To analyze the accuracy of the synthesized speech in reproducing real speech, the researchers compared the sonic features of the original speech with the synthesized speech and found that the speech decoded by the neural network reproduced the individual phonemes in the original sentence uttered by the patient quite completely, as well as the natural connections and pauses between phonemes.
Afterwards, the researchers used crowdsourcing to ask netizens to identify the speech synthesized by the decoder. The final result was that the listeners' retelling of the synthesized speech content wasThe success rate is close to 70%.
In addition, the researchers tested the decoder's ability to synthesize speech without speaking out loud. The tester first spoke a sentence and then silently recited the same sentence (with movements but without making any sound). The results showed that the decoder's speech spectrum synthesized by the silent speech movement was similar to the spoken spectrum of the same sentence.
Milestone: Challenges and expectations coexist
“This study shows for the first time that we can generate complete spoken sentences based on an individual’s brain activity,” Chang said. “This is exciting. This is technology that is within reach, and we should be able to build clinically feasible devices for patients with language loss.”
Gopala Anumanchipalli, first author of the paper, added: "I am proud to have brought together expertise in neuroscience, linguistics, and machine learning to be part of this important milestone in helping people with neurological disabilities."
Of course, there are still many challenges to truly achieve 100% speech synthesis in brain-computer interface voice interaction, such as whether patients can accept invasive surgery to install electrodes, whether the brain waves in the experiment are the same as those of real patients, etc.
However, from this study, we sawSpeech synthesis brain-computer interface is no longer just a concept.
We hope that one day in the future, people with speech disorders will be able to regain the ability to "speak" and express their thoughts as soon as possible.


