Command Palette
Search for a command to run...
AI Weekly Report: Recursive Inference Methods, Lightweight Decoder Architectures, Deep Convolutional Neural Network Architectures, and More

The long-term goal of language-based agents is to continuously learn and optimize through their experience, ultimately surpassing human performance in complex real-world tasks. However, training agents using reinforcement learning based solely on empirical data remains challenging in many environments, where verifiable reward signals are lacking (e.g., web page interactions) or where inefficient long-term trajectory replay is required (e.g., multiple rounds of tool usage). Consequently, most current agents still rely on supervised fine-tuning using expert data, an approach that is difficult to scale and suffers from poor generalization.
To overcome this limitation, the Meta Superintelligence Lab, Meta FAIR, and Ohio State University jointly proposed a compromise paradigm called "Early Experience." This paradigm uses interaction data generated by the agent's own behavior, with future states serving as supervisory signals, rather than relying on reward signals. This paradigm laid a solid foundation for subsequent reinforcement learning, making it a viable bridge between imitation learning and fully experience-driven agents.
Paper link:https://go.hyper.ai/a8Zkn
Latest AI Papers:https://go.hyper.ai/hzChC
In order to let more users know the latest developments in the field of artificial intelligence in academia, HyperAI's official website (hyper.ai) has now launched a "Latest Papers" section, which updates cutting-edge AI research papers every day.Here are 5 popular AI papers we recommend, let’s take a quick look at this week’s cutting-edge AI achievements⬇️
This week's paper recommendation
1. Less is More: Recursive Reasoning with Tiny Networks
This paper proposes the Tiny Recursive Model (TRM), a simpler recursive inference method that significantly outperforms the HRM in generalization, while relying solely on a tiny two-layer neural network. With only 7 million parameters, TRM achieves a test accuracy of 451 TP3T on the ARC-AGI-1 task and 81 TP3T on the ARC-AGI-2 task, both exceeding the performance of most large language models (such as Deepseek R1 and o3-mini), while using less than 0.011 TP3T of these models' parameters.
Paper link:https://go.hyper.ai/bUZ6M
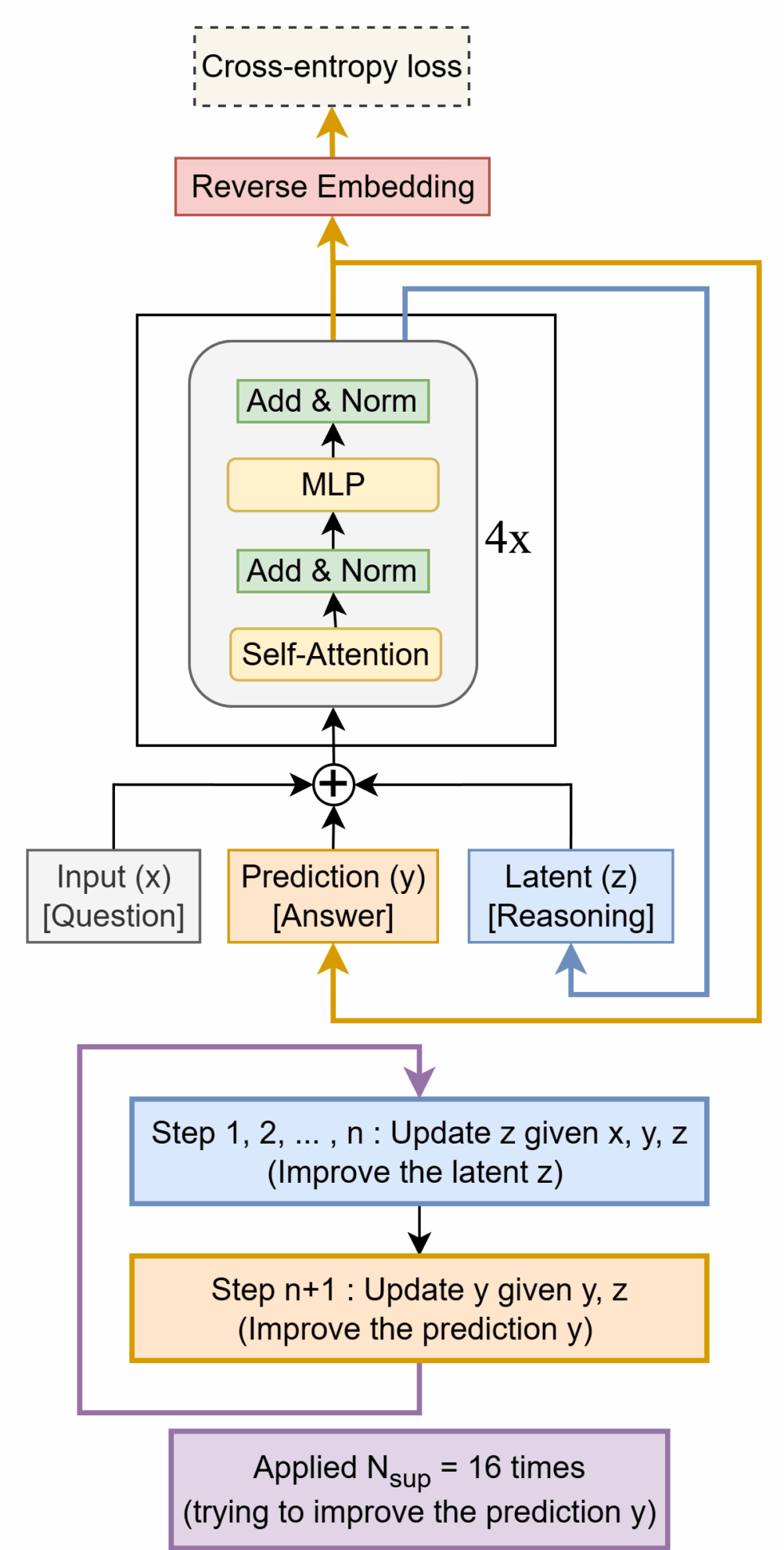
2. PromptCoT 2.0: Scaling Prompt Synthesis for LLM Reasoning
This paper presents PromptCoT 2.0, a scalable framework that replaces hand-crafted heuristic rules with an expectation-maximization (EM) iterative loop to guide prompt construction by iteratively optimizing the inference process. This approach generates questions that are not only more challenging but also more diverse than previous corpora.
Paper link:https://go.hyper.ai/jKAmy
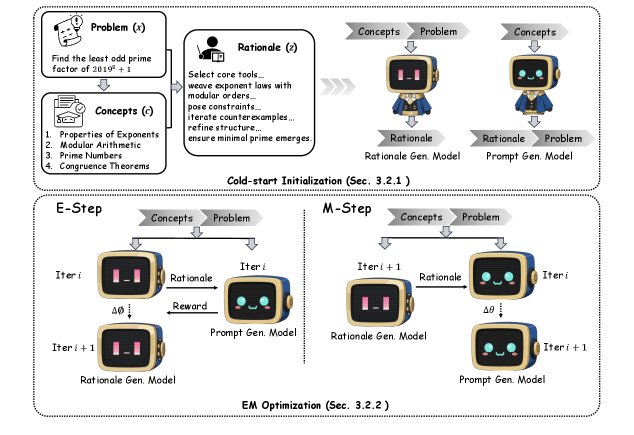
3. Looking to Learn: Token-wise Dynamic Gating for Low-Resource Vision-Language Modelling
This paper proposes a lightweight decoder architecture with three key designs: (1) a token-level dynamic gating mechanism to achieve adaptive fusion of language and visual cues; (2) feature modulation and channel attention mechanism to maximize the utilization efficiency of limited visual information; and (3) an auxiliary contrast learning objective to improve visual localization capabilities.
Paper link:https://go.hyper.ai/D178P
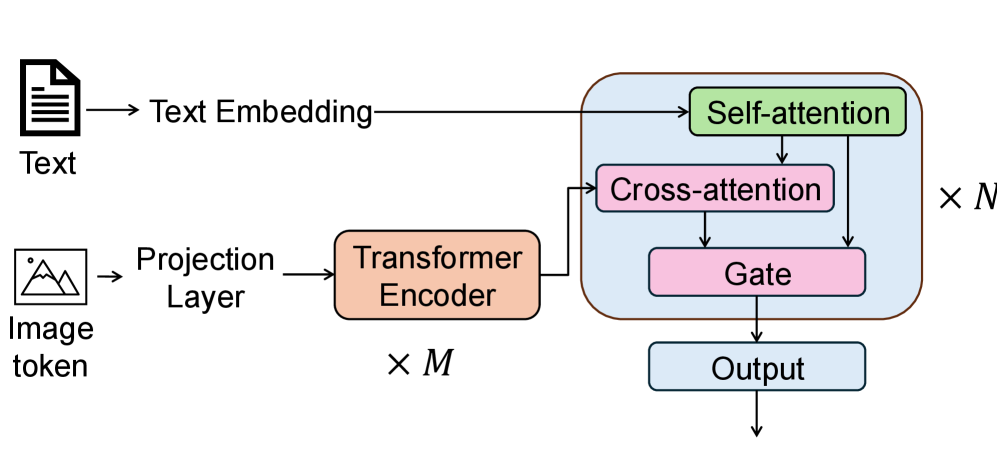
4. Agent Learning via Early Experience
Most current intelligent agents still rely on supervised fine-tuning using expert data, but this approach is difficult to scale and suffers from poor generalization. This limitation stems from the nature of expert demonstrations: they cover only a limited number of scenarios, resulting in an insufficient diversity of environments exposed to the agent. To overcome this limitation, this paper proposes a compromise paradigm: "early experience," which involves using interaction data generated by the agent through its own behavior, with future states serving as supervisory signals, without relying on reward signals.
Paper link:https://go.hyper.ai/a8Zkn
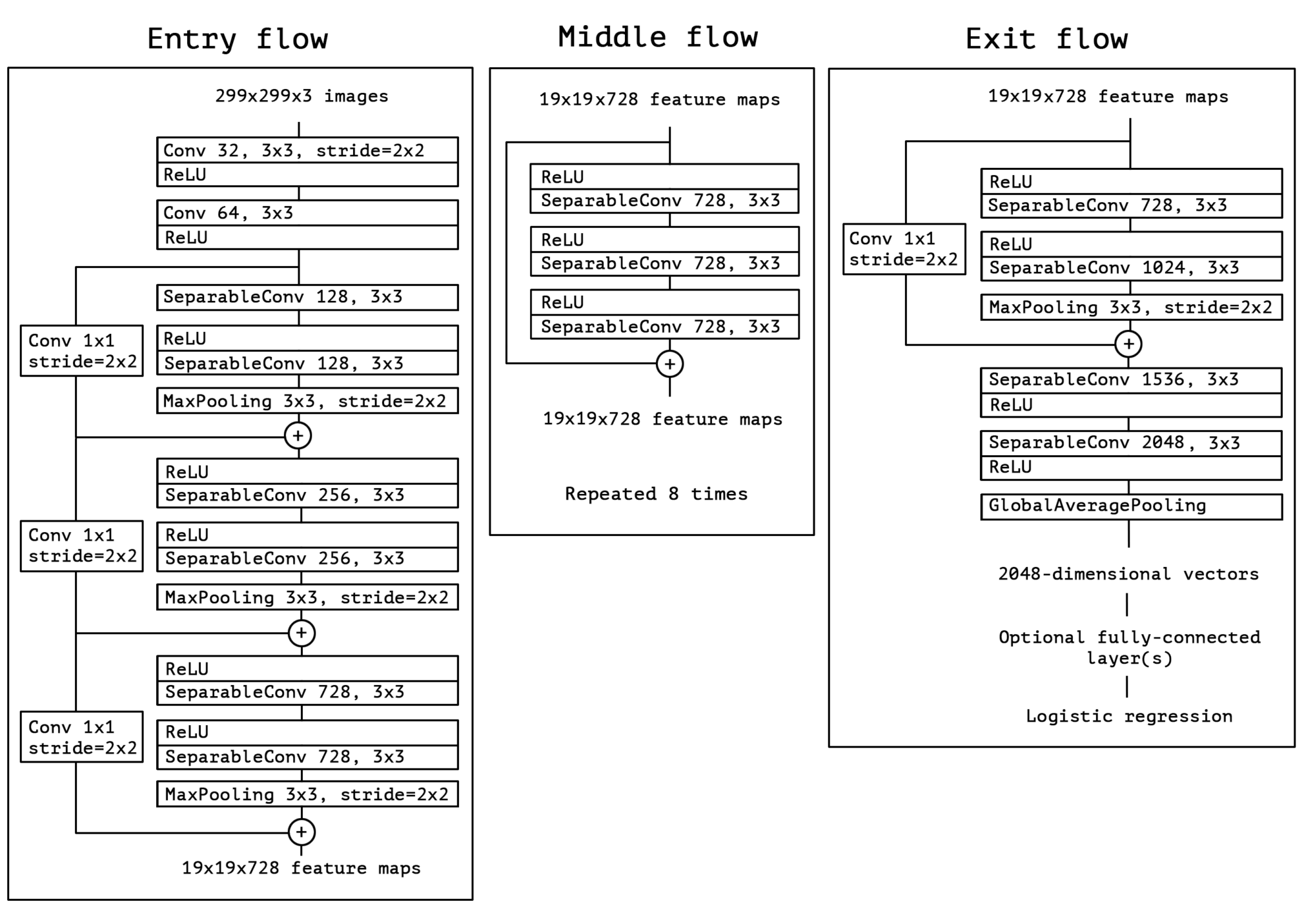
5. Xception: Deep Learning with Depthwise Separable Convolutions
This paper proposes Xception, a novel deep convolutional neural network architecture inspired by Inception, in which the Inception module has been replaced by depthwise separable convolutions. Since the Xception architecture has the same number of parameters as Inception V3, the performance improvement is not due to an increase in model capacity, but rather to more efficient utilization of model parameters.
Paper link:https://go.hyper.ai/0BUt5
The above is all the content of this week’s paper recommendation. For more cutting-edge AI research papers, please visit the “Latest Papers” section of hyper.ai’s official website.
We also welcome research teams to submit high-quality results and papers to us. Those interested can add the NeuroStar WeChat (WeChat ID: Hyperai01).
See you next week!








