Command Palette
Search for a command to run...
David Baker's Team Announced a Major Update: RFantibody Enables the Development of Customized Antibodies for Specific Targets; VisualOverload Pushes the Boundaries of Visual Understanding, Driving New Breakthroughs in Complex Scene reasoning.

Antibodies are the mainstay of current protein therapeutics. Globally, more than 160 antibody drugs have been approved for marketing, and the market size is expected to reach US$445 billion in the next five years.However, the development of therapeutic antibodies still mainly relies on animal immunization or screening candidate molecules from large antibody libraries.These methods are not only time-consuming and labor-intensive, but also often make it difficult to accurately design new antibodies that match the specific epitopes on the target.
Based on this,David Baker's team released a new generation of antibody and nanoantibody design tools RFantibody, which was finely optimized based on RFdiffusion.Designed to provide researchers and biotech engineers with an efficient de novo design method, the tool uses deep learning to generate antibody structures (especially CDR regions), then uses ProteinMPNN to design sequences, and then uses RF2 (RoseTTAFold2) to verify that they fold into the expected structure.
As an efficient protein design tool, RFantibody is widely used in biomedical research, drug development, vaccine design and other fields, providing a new tool for biomedical research.
The HyperAI official website has launched the "RFantibody: Antibody and Nanobody Design Tool." Come and try it out!
Online use:https://go.hyper.ai/sO07A
From September 15th to September 19th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 7
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in September: 1
Visit the official website:hyper.ai
Selected public datasets
1. ConstructionSite Construction Site Image Dataset
ConstructionSite is a multimodal benchmark dataset for construction site scenarios, designed to evaluate and improve the image understanding and reasoning capabilities of vision-language models in construction safety environments. This dataset features complex scenes, diverse annotations, and is close to actual construction safety inspections. It is suitable for tasks such as image captioning, visual question answering, object detection, visual localization, and multimodal reasoning.
Direct use: https://go.hyper.ai/ZRy12
2. HTSC-2025 Atmospheric-Pressure High-Temperature Superconductor Benchmark Dataset
HTSC-2025 is a benchmark dataset for predicting the critical temperature of ambient-pressure high-temperature superconductors. It aims to provide standardized and comparable test samples for models, thereby promoting progress and validation of superconductor predictions. The dataset contains approximately 140 materials and is stored in JSON/Parquet format for easy processing.
Direct use: https://go.hyper.ai/G2bJB
3. VisualOverload scene image understanding dataset
VisualOverload is a dataset for evaluating scene image understanding, designed to test a model's ability to visually understand and reason about details in complex scenes without relying on external knowledge. The dataset contains 2,720 question-answer pairs consisting of high-resolution, public-domain paintings that often feature multiple characters, actions, subplots, and complex backgrounds.
Direct use: https://go.hyper.ai/Acce1

4. WebExplorer-QA Information Retrieval Question Answering Dataset
WebExplorer-QA is a dataset for information retrieval and web browsing tasks. It aims to improve model performance in complex multi-step reasoning and long-range web navigation by systematically generating challenging query-answer pairs. It is suitable for training and evaluating network agents or large language models for information search, multi-hop/complex contextual reasoning, long-context prompt processing, tool invocation, and web navigation.
Direct use:https://go.hyper.ai/I58Ry
5. AnonyRAG Classic Novel Question Answering Dataset
AnonyRAG is a question-answering dataset for entity anonymization tasks released by Tencent Youtu Lab, Monash University, and Hong Kong Polytechnic University. It aims to evaluate whether the Retrieval Augmented Generation (RAG) system relies on retrieval to obtain evidence when the entity is anonymized.
Direct use: https://go.hyper.ai/jzqD9
6. RxnBench Organic Chemistry Question Answering Dataset
RxnBench is a visual question-answering dataset for multimodal chemical reaction image understanding. It aims to evaluate the capabilities of visual language models on tasks such as chemical reaction image understanding, multimodal reasoning, and scientific question answering. The dataset contains 1,525 multiple-choice questions on organic chemical reaction understanding, available in both Chinese and English.
Direct use: https://go.hyper.ai/Utkdo
7. SceneSplat-7K indoor scene 3D rendering dataset
SceneSplat-7 is the largest and highest-quality 3D Gaussian Splats (3DGS) dataset of indoor scenes. It aims to advance the understanding and semantic reasoning capabilities of vision-language pre-trained models on real indoor 3D scenes.
Direct access: https://go.hyper.ai/HISAa
8. SSTQA Semi-structured Tabular Question Answering Dataset
SSTQA is a benchmark dataset for semi-structured table question answering tasks released by Shanghai Jiao Tong University in collaboration with Simon Fraser University, Tsinghua University, and other institutions. It aims to test the understanding and answering capabilities of large language models and table question answering systems when faced with complex layouts in real tables (such as merged cells, hierarchical headers, multi-level nesting, etc.).
Direct use: https://go.hyper.ai/JoZyB
9. OmniSpatial Panoramic Spatial Reasoning Benchmark Dataset
OmniSpatial is a comprehensive and challenging standardized benchmark dataset for panoramic spatial reasoning, designed to fill a gap in the evaluation of spatial understanding in vision-language models. It is suitable for training and evaluating the spatial reasoning capabilities of large multimodal models, particularly in applications such as intelligent navigation, augmented/virtual reality, and complex scene understanding.
Direct use: https://go.hyper.ai/a6ep8
10. Urban Issues Urban Issues Image Dataset
Urban Issues is a public image classification dataset designed to help automated and machine vision systems identify public infrastructure and environmental issues in urban environments. Images in this dataset are organized by category, with each image labeled with a single class and presented under diverse background, lighting, and viewing angle conditions.
Direct use: https://go.hyper.ai/2id2J

Selected Public Tutorials
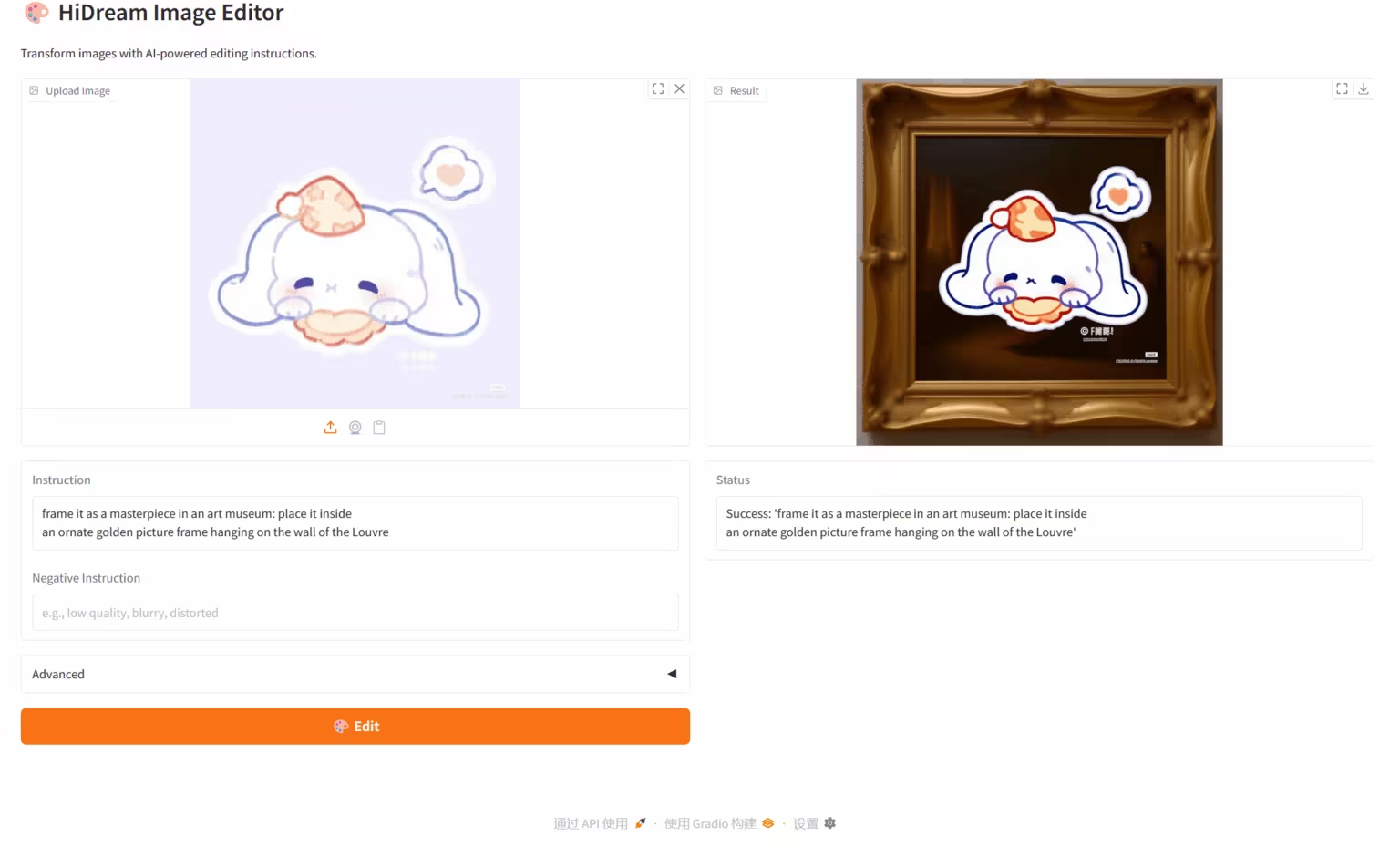
1. HiDream-E1.1: Command-based image editor
The HiDream-E1.1 model is an open-source image editing model released by Zhixiang Future. Based on its proprietary Sparse Diffusion Transformer architecture, it supports megapixel resolution and is licensed under the MIT open source license. This model implements "speak, change" natural language image editing capabilities. Users can perform complex tasks such as color adjustment, style transfer, and element addition and subtraction through simple language commands without requiring specialized software skills.
Run online: https://go.hyper.ai/P9C3R
2. RFantibody: Antibody and Nanobody Design Tool
RFdiffusion2 is a tool for antibody and nanobody design developed by David Baker's team. It aims to provide researchers and biotech engineers with an efficient de novo design approach. At its core, the tool leverages deep learning techniques to predict and design the three-dimensional structure and amino acid sequence of antibodies using structural information, enabling the development of customized antibodies targeting specific targets.
Run online: https://go.hyper.ai/sO07A
3. FastVLM: Extremely Fast Visual Language Model
FastVLM is a highly efficient visual language model (VLM) developed by the Apple team. It improves the efficiency and performance of high-resolution image processing. The model incorporates the new hybrid vision encoder FastViTHD, effectively reducing the number of visual tokens and significantly reducing encoding time.
Run online: https://go.hyper.ai/xg8wa
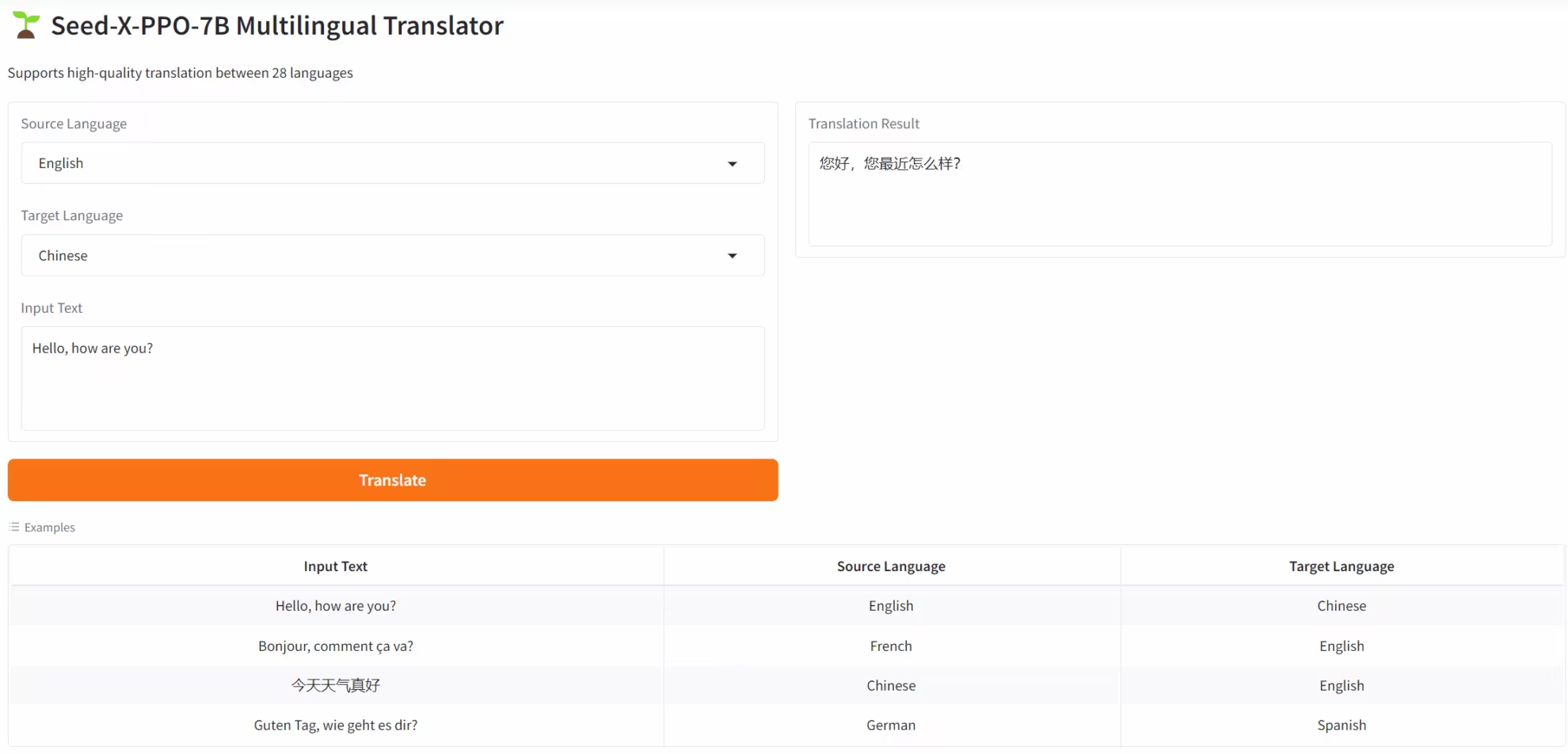
4. SEED-X-PPO-7B: Multilingual Translation Model Optimized by Reinforcement Learning
SEED-X-PPO-7B is a next-generation multilingual translation model released by the ByteDance Seed team. Based on iterative optimization using the Proximal Policy Optimization (PPO) reinforcement learning algorithm, its core goal is to address the need for high-precision semantic transfer in cross-language scenarios. This model overcomes the limitations of traditional translation models in adapting to minority languages, restoring cultural context, and ensuring coherence in long texts, supporting translation between 28 mainstream languages, including Chinese, English, and German.
Run online: https://go.hyper.ai/aw5oS
5. SRPO: Say goodbye to AI-style image generation!
SRPO is a text-to-image generation model jointly developed by the Tencent Hunyuan team, the School of Science at the Chinese University of Hong Kong, Shenzhen, and the Shenzhen International Graduate School of Tsinghua University. By designing the reward signal as a text-conditional signal, it enables online adjustment of the reward and reduces reliance on offline reward fine-tuning.
Run online: https://go.hyper.ai/8OQxS

6. ERNIE-4.5-21B-A3B-Thinking: Lightweight Model Reasoning Capabilities Upgraded
ERNIE-4.5-21B-A3B-Thinking is a lightweight "thinking version" of the inference model released by the Baidu Wenxin Yiyan team. This model uses a mixture of experts (MoE) architecture, has a total parameter size of 21B, and each token activates 3B parameters. It is trained through instruction fine-tuning and reinforcement learning.
Run online: https://go.hyper.ai/bQmlo
7. RFdiffusion2: Protein Design Tool
RFdiffusion2 is a deep learning protein design model released by the Institute for Protein Design at the University of Washington. This model not only generates enzyme scaffolds with customized active sites based on simple chemical reaction descriptions, but also significantly overcomes previous technical bottlenecks in catalyst design, providing strong technical support for important applications such as plastic degradation.
Run online: https://go.hyper.ai/9YInD
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling
This paper presents OmniWorld, a large-scale, multi-domain, and multi-modal dataset designed for modeling four-dimensional worlds. This dataset consists of the newly collected OmniWorld-Game dataset and several selected public datasets, covering a variety of application scenarios.
Paper link: https://go.hyper.ai/SbW2Y
2. WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
This paper proposes a novel dual-agent framework, WebWeaver, designed to emulate the human research process. The planning agent operates in a dynamic loop, iteratively interweaving evidence acquisition and outline refinement to produce a comprehensive, source-based, structured outline connected to an evidence memory. Subsequently, the writing agent executes a hierarchical retrieval and writing process, completing the report construction section by section.
Paper link: https://go.hyper.ai/lqMvM
3. Scaling Agents via Continual Pre-training
This paper proposes, for the first time, the integration of agent-continuous pre-training (Agentic CPT) into the training process of deep learning agents to build a robust agent-based model. Based on this approach, researchers developed a deep learning agent model called AgentFounder.
Paper link: https://go.hyper.ai/6lyWG
4. WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
This paper proposes a comprehensive post-training methodology, WebSailor, which generates novel high-uncertainty tasks through structured sampling and information fuzzification. It employs a RFT cold-start strategy and combines it with a highly efficient agent-based reinforcement learning training algorithm, Repeated Sampling Policy Optimization (DUPO). Through this integrated process, WebSailor significantly outperforms all existing open-source agents in complex information retrieval tasks, approaching the performance of proprietary agents and effectively narrowing the capability gap.
Paper link: https://go.hyper.ai/biWLb
5. Hala Technical Report: Building Arabic-Centric Instruction & Translation Models at Scale
This paper presents Hala, a family of instruction and translation models centered on Arabic. Built on a proprietary translation-fine-tuning pipeline, Hala achieves state-of-the-art performance in both the "nano" (≤2 billion parameters) and "small" (7 billion–9 billion parameters) categories on core Arabic benchmarks, significantly outperforming its baseline model.
Paper link: https://go.hyper.ai/KI73S
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
Research teams from the Chinese Academy of Sciences, Northeast Agricultural University, University of Macau and Jilin University jointly proposed a new twin clustering framework scSiameseClu for interpreting single-cell RNA-seq data. It can effectively alleviate the problem of representation collapse, achieve clearer cell population classification, and provide a powerful tool for the analysis of scRNA-seq data.
View the full report: https://go.hyper.ai/hyDFA
In September 2025, the Tencent Hunyuan team released the lightweight translation model Hunyuan-MT-7B, which supports translation between 33 languages and five ethnic Chinese languages/dialects. With only 7 billion parameters, it achieves efficient and accurate translation. In the Association for Computational Linguistics (ACL) WMT2025 competition, this model won first place in 30 of the 31 language categories, achieving impressive performance.
View the full report: https://go.hyper.ai/y2X2L
In recent years, the frequency and intensity of extreme rainfall in Mumbai have increased significantly. Traditional global forecasting systems, due to insufficient resolution, struggle to capture local weather patterns. To address this, the Indian Institute of Technology (IIT) Bombay, in collaboration with the University of Maryland, developed a prediction model based on convolutional neural networks and transfer learning, enabling early forecasting of extreme rainfall events.
View the full report: https://go.hyper.ai/wYsSk
The DeepSeek-R1 research results were featured on the cover of Nature, sparking heated discussion in the global academic community. The significance of this publication in Nature lies in its peer-review by this prestigious journal.
View the full report: https://go.hyper.ai/B12hL
Google DeepMind, in collaboration with researchers from New York University, Stanford University, Brown University and other institutions, based on a machine learning framework and a high-precision Gauss-Newton optimizer, systematically discovered new unstable singularities in three different fluid equations for the first time, and revealed a simple empirical asymptotic formula that links the blowup rate to the instability order.
View the full report: https://go.hyper.ai/hq5og
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1800+ public datasets
* Includes 600+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey: