Command Palette
Search for a command to run...
Online Tutorial: SpikingBrain-1.0: A Hundredfold Speedup: Achieving Orders of Magnitude Improvements in Inference Efficiency

The rapid development of artificial intelligence is largely inseparable from a core architecture: the Transformer. Since its introduction in 2017, the Transformer, with its parallel computing capabilities and powerful modeling results, has become the mainstream standard for large-scale model architectures. Whether it's the GPT series, LLaMA, or the domestic Qwen series, they are all built on the Transformer foundation.
However, as the model size continues to expand, Transformer gradually exposes some problems that are difficult to ignore.For example, the overhead during training increases quadratically with the sequence length, and the memory usage during inference increases linearly with the sequence length, resulting in resource consumption and limiting its ability to process extremely long sequences.
In stark contrast, the biological brain takes a completely different approach to energy efficiency and flexibility. The human brain consumes only about 20 watts of power yet is capable of handling a vast array of tasks, including perception, memory, language, and complex reasoning. This contrast has prompted researchers to ponder: If large models are designed and computed more like the brain, could they overcome the bottlenecks presented by the Transformer?
Based on this exploration,The Institute of Automation of the Chinese Academy of Sciences, in collaboration with the National Key Laboratory of Brain Cognition and Brain-Inspired Intelligence and other institutions, drew on the complex working mechanisms of brain neurons and proposed a large-scale model architecture "based on endogenous complexity". In September this year, they released a native domestically produced, independently controllable brain-inspired pulse large-scale model - "SpikingBrain-1.0".This model theoretically establishes a connection between the intrinsic dynamics of spiking neurons and linear attention models, revealing that existing linear attention mechanisms are a specialized simplification of dendritic computation and demonstrating a new and viable path for continuously improving model complexity and performance. Furthermore, the R&D team has built and open-sourced a novel brain-inspired foundational model based on spiking neurons, with linear and mixed-linear complexity. They have also developed an efficient training and inference framework for domestic GPU clusters, the Triton operator library, model parallelization strategies, and cluster communication primitives.
Through experimental verification,SpikingBrain-1.0 has achieved breakthroughs in four performance aspects: achieving efficient training with extremely low data volumes, achieving an order of magnitude improvement in inference efficiency, building a domestically produced, independent and controllable brain-like large-scale model ecosystem, and proposing a multi-scale sparsity mechanism based on dynamic threshold pulsing.The SpikingBrain-7B model achieved a 100x speedup in Time to First Token (TTF) for a 4 million-token sequence. Training of the SpikingBrain-7B model ran stably for weeks on hundreds of MetaX C550 GPUs, achieving a FLOP utilization rate of 23.41 TP3T.The proposed pulse scheme achieves a sparsity of 69.15%, thus enabling low-power operation.
It is worth noting thatThis is the first time that my country has proposed a large-scale brain-like linear basic model architecture, and the first time that a training and inference framework for a large brain-like pulse model has been built on a domestic GPU computing cluster.Its ultra-long sequence processing capability has significant potential efficiency advantages in ultra-long sequence task modeling scenarios such as legal and medical document analysis, complex multi-agent simulation, high-energy particle physics experiments, DNA sequence analysis, and molecular dynamics trajectories.
Currently, "SpikingBrain-1.0: A Brain-like Spiking Model Based on Intrinsic Complexity" is now available on the HyperAI official website in the "Tutorial" section. Click the link below to experience the one-click deployment tutorial ⬇️
Tutorial Link:
Demo Run
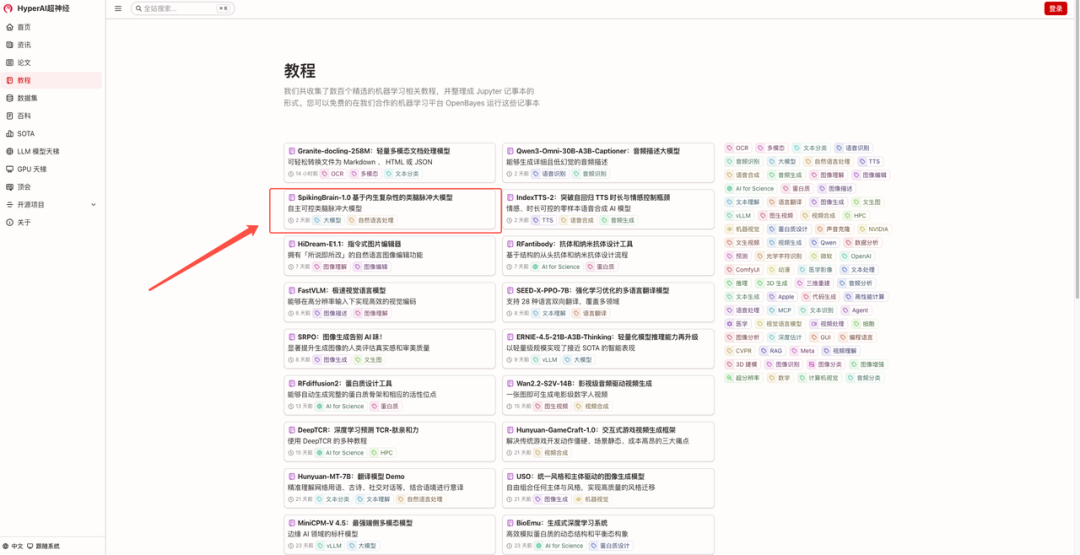
1. After visiting the hyper.ai homepage, select the "Tutorials" page, select "SpikingBrain-1.0: A Large Brain-Like Spiking Model Based on Intrinsic Complexity", and click "Run this tutorial online".
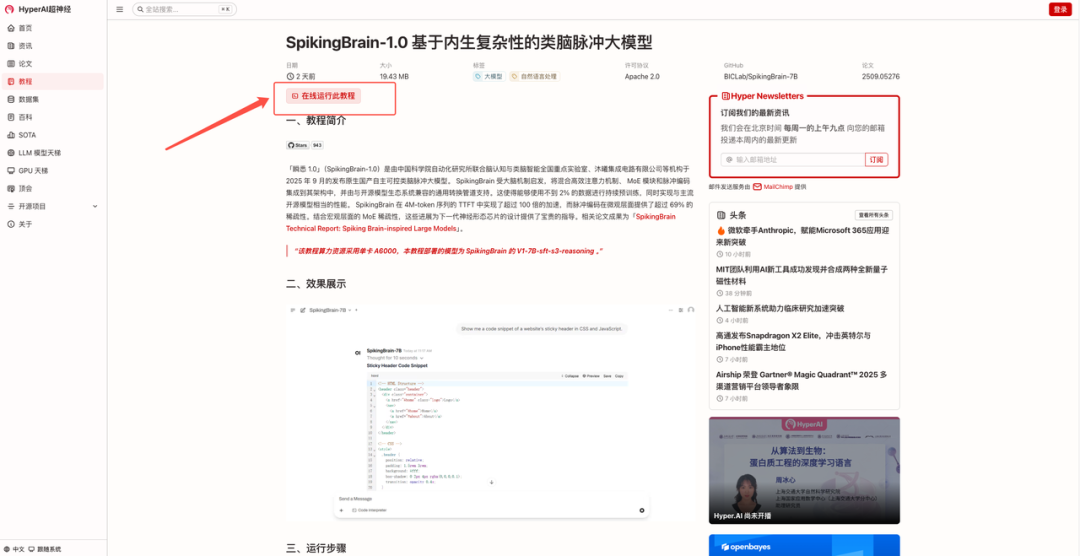
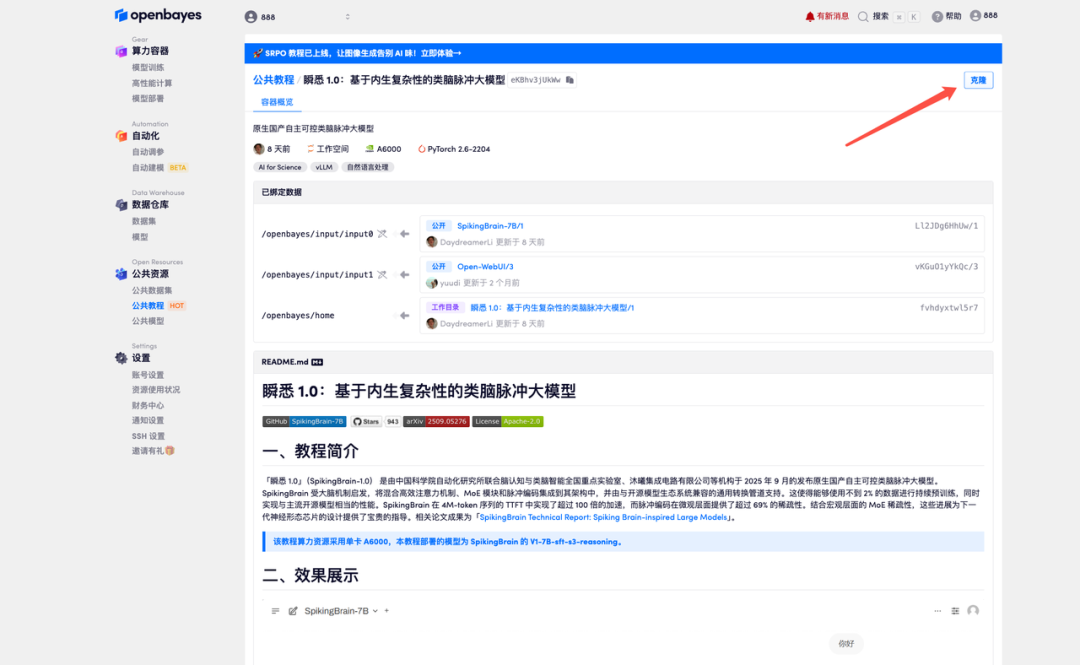
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
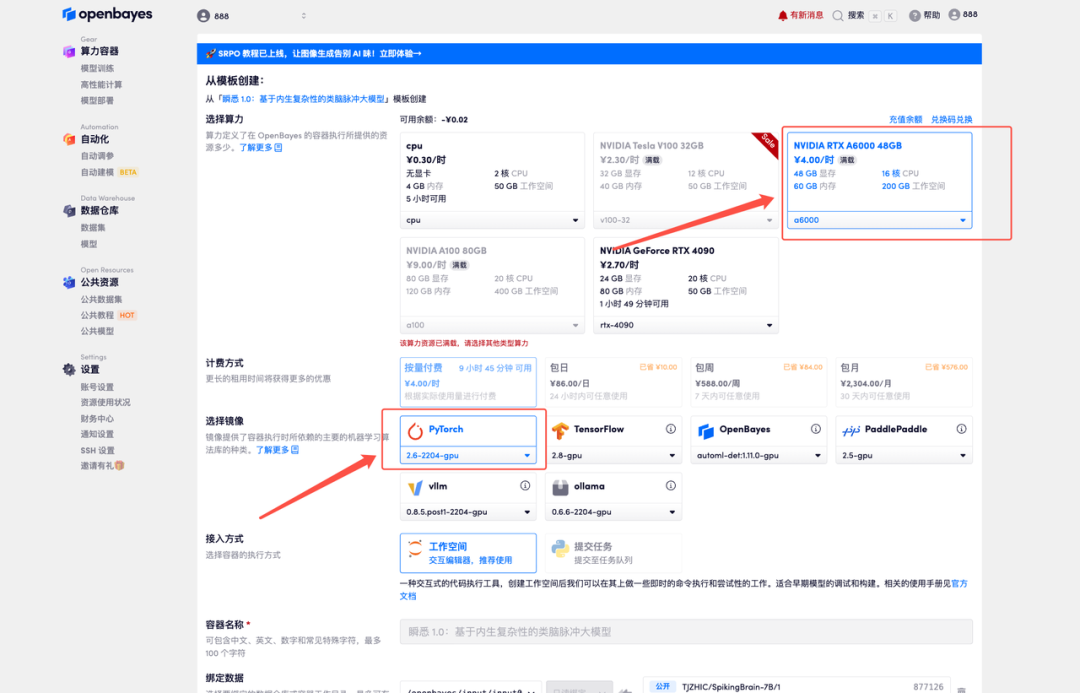
3. Select the NVIDIA RTX A6000 48GB and PyTorch images and click Continue. The OpenBayes platform offers four billing options: pay-as-you-go or daily/weekly/monthly plans. New users can register using the invitation link below to receive 4 hours of free RTX 4090 and 5 hours of free CPU time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
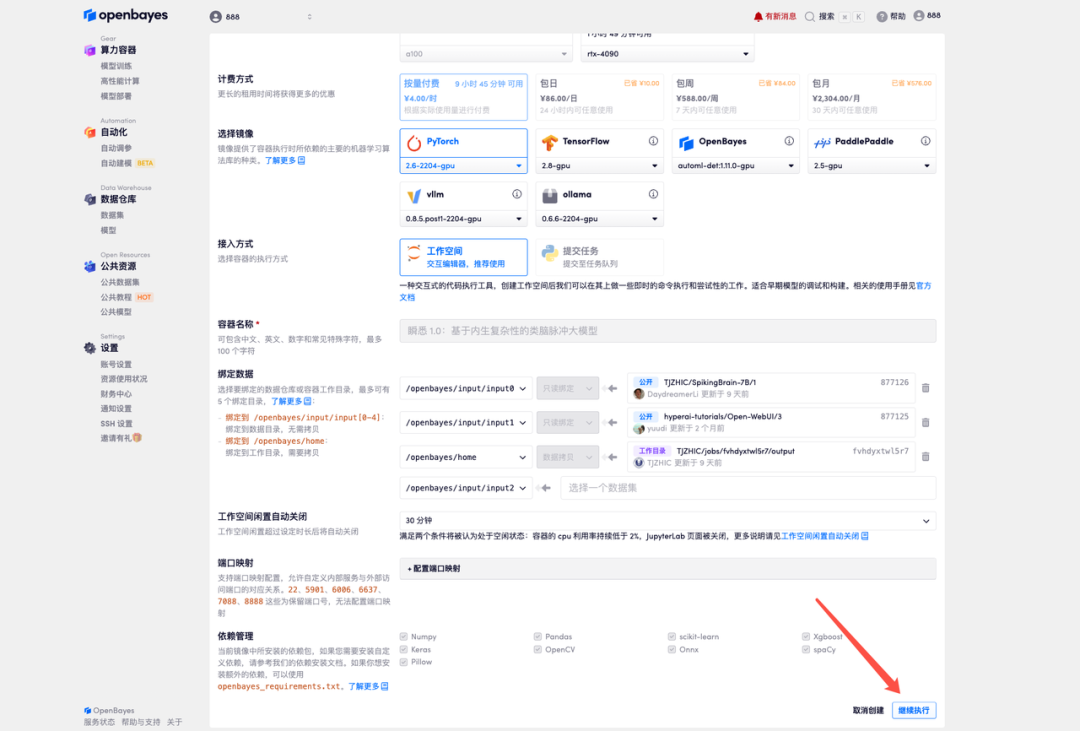
4. Wait for resources to be allocated. The first cloning process will take approximately 3 minutes. When the status changes to "Running," click the arrow next to "API Address" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address.
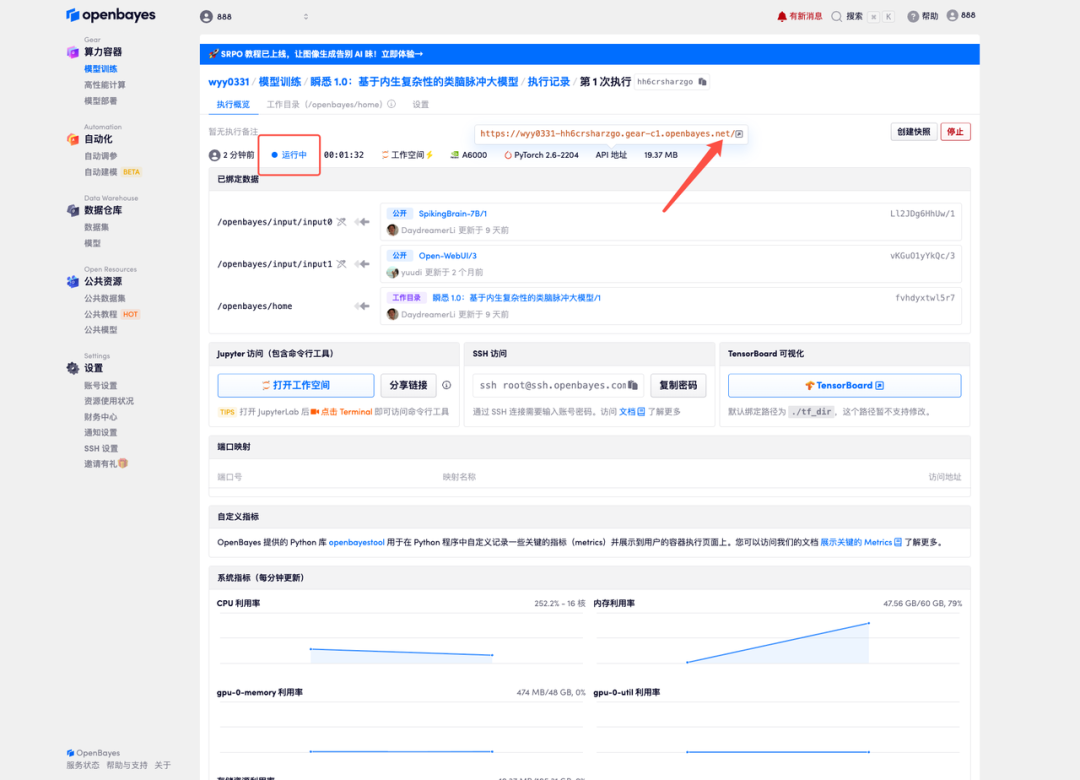
5. Enter the question in the dialog box to start answering.
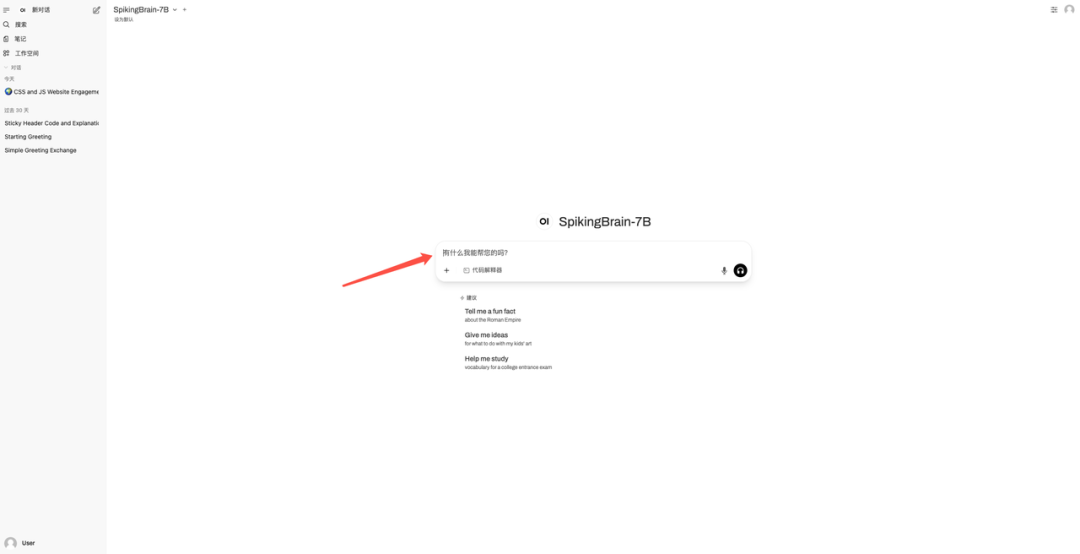
Effect Demonstration
I asked the question "Show me a code snippet of a website's sticky header in CSS and JavaScript." as an example. The result is shown in the figure below:

The above is the tutorial recommended by HyperAI this time. Everyone is welcome to come and experience it!
Tutorial Link:








