Command Palette
Search for a command to run...
Qwen3-Max Boasts Over One Trillion Parameters, Achieving SOTA on Multiple Benchmarks, and a Predicted inference-enhanced Version Achieving a Perfect Score in the Mathematical Olympiad.

Today (September 24), the annual Yunqi Conference officially opened. On this stage where Alibaba Cloud shows off its strength, AI is undoubtedly the protagonist. From open source models to agent applications, to infrastructure such as servers and the developer ecosystem, it fully demonstrated its technological competitiveness in this round of AI competition.According to the Hugging Face list, the number of derivative models developed based on Tongyi Qianwen has reached 170,000, surpassing the American Llama series and ranking first in the world.
Readers who follow Alibaba may know that just one day before the opening of the Yunqi Conference, Alibaba's Tongyi Big Model team had already open-sourced three high-performance models - the native omnimodal big model Qwen3-Omni, the speech generation model Qwen3-TTS, and the image editing model Qwen-Image-Edit-2509. All of them have achieved performance comparable to mainstream models or even SOTA level in their corresponding fields.
Now it seems that these are just appetizers. At the opening ceremony of the just-concluded Yunqi Conference, Qwen3-Max was officially unveiled. This model is said to be its largest and most powerful model to date. With a total model parameter of 1T, it swept multiple evaluation benchmarks. In addition,The conference also introduced models such as Qwen3-VL and Qwen3-Coder.
Qwen3-Max: The largest and most powerful yet
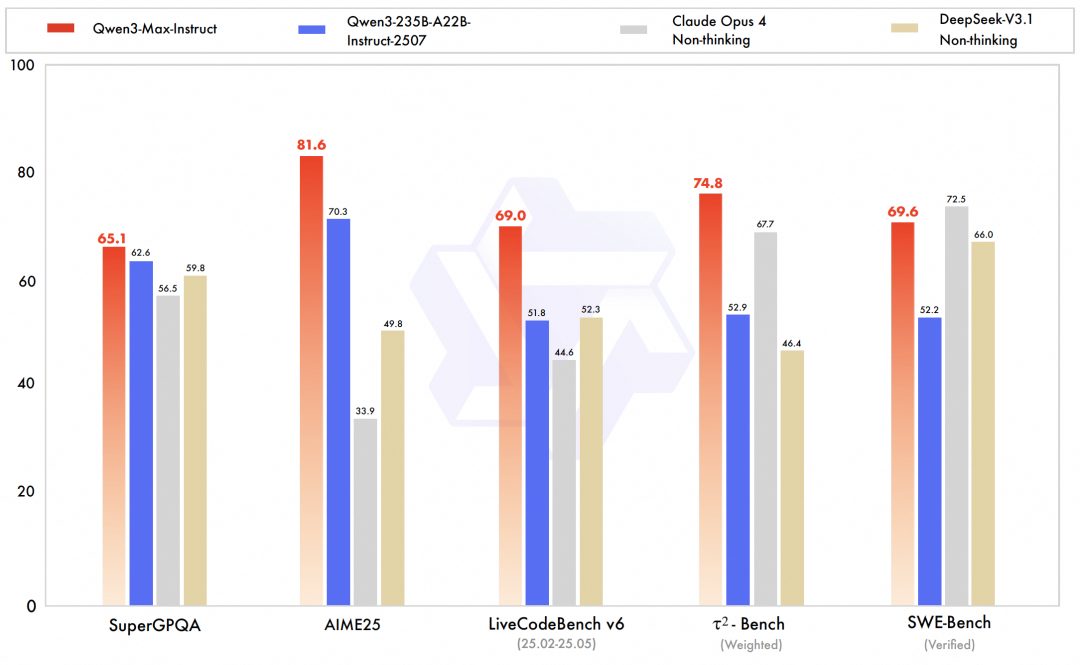
Qwen3-Max is the undisputed highlight of this release. As the team’s largest and most capable model to date, the preview version of Qwen3-Max-Instruct ranked third on the LMArena text leaderboard, surpassing GPT-5-Chat.The official version further improves code capabilities and agent capabilities, reaching the SOTA level in comprehensive benchmark tests covering knowledge, reasoning, programming, instruction following, human preference alignment, intelligent agent tasks and multi-language understanding.For example, on the SWE-Bench Verified benchmark, which focuses on solving real-world programming challenges, Qwen3-Max-Instruct achieved an excellent score of 69.6 points. On the Tau2-Bench benchmark, which evaluates the tool-calling capabilities of intelligent agents, Qwen3-Max-Instruct surpassed Claude Opus 4 and DeepSeek-V3.1 with a score of 74.8 points.
Specifically, the total parameters of the Qwen3-Max model exceed 1T, and 36T tokens are used for pre-training.The model architecture follows the MoE model design of the Qwen3 series and utilizes global-batch load balancing loss, ensuring stable and smooth pre-training loss. Training is seamless, without any loss spikes or adjustments such as training rollback or data distribution changes.
According to official introduction, under the optimization of PAI-FlashMoE's efficient multi-stage pipeline parallel strategy, the training efficiency of Qwen3-Max-Base has been significantly improved, and its MFU has been improved by 30% compared with Qwen2.5-Max-Base. In the long sequence training scenario, the team further used the ChunkFlow strategy to obtain a throughput benefit that was 3 times higher than the sequence parallel solution, supporting the training of Qwen3-Max 1M long context. At the same time, through various means such as SanityCheck, EasyCheckpoint, and scheduling link optimization,The time loss caused by hardware failure in Qwen3-Max on a large-scale cluster is reduced to one-fifth of that in Qwen2.5-Max.
It is worth mentioning that although Qwen3-Max's reasoning-enhanced version Qwen3-Max-Thinking has not been officially announced, according to data released by the team, its deep reasoning capabilities have reached a new high, achieving full marks on the extremely challenging mathematical reasoning benchmarks AIME 25 and HMMT, and even reaching full marks in the Olympic Mathematics Competition.
Qwen3-VL-235B: Refreshing SOTA and ranking first in the world
Qwen3-VL is a multimodal vision-language model (VLM) branch within the Qwen3 series. It aims to achieve a balance and breakthrough between visual understanding and text generation capabilities. The team calls it the most powerful vision-language model in the Qwen series to date. Qwen3-VL demonstrates significant improvements in understanding and generating pure text, perceiving and reasoning about visual content, supporting context length, understanding spatial relationships and dynamic video, and even in its performance during agent interactions.
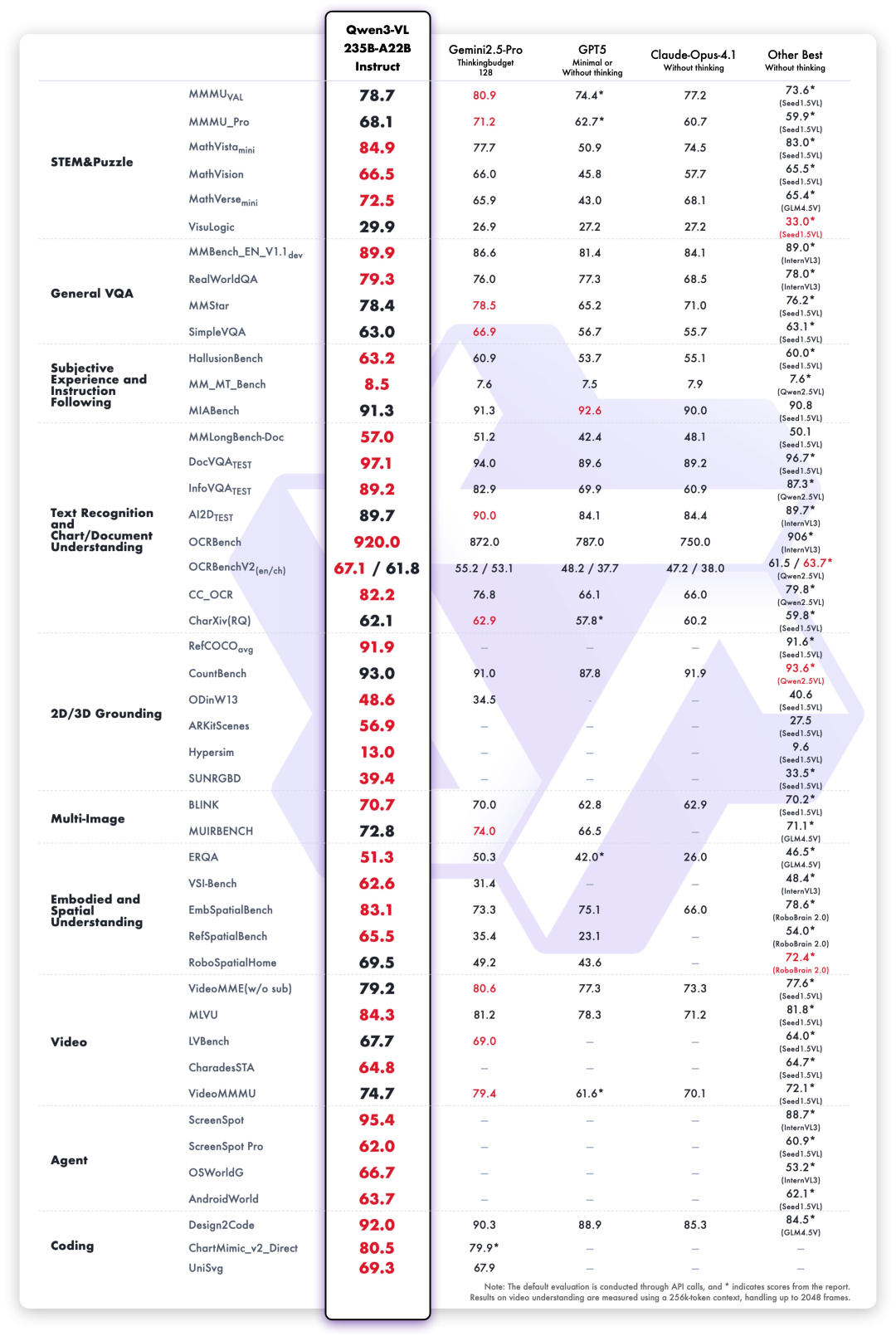
The new open source flagship model Qwen3-VL-235B released this time is ranked first in the world in terms of overall performance, and has significantly improved its performance in high-definition complex images and fine-grained recognition scenes.It includes both Instruct and Thinking versions.
Under the evaluation of 10 dimensions including comprehensive university questions, mathematical and scientific reasoning, logic puzzles, general visual question answering, subjective experience and instruction following, multilingual text recognition and chart document parsing,Qwen3-VL-235B-A22B-Instruct performs best in most indicators among non-inference models.It significantly surpasses closed-source models such as Gemini 2.5 Pro and GPT-5, while refreshing the best results of open-source multimodal models, demonstrating its strong generalization ability and comprehensive performance in complex visual tasks.
Specifically, Qwen3-VL has undergone systematic upgrades in multiple key capability dimensions:
Visual Agent:Qwen3-VL can operate computer and mobile phone interfaces, identify GUI elements, understand button functions, call tools, and execute tasks. It has reached world-leading levels on benchmarks such as OS World and can effectively improve its performance in fine-grained perception tasks by calling tools.
Plain text capabilities rival those of top language models:Qwen3-VL uses mixed text and visual modalities for collaborative training in the early stages of pre-training, continuously strengthening its text capabilities. Ultimately, its performance on pure text tasks is comparable to that of the flagship Qwen3-235B-A22B-2507 pure text model. It is a truly next-generation visual language model with a solid text foundation and multimodal versatility.
Visual coding capabilities have been greatly improved:Implement image generation code and video generation code. For example, when you see a design drawing, the code generates Draw.io/HTML/CSS/JS code, truly realizing "what you see is what you get" visual programming.
Spatial perception ability is greatly improved:2D grounding changes from absolute coordinates to relative coordinates, supporting the judgment of object orientation, perspective changes, and occlusion relationships. It can achieve 3D grounding and lay the foundation for spatial reasoning and embodied scenes in complex scenarios.
Long context support and long video understanding:The entire model family natively supports a context length of 256K tokens, and is scalable to 1 million tokens. This means that whether it's a hundreds-page technical document, an entire textbook, or a two-hour video, it can be fully input, fully memorized, and accurately retrieved, supporting video pinpointing down to the second.
Multimodal thinking ability is significantly enhanced:The Thinking model prioritizes STEM and mathematical reasoning skills. When faced with specialized subject questions, the model captures details, unravels complexities, analyzes cause and effect, and provides logical, well-founded answers. It has achieved leading performance in authoritative assessments such as MathVision, MMMU, and MathVista.
Visual perception and recognition capabilities have been comprehensively upgraded: By optimizing the quality and breadth of pre-training data, the model can now recognize a richer range of object categories—from celebrities, anime characters, commodities, landmarks, to plants and animals, covering the "everything recognition" needs of daily life and professional fields.
OCR supports more languages and complex scenarios:The number of supported languages other than Chinese and English has been expanded from 10 to 32, covering more countries and regions; the performance is more stable in challenging real-life shooting scenarios such as complex lighting, blur, and tilt; the recognition accuracy of rare characters, ancient characters, and professional terms has also been significantly improved; and the ability to understand ultra-long documents and restore fine structures has been further enhanced.
Qwen3 Coder Plus:Programming efficiencyHigher and more precise
As the exclusive coding model of the Qwen3 series, Qwen3 Coder is a comprehensive upgrade of the previous generation Coder. It adopts a closed-source API to provide higher programming efficiency and accuracy. It has become one of the most popular programming models in the world and is widely loved by developers.
The Qwen3 Coder Plus released this time is a proprietary version of Alibaba's open source Qwen3 Coder 480B A35B.As a powerful coding agent model, it excels at autonomous programming through tool calls and environment interactions, combining coding capabilities with a variety of general capabilities.
Technical highlights:
* Joint training with Qwen Code and Claude Code systems significantly improves CLI application performance
* Faster reasoning speed and more efficient task execution * Improved code security, moving towards responsible AI
The HyperAI Hyperneural official website (hyper.ai) has launched a number of high-quality open-source model tutorials based on the Tongyi Qianwen team. Experience the one-click deployment tutorial link: https://hyper.ai/tutorials








