Command Palette
Search for a command to run...
270M Lightweight Model! Gemma-3-270M-IT Focuses on Lightweight Long Text Interaction; the First Choice for cross-platform GUI Agents! AgentNet Covers 200+ Websites

As the scale of large model parameters continues to increase, users' demands for AI usage are gradually diverging: on the one hand, they need high-performance models to handle complex tasks, and on the other hand, they are eager to obtain a lightweight and practical conversation experience in a low-computing environment. In long text conversations and daily task scenarios,Traditional large models not only require high computing power support, but are also prone to response delays, context loss, or incoherent generation problems, making lightweight models that are "usable, easy to use, and run well" a pain point that urgently needs to be addressed.
Based on this, Google launched the lightweight instruction fine-tuning model Gemma-3-270M-IT.It has only 270 million parameters, but it can run smoothly in a single-card 1GB video memory environment, significantly lowering the threshold for local deployment.It also supports a 32K token context window, making it capable of handling long text conversations and document processing. Through specialized fine-tuning for everyday question-and-answer sessions and simple tasks, the Gemma-3-270M-IT maintains lightweight and efficient operation while also balancing the practicality of conversational interaction.
Gemma-3-270M-IT shows another development path: in addition to the trend of "bigger and stronger",Through lightweight and long context support, it provides new possibilities for edge deployment and inclusive applications.
The HyperAI Hyperneuron official website has launched the "vLLM + Open WebUI deployment gemma-3-270m-it" feature. Come and try it out!
Online use:https://go.hyper.ai/kBjw3
From August 25th to August 29th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 12
* High-quality tutorial selection: 4
* This week's recommended papers: 5
* Community article interpretation: 6 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in September: 5
Visit the official website:hyper.ai
Selected public datasets
1. Nemotron-Post-Training-Dataset-v2 Post-training dataset
Nemotron-Post-Training-Dataset-v2 is an expansion of NVIDIA's existing post-training corpus. This dataset expands SFT and RL data to five target languages (Spanish, French, German, Italian, and Japanese), covering scenarios such as mathematics, coding, STEM (science, technology, engineering, and mathematics), and conversation.
Direct use: https://go.hyper.ai/lSIjR
2. Nemotron-CC-v2 Pre-training Dataset
Nemotron-CC-v2 adds eight Common Crawl snapshots from 2024-2025 to the original English web page corpus, and performs global deduplication and English filtering. It also uses Qwen3-30B-A3B to synthesize and restate web page content, supplemented with diversified questions and answers, and further translated into 15 languages to strengthen multilingual logical reasoning and general knowledge pre-training.
Direct use: https://go.hyper.ai/xRtbR
3.Nemotron-Pretraining-Dataset-sample sampling dataset
Nemotron-Pretraining-Dataset-sample contains 10 representative subsets selected from different components of the complete SFT and pretraining corpus, covering high-quality question-answering data, mathematically focused extracts, code metadata, and SFT-style instruction data, suitable for review and quick experiments.
Direct use: https://go.hyper.ai/xzwY5
4. Nemotron-Pretraining-Code-v1 code dataset
Nemotron-Pretraining-Code-v1 is a large-scale, curated code dataset built on GitHub. This dataset has been filtered through multi-stage deduplication, license enforcement, and heuristic quality checks, and contains LLM-generated code question-answer pairs in 11 programming languages.
Direct use: https://go.hyper.ai/DRWAw
5. Nemotron-Pretraining-SFT-v1 supervised fine-tuning dataset
Nemotron-Pretraining-SFT-v1 is designed for STEM, academic, logical reasoning, and multilingual scenarios. It is generated from high-quality mathematical and scientific materials and combines graduate-level academic texts with pre-trained SFT data to construct complex multiple-choice and analytical questions (with complete answers/thoughts), covering a variety of tasks including mathematics, coding, general knowledge, and logical reasoning.
Direct use: https://go.hyper.ai/g568w
6. Nemotron-CC-Math Mathematics Pre-training Dataset
Nemotron-CC-Math is a high-quality, large-scale pre-trained dataset focused on mathematics. Containing 133 billion tokens, the dataset preserves the structure of equations and code while unifying the mathematical content into an editable LaTeX format. This is the first dataset to reliably cover a wide range of mathematical formats (including the long tail) at web scale.
Direct use: https://go.hyper.ai/aEGc4
7. Echo-4o-Image synthetic image generation dataset
The Echo-4o-Image dataset, generated by GPT-4o, contains approximately 179,000 examples across three different task types: complex instruction execution (approximately 68,000 examples); hyperrealistic fantasy generation (approximately 38,000 examples); and multi-reference image generation (approximately 73,000 examples). Each example consists of a 2×2 image grid with a resolution of 1024×1024, containing structured information about the image path, features (attributes/subjects), and the generated prompt.
Direct use: https://go.hyper.ai/uLJEh

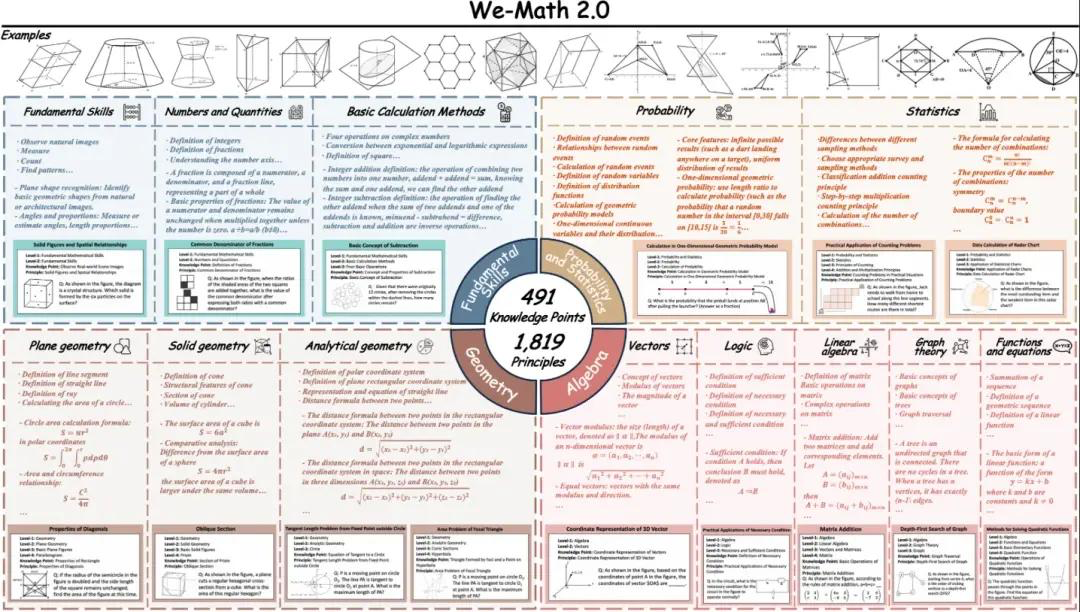
8. We-Math2.0-Standard Visual Mathematical Reasoning Benchmark Dataset
We-Math2.0-Standard establishes a unified labeling space around 1,819 precisely defined principles. Each problem is explicitly labeled with the principle and rigorously curated, achieving broad and balanced coverage overall, particularly enhancing previously underrepresented mathematical subfields and problem types. The dataset utilizes a dual expansion design: multiple figures per problem and multiple questions per figure.
Direct use: https://go.hyper.ai/VlqK1
9. AgentNet Desktop Operation Task Dataset
AgentNet is the first large-scale desktop computer usage agent trajectory dataset, designed to support and evaluate cross-platform GUI manipulation agents and vision-language-action models. The dataset contains 22.6K manually annotated computer usage task trajectories across Windows, macOS, and Ubuntu, and over 200 applications and websites. The scenarios fall into four categories: office, professional, daily life, and system usage.
Direct use: https://go.hyper.ai/3DGDs
10. WideSearch Information Gathering Benchmark Dataset
WideSearch is the first benchmark dataset specifically designed for wide-area information collection. The benchmark consists of 200 high-quality questions (100 in English and 100 in Chinese) carefully selected and hand-cleaned from real user queries. These questions come from over 15 different domains.
Direct use: https://go.hyper.ai/36kKj
11. MCD Multimodal Code Generation Dataset
MCD contains approximately 598,000 high-quality examples/pairs, organized in a command-following format. It covers a variety of input modalities (text, images, code) and output modalities (code, answers, explanations), making it suitable for multimodal code comprehension and generation tasks. The data includes: enhanced HTML code, charts, questions and answers, and algorithms.
Direct use: https://go.hyper.ai/yMPeD
12. Llama-Nemotron-Post-Training-Dataset Post-training dataset
The Llama-Nemotron Post-Training Dataset is a large-scale post-training dataset designed to improve the math, code, general reasoning, and instruction following capabilities of the Llama-Nemotron family of models during post-training phases (e.g., SFT and RL). This dataset combines data from both supervised fine-tuning and reinforcement learning phases.
Direct use: https://go.hyper.ai/Vk0Pk
Selected Public Tutorials
1. Microsoft VibeVoice-1.5B redefines TTS technologyboundary
VibeVoice-1.5B is a new text-to-speech (TTS) model that generates expressive, long-form, multi-speaker conversational audio, such as podcasts. VibeVoice efficiently processes long audio sequences while maintaining high fidelity and supports synthesizing up to 90 minutes of speech with up to four different speakers.
Online operation:https://go.hyper.ai/Ofjb1
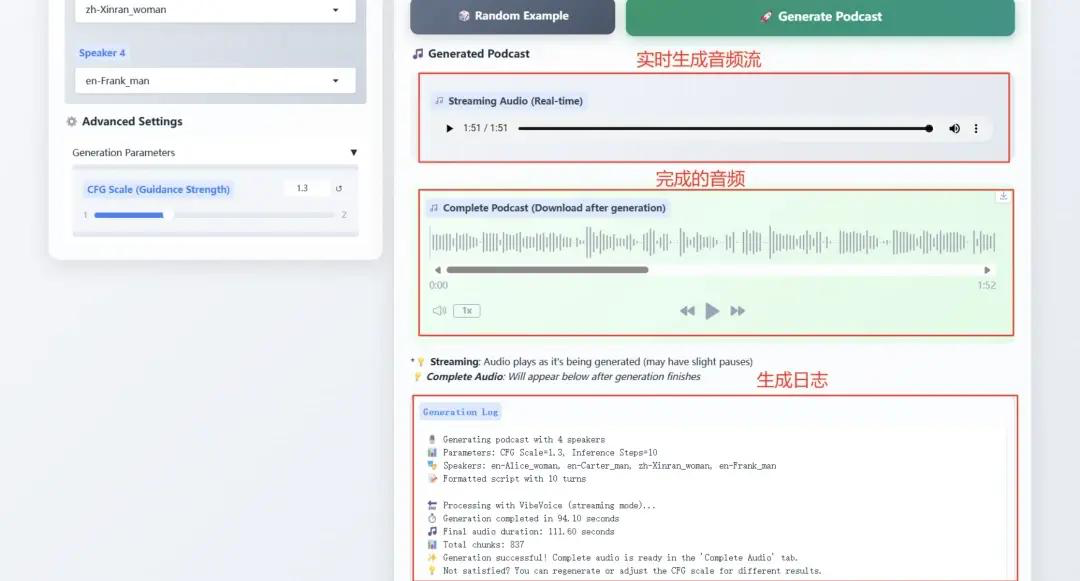
2. vLLM + Open WebUI deploy NVIDIA-Nemotron-Nano-9B-v2
NVIDIA-Nemotron-Nano-9B-v2 innovatively combines Mamba's efficient long sequence processing and Transformer's strong semantic modeling capabilities, achieving 128K ultra-long context support with only 9 billion (9B) parameters. Its inference efficiency and task performance on edge computing devices (such as RTX 4090-class GPUs) are comparable to cutting-edge models with the same parameter scale.
Run online: https://go.hyper.ai/cVzPp
3. vLLM + Open WebUI deployment gemma-3-270m-it
gemma-3-270m-it is built with 270M (270 million) parameters, focusing on efficient conversational interaction and lightweight deployment. This lightweight and efficient model requires only 1GB+ of graphics memory on a single graphics card, making it suitable for edge devices and low-resource scenarios. The model supports multi-turn conversations and is specifically fine-tuned for everyday Q&A and simple task instructions. It focuses on text generation and comprehension, and supports a context window of 32k tokens, enabling it to handle long text conversations.
Run online: https://go.hyper.ai/kBjw3

4. vLLM+Open WebUI Deployment Seed-OSS-36B-Instruct
Seed-OSS-36B-Instruct used 12 trillion (12 terabytes) of tokens for training and achieved outstanding performance on multiple mainstream open-source benchmarks. One of its most representative features is its native long-context capability, with a maximum context length of 512k tokens, enabling it to handle extremely long documents and reasoning chains without sacrificing performance. This length is twice that of OpenAI's latest GPT-5 model family and is equivalent to approximately 1,600 pages of text.
Run online: https://go.hyper.ai/aKw9w

💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR
This paper proposes a synthesis strategy for self-playing variational problems to improve verifiable reward reinforcement learning for large language models. While traditional RLVR improves Pass@1, it reduces generative diversity due to entropy collapse, limiting Pass@k performance. SvS mitigates entropy collapse and maintains training diversity by synthesizing equivalent variational problems based on correct solutions.
Paper link: https://go.hyper.ai/IU71P
2. Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
This paper proposes a novel learning paradigm for adaptive large language model agents that eliminates the need for fine-tuning the underlying LLM. Existing methods often suffer from two limitations: they are either too rigid or computationally expensive. The research team achieves low-cost continuous adaptation through memory-based online reinforcement learning. They formalize this process as a memory-enhanced Markov decision process (M-MDP) and introduce a neural case selection strategy to guide action decisions.
Paper link: https://go.hyper.ai/sl9Yj
3. TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
This paper proposes TreePO, a self-guided rollout algorithm that treats sequence generation as a tree-like search process. TreePO consists of a dynamic tree sampling strategy and fixed-length segment decoding, exploiting local uncertainty to generate additional branches. By amortizing computational overhead over common prefixes and pruning low-value paths early on, TreePO effectively reduces the computational burden of each update while maintaining or enhancing exploration diversity.
Paper link: https://go.hyper.ai/J8tKk
4. VibeVoice Technical Report
This paper proposes a novel speech synthesis model, VibeVoice, that generates long, multi-speaker speech based on next-token diffusion. Its continuous speech tokenizer achieves an 80x compression rate improvement over Encodec, significantly improving the efficiency of processing long sequences while maintaining sound quality. The model supports synthesizing up to 90 minutes of conversational speech for up to four speakers within a 64k context, authentically recreating the atmosphere of communication and surpassing existing open source and commercial models.
Paper link: https://go.hyper.ai/pokVi
5. CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
This paper presents CMPhysBench, a novel benchmark for evaluating the capabilities of large language models in condensed matter physics. CMPhysBench consists of over 520 carefully curated graduate-level problems covering representative subfields and fundamental theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, and strongly correlated systems.
Paper link: https://go.hyper.ai/uo8de
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
At the third "AI for Bioengineering Summer School" hosted by Shanghai Jiao Tong University, Li Mingchen, a postdoctoral fellow in Hong Liang's research group at the Institute of Natural Sciences of Shanghai Jiao Tong University, shared the latest research progress and technological breakthroughs in the basic model of proteins and genomes with everyone under the theme of "Protein and Genome Basic Model".
View the full report: https://go.hyper.ai/Ynjdj
Combining cheminformatics tools with the new organic solubility database, BigSolDB, the MIT research team improved upon the FASTPROP and CHEMPROP model architectures, enabling the model to simultaneously input solute and solvent molecules, as well as temperature parameters, for direct regression training on logS. In a rigorous solute extrapolation scenario, the optimized model achieved a 2–3x reduction in RMSE and a 50x increase in inference speed compared to the state-of-the-art model developed by Vermeire et al.
View the full report: https://go.hyper.ai/cj9RX
NVIDIA announced the official launch of the Jetson AGX Thor development kit, starting at $3,499. The production Thor T5000 module is now available for enterprise customers. Dubbed the "robot brain," Jetson AGX Thor aims to empower millions of robots in industries such as manufacturing, logistics, transportation, healthcare, agriculture, and retail.
View the full report: https://go.hyper.ai/1XLXn
A research team from the Department of Chemical Engineering and Applied Chemistry at the University of Toronto in Canada proposed a multimodal machine learning method that uses information available after the synthesis of MOFs: PXRD and the chemicals used in the synthesis, to identify MOFs with potential in areas different from the originally reported applications. This research accelerates the connection between the synthesis of MOFs and application scenarios.
View the full report: https://go.hyper.ai/cqX1t
At the 2025CCF National High Performance Computing Academic Conference, Researcher Zhang Zhengde, head of AI4S at the Computing Center of the Institute of High Energy Physics, systematically elaborated on the efficient and high-quality AI-Ready construction plan for data, based on the current status of scientific data from large-scale facilities, as well as the application of intelligent agents and multi-agent frameworks in data annotation and supply.
View the full report: https://go.hyper.ai/u7F9L
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:https://go.hyper.ai/wiki
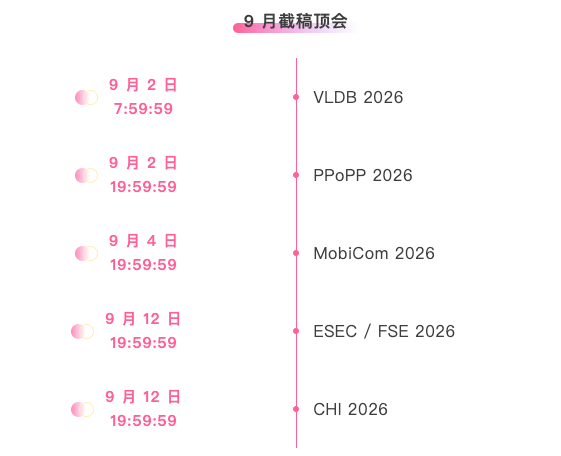
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








